 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeShape-Adaptive Conditional Calibration for Conformal Prediction via Minimax Optimization
Mar 24, 2026Achieving valid conditional coverage in conformal prediction is challenging due to the theoretical difficulty of satisfying pointwise constraints in finite samples. Building upon the characterization of conditional coverage through marginal moment restrictions, we introduce Minimax Optimization Predictive Inference (MOPI), a framework that generalizes prior work by optimizing over a flexible class of set-valued mappings during the calibration phase, rather than simply calibrating a fixed sublevel set. This minimax formulation effectively circumvents the structural constraints of predefined score functions, achieving superior shape adaptivity while maintaining a principled connection to the minimization of mean squared coverage error. Theoretically, we provide non-asymptotic oracle inequalities and show that the convergence rate of the coverage error attains the optimal order under regular conditions. The MOPI also enables valid inference conditional on sensitive attributes that are available during calibration but unobserved at test time. Empirical results on complex, non-standard conditional distributions demonstrate that MOPI produces more efficient prediction sets than existing baselines.
SpatialVID: A Large-Scale Video Dataset with Spatial Annotations
Sep 11, 2025Significant progress has been made in spatial intelligence, spanning both spatial reconstruction and world exploration. However, the scalability and real-world fidelity of current models remain severely constrained by the scarcity of large-scale, high-quality training data. While several datasets provide camera pose information, they are typically limited in scale, diversity, and annotation richness, particularly for real-world dynamic scenes with ground-truth camera motion. To this end, we collect \textbf{SpatialVID}, a dataset consists of a large corpus of in-the-wild videos with diverse scenes, camera movements and dense 3D annotations such as per-frame camera poses, depth, and motion instructions. Specifically, we collect more than 21,000 hours of raw video, and process them into 2.7 million clips through a hierarchical filtering pipeline, totaling 7,089 hours of dynamic content. A subsequent annotation pipeline enriches these clips with detailed spatial and semantic information, including camera poses, depth maps, dynamic masks, structured captions, and serialized motion instructions. Analysis of SpatialVID's data statistics reveals a richness and diversity that directly foster improved model generalization and performance, establishing it as a key asset for the video and 3D vision research community.
Direct3D-S2: Gigascale 3D Generation Made Easy with Spatial Sparse Attention
May 26, 2025



Generating high-resolution 3D shapes using volumetric representations such as Signed Distance Functions (SDFs) presents substantial computational and memory challenges. We introduce Direct3D-S2, a scalable 3D generation framework based on sparse volumes that achieves superior output quality with dramatically reduced training costs. Our key innovation is the Spatial Sparse Attention (SSA) mechanism, which greatly enhances the efficiency of Diffusion Transformer (DiT) computations on sparse volumetric data. SSA allows the model to effectively process large token sets within sparse volumes, substantially reducing computational overhead and achieving a 3.9x speedup in the forward pass and a 9.6x speedup in the backward pass. Our framework also includes a variational autoencoder (VAE) that maintains a consistent sparse volumetric format across input, latent, and output stages. Compared to previous methods with heterogeneous representations in 3D VAE, this unified design significantly improves training efficiency and stability. Our model is trained on public available datasets, and experiments demonstrate that Direct3D-S2 not only surpasses state-of-the-art methods in generation quality and efficiency, but also enables training at 1024 resolution using only 8 GPUs, a task typically requiring at least 32 GPUs for volumetric representations at 256 resolution, thus making gigascale 3D generation both practical and accessible. Project page: https://www.neural4d.com/research/direct3d-s2.
