 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeChangeQuery: Advancing Remote Sensing Change Analysis for Natural and Human-Induced Disasters from Visual Detection to Semantic Understanding
Apr 24, 2026Rapid situational awareness is critical in post-disaster response. While remote sensing damage assessment is evolving from pixel-level change detection to high-level semantic analysis, existing vision-language methodologies still struggle to provide actionable intelligence for complex strategic queries. They remain severely constrained by unimodal optical dependence, a prevailing bias towards natural disasters, and a fundamental lack of grounded interactivity. To address these limitations, we present ChangeQuery, a unified multimodal framework designed for comprehensive, all-weather disaster situation awareness. To overcome modality constraints and scenario biases, we construct the Disaster-Induced Change Query (DICQ) dataset, a large-scale benchmark coupling pre-event optical semantics with post-event SAR structural features across a balanced distribution of natural catastrophes and armed conflicts. Furthermore, to provide the high-quality supervision required for interactive reasoning, we propose a novel Automated Semantic Annotation Pipeline. Adhering to a ``statistics-first, generation-later'' paradigm, this engine automatically transforms raw segmentation masks into grounded, hierarchical instruction sets, effectively equipping the model with fine-grained spatial and quantitative awareness. Trained on this structured data, the ChangeQuery architecture operates as an interactive disaster analyst. It supports multi-task reasoning driven by diverse user queries, delivering precise damage quantification, region-specific descriptions, and holistic post-disaster summaries. Extensive experiments demonstrate that ChangeQuery establishes a new state-of-the-art, providing a robust and interpretable solution for complex disaster monitoring. The code is available at \href{https://sundongwei.github.io/changequery/}{https://sundongwei.github.io/changequery/}.
Mask Approximation Net: Merging Feature Extraction and Distribution Learning for Remote Sensing Change Captioning
Dec 26, 2024



Remote sensing image change description, as a novel multimodal task in the field of remote sensing processing, not only enables the detection of changes in surface conditions but also provides detailed descriptions of these changes, thereby enhancing human interpretability and interactivity. However, previous methods mainly employed Convolutional Neural Network (CNN) architectures to extract bitemporal image features. This approach often leads to an overemphasis on designing specific network architectures and limits the captured feature distributions to the current dataset, resulting in poor generalizability and robustness when applied to other datasets or real-world scenarios. To address these limitations, this paper proposes a novel approach for remote sensing image change detection and description that integrates diffusion models, aiming to shift the focus from conventional feature learning paradigms to data distribution learning. The proposed method primarily includes a simple multi-scale change detection module, whose output features are subsequently refined using a diffusion model. Additionally, we introduce a frequency-guided complex filter module to handle high-frequency noise during the diffusion process, which helps to maintain model performance. Finally, we validate the effectiveness of our proposed method on several remote sensing change detection description datasets, demonstrating its superior performance. The code available at MaskApproxNet.
MV-CC: Mask Enhanced Video Model for Remote Sensing Change Caption
Oct 31, 2024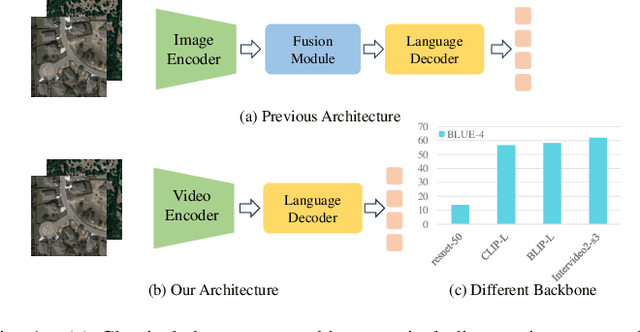