Conformal Prediction with Cellwise Outliers: A Detect-then-Impute Approach
May 08, 2025
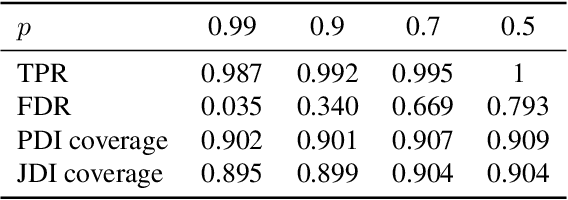
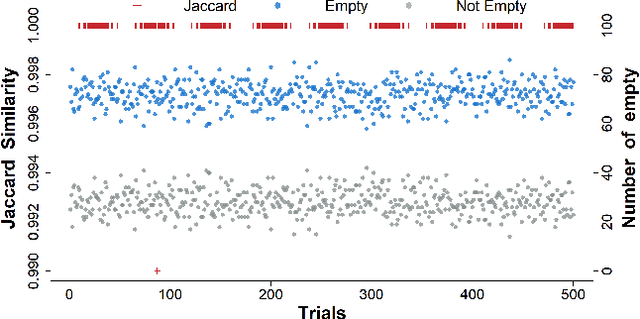

Conformal prediction is a powerful tool for constructing prediction intervals for black-box models, providing a finite sample coverage guarantee for exchangeable data. However, this exchangeability is compromised when some entries of the test feature are contaminated, such as in the case of cellwise outliers. To address this issue, this paper introduces a novel framework called detect-then-impute conformal prediction. This framework first employs an outlier detection procedure on the test feature and then utilizes an imputation method to fill in those cells identified as outliers. To quantify the uncertainty in the processed test feature, we adaptively apply the detection and imputation procedures to the calibration set, thereby constructing exchangeable features for the conformal prediction interval of the test label. We develop two practical algorithms, PDI-CP and JDI-CP, and provide a distribution-free coverage analysis under some commonly used detection and imputation procedures. Notably, JDI-CP achieves a finite sample $1-2\alpha$ coverage guarantee. Numerical experiments on both synthetic and real datasets demonstrate that our proposed algorithms exhibit robust coverage properties and comparable efficiency to the oracle baseline.
Error-quantified Conformal Inference for Time Series
Feb 02, 2025Uncertainty quantification in time series prediction is challenging due to the temporal dependence and distribution shift on sequential data. Conformal inference provides a pivotal and flexible instrument for assessing the uncertainty of machine learning models through prediction sets. Recently, a series of online conformal inference methods updated thresholds of prediction sets by performing online gradient descent on a sequence of quantile loss functions. A drawback of such methods is that they only use the information of revealed non-conformity scores via miscoverage indicators but ignore error quantification, namely the distance between the non-conformity score and the current threshold. To accurately leverage the dynamic of miscoverage error, we propose \textit{Error-quantified Conformal Inference} (ECI) by smoothing the quantile loss function. ECI introduces a continuous and adaptive feedback scale with the miscoverage error, rather than simple binary feedback in existing methods. We establish a long-term coverage guarantee for ECI under arbitrary dependence and distribution shift. The extensive experimental results show that ECI can achieve valid miscoverage control and output tighter prediction sets than other baselines.
A Lightweight Transformer for Remote Sensing Image Change Captioning
May 10, 2024Remote sensing image change captioning (RSICC) aims to automatically generate sentences that describe content differences in remote sensing bitemporal images. Recently, attention-based transformers have become a prevalent idea for capturing the features of global change. However, existing transformer-based RSICC methods face challenges, e.g., high parameters and high computational complexity caused by the self-attention operation in the transformer encoder component. To alleviate these issues, this paper proposes a Sparse Focus Transformer (SFT) for the RSICC task. Specifically, the SFT network consists of three main components, i.e. a high-level features extractor based on a convolutional neural network (CNN), a sparse focus attention mechanism-based transformer encoder network designed to locate and capture changing regions in dual-temporal images, and a description decoder that embeds images and words to generate sentences for captioning differences. The proposed SFT network can reduce the parameter number and computational complexity by incorporating a sparse attention mechanism within the transformer encoder network. Experimental results on various datasets demonstrate that even with a reduction of over 90\% in parameters and computational complexity for the transformer encoder, our proposed network can still obtain competitive performance compared to other state-of-the-art RSICC methods. The code can be available at
CAS: A General Algorithm for Online Selective Conformal Prediction with FCR Control
Mar 12, 2024We study the problem of post-selection predictive inference in an online fashion. To avoid devoting resources to unimportant units, a preliminary selection of the current individual before reporting its prediction interval is common and meaningful in online predictive tasks. Since the online selection causes a temporal multiplicity in the selected prediction intervals, it is important to control the real-time false coverage-statement rate (FCR) to measure the averaged miscoverage error. We develop a general framework named CAS (Calibration after Adaptive Selection) that can wrap around any prediction model and online selection rule to output post-selection prediction intervals. If the current individual is selected, we first perform an adaptive selection on historical data to construct a calibration set, then output a conformal prediction interval for the unobserved label. We provide tractable constructions for the calibration set for popular online selection rules. We proved that CAS can achieve an exact selection-conditional coverage guarantee in the finite-sample and distribution-free regimes. For the decision-driven selection rule, including most online multiple-testing procedures, CAS can exactly control the real-time FCR below the target level without any distributional assumptions. For the online selection with symmetric thresholds, we establish the error bound for the control gap of FCR under mild distributional assumptions. To account for the distribution shift in online data, we also embed CAS into some recent dynamic conformal prediction methods and examine the long-run FCR control. Numerical results on both synthetic and real data corroborate that CAS can effectively control FCR around the target level and yield more narrowed prediction intervals over existing baselines across various settings.
EPISODE: Episodic Gradient Clipping with Periodic Resampled Corrections for Federated Learning with Heterogeneous Data
Feb 14, 2023



Gradient clipping is an important technique for deep neural networks with exploding gradients, such as recurrent neural networks. Recent studies have shown that the loss functions of these networks do not satisfy the conventional smoothness condition, but instead satisfy a relaxed smoothness condition, i.e., the Lipschitz constant of the gradient scales linearly in terms of the gradient norm. Due to this observation, several gradient clipping algorithms have been developed for nonconvex and relaxed-smooth functions. However, the existing algorithms only apply to the single-machine or multiple-machine setting with homogeneous data across machines. It remains unclear how to design provably efficient gradient clipping algorithms in the general Federated Learning (FL) setting with heterogeneous data and limited communication rounds. In this paper, we design EPISODE, the very first algorithm to solve FL problems with heterogeneous data in the nonconvex and relaxed smoothness setting. The key ingredients of the algorithm are two new techniques called \textit{episodic gradient clipping} and \textit{periodic resampled corrections}. At the beginning of each round, EPISODE resamples stochastic gradients from each client and obtains the global averaged gradient, which is used to (1) determine whether to apply gradient clipping for the entire round and (2) construct local gradient corrections for each client. Notably, our algorithm and analysis provide a unified framework for both homogeneous and heterogeneous data under any noise level of the stochastic gradient, and it achieves state-of-the-art complexity results. In particular, we prove that EPISODE can achieve linear speedup in the number of machines, and it requires significantly fewer communication rounds. Experiments on several heterogeneous datasets show the superior performance of EPISODE over several strong baselines in FL.
An Information-Theoretic Approach to Transferability in Task Transfer Learning
Dec 20, 2022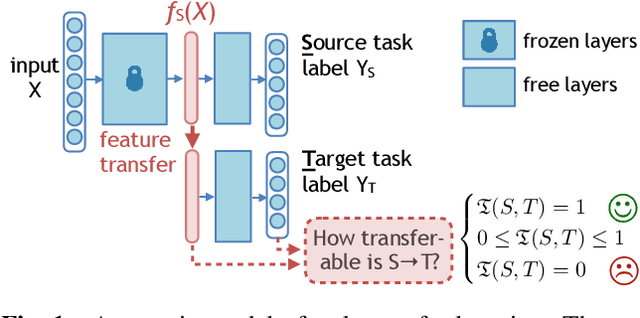
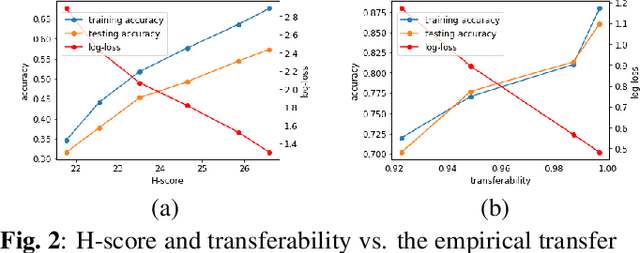
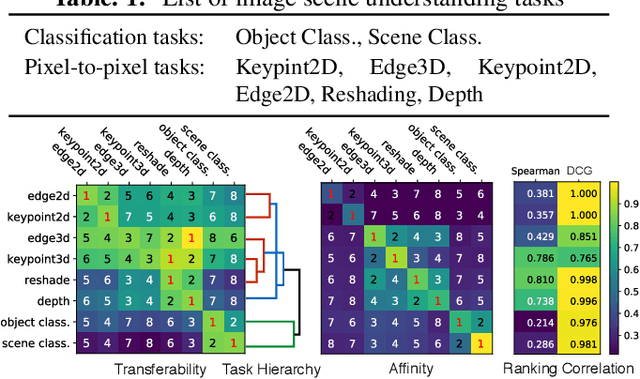
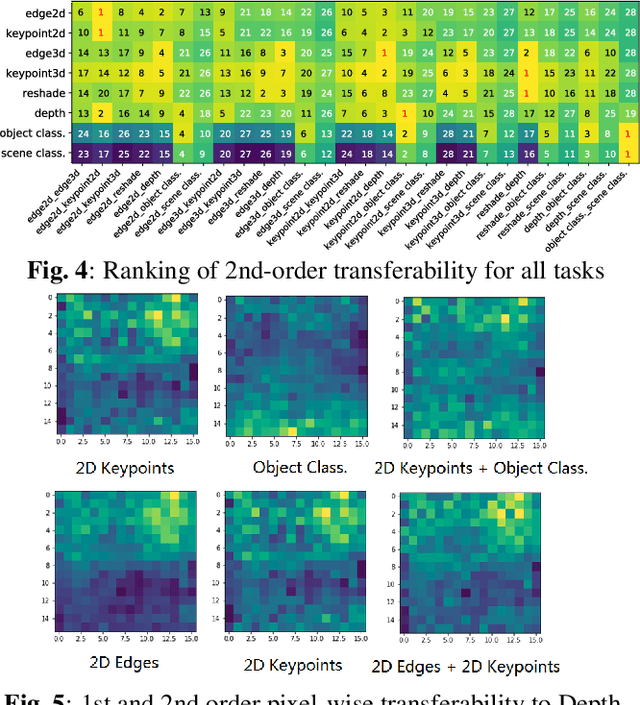