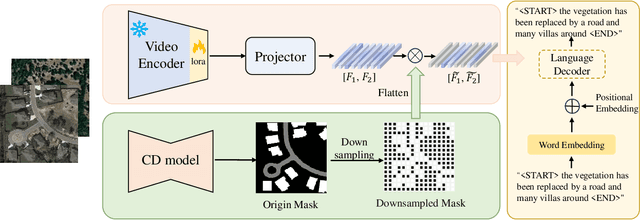
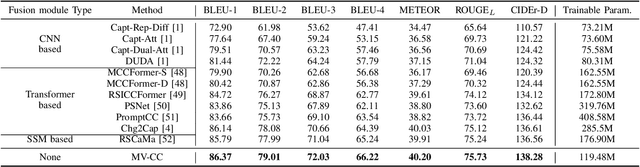
Remote sensing image change caption (RSICC) aims to provide natural language descriptions for bi-temporal remote sensing images. Since Change Caption (CC) task requires both spatial and temporal features, previous works follow an encoder-fusion-decoder architecture. They use an image encoder to extract spatial features and the fusion module to integrate spatial features and extract temporal features, which leads to increasingly complex manual design of the fusion module. In this paper, we introduce a novel video model-based paradigm without design of the fusion module and propose a Mask-enhanced Video model for Change Caption (MV-CC). Specifically, we use the off-the-shelf video encoder to simultaneously extract the temporal and spatial features of bi-temporal images. Furthermore, the types of changes in the CC are set based on specific task requirements, and to enable the model to better focus on the regions of interest, we employ masks obtained from the Change Detection (CD) method to explicitly guide the CC model. Experimental results demonstrate that our proposed method can obtain better performance compared with other state-of-the-art RSICC methods. The code is available at https://github.com/liuruixun/MV-CC.
A Lightweight Transformer for Remote Sensing Image Change Captioning
May 10, 2024Remote sensing image change captioning (RSICC) aims to automatically generate sentences that describe content differences in remote sensing bitemporal images. Recently, attention-based transformers have become a prevalent idea for capturing the features of global change. However, existing transformer-based RSICC methods face challenges, e.g., high parameters and high computational complexity caused by the self-attention operation in the transformer encoder component. To alleviate these issues, this paper proposes a Sparse Focus Transformer (SFT) for the RSICC task. Specifically, the SFT network consists of three main components, i.e. a high-level features extractor based on a convolutional neural network (CNN), a sparse focus attention mechanism-based transformer encoder network designed to locate and capture changing regions in dual-temporal images, and a description decoder that embeds images and words to generate sentences for captioning differences. The proposed SFT network can reduce the parameter number and computational complexity by incorporating a sparse attention mechanism within the transformer encoder network. Experimental results on various datasets demonstrate that even with a reduction of over 90\% in parameters and computational complexity for the transformer encoder, our proposed network can still obtain competitive performance compared to other state-of-the-art RSICC methods. The code can be available at
DPANET:Dual Pooling Attention Network for Semantic Segmentation
Oct 11, 2022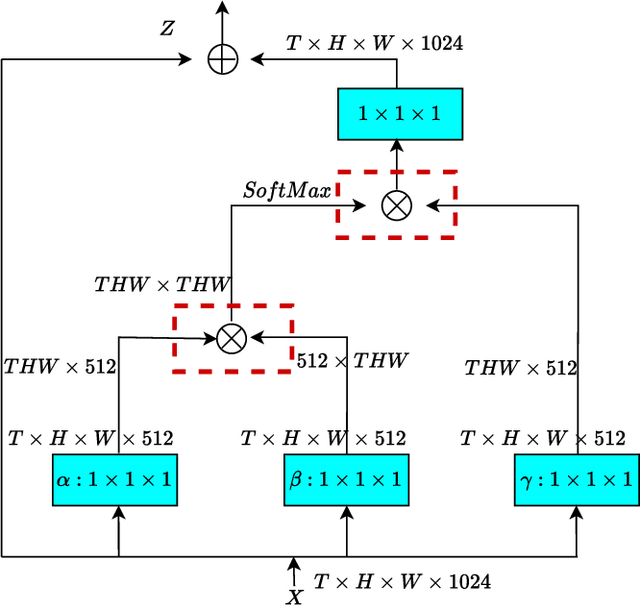
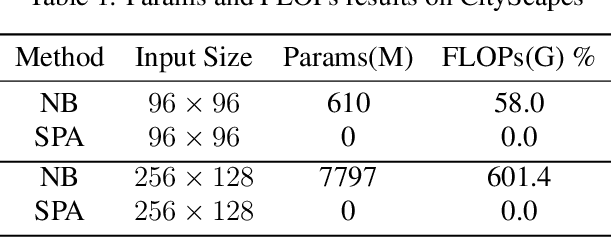
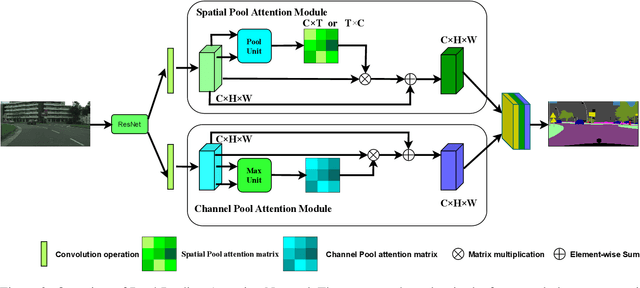

Image segmentation is a historic and significant computer vision task. With the help of deep learning techniques, image semantic segmentation has made great progresses. Over recent years, based on guidance of attention mechanism compared with CNN which overcomes the problems of lacking of interaction between different channels, and effective capturing and aggregating contextual information. However, the massive operations generated by the attention mechanism lead to its extremely high complexity and high demand for GPU memory. For this purpose, we propose a lightweight and flexible neural network named Dual Pool Attention Network(DPANet). The most important is that all modules in DPANet generate \textbf{0} parameters. The first component is spatial pool attention module, we formulate an easy and powerful method densely to extract contextual characteristics and reduce the amount of calculation and complexity dramatically.Meanwhile, it demonstrates the power of even and large kernel size. The second component is channel pool attention module. It is known that the computation process of CNN incorporates the information of spatial and channel dimensions. So, the aim of this module is stripping them out, in order to construct relationship of all channels and heighten different channels semantic information selectively. Moreover, we experiments on segmentation datasets, which shows our method simple and effective with low parameters and calculation complexity.