Task transfer learning is a popular technique in image processing applications that uses pre-trained models to reduce the supervision cost of related tasks. An important question is to determine task transferability, i.e. given a common input domain, estimating to what extent representations learned from a source task can help in learning a target task. Typically, transferability is either measured experimentally or inferred through task relatedness, which is often defined without a clear operational meaning. In this paper, we present a novel metric, H-score, an easily-computable evaluation function that estimates the performance of transferred representations from one task to another in classification problems using statistical and information theoretic principles. Experiments on real image data show that our metric is not only consistent with the empirical transferability measurement, but also useful to practitioners in applications such as source model selection and task transfer curriculum learning.
Fast Composite Optimization and Statistical Recovery in Federated Learning
Jul 17, 2022
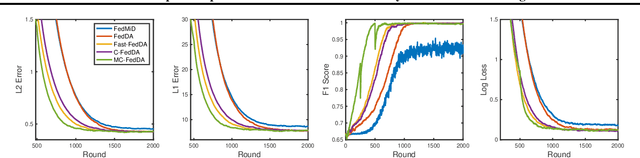
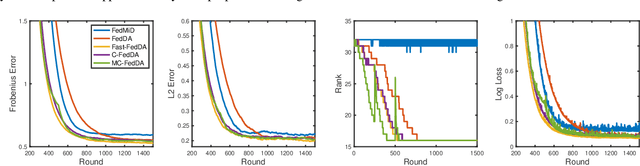
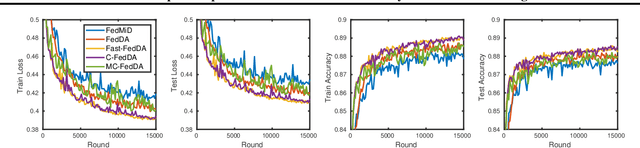
As a prevalent distributed learning paradigm, Federated Learning (FL) trains a global model on a massive amount of devices with infrequent communication. This paper investigates a class of composite optimization and statistical recovery problems in the FL setting, whose loss function consists of a data-dependent smooth loss and a non-smooth regularizer. Examples include sparse linear regression using Lasso, low-rank matrix recovery using nuclear norm regularization, etc. In the existing literature, federated composite optimization algorithms are designed only from an optimization perspective without any statistical guarantees. In addition, they do not consider commonly used (restricted) strong convexity in statistical recovery problems. We advance the frontiers of this problem from both optimization and statistical perspectives. From optimization upfront, we propose a new algorithm named \textit{Fast Federated Dual Averaging} for strongly convex and smooth loss and establish state-of-the-art iteration and communication complexity in the composite setting. In particular, we prove that it enjoys a fast rate, linear speedup, and reduced communication rounds. From statistical upfront, for restricted strongly convex and smooth loss, we design another algorithm, namely \textit{Multi-stage Federated Dual Averaging}, and prove a high probability complexity bound with linear speedup up to optimal statistical precision. Experiments in both synthetic and real data demonstrate that our methods perform better than other baselines. To the best of our knowledge, this is the first work providing fast optimization algorithms and statistical recovery guarantees for composite problems in FL.