 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeComGS: Efficient 3D Object-Scene Composition via Surface Octahedral Probes
Oct 09, 2025Gaussian Splatting (GS) enables immersive rendering, but realistic 3D object-scene composition remains challenging. Baked appearance and shadow information in GS radiance fields cause inconsistencies when combining objects and scenes. Addressing this requires relightable object reconstruction and scene lighting estimation. For relightable object reconstruction, existing Gaussian-based inverse rendering methods often rely on ray tracing, leading to low efficiency. We introduce Surface Octahedral Probes (SOPs), which store lighting and occlusion information and allow efficient 3D querying via interpolation, avoiding expensive ray tracing. SOPs provide at least a 2x speedup in reconstruction and enable real-time shadow computation in Gaussian scenes. For lighting estimation, existing Gaussian-based inverse rendering methods struggle to model intricate light transport and often fail in complex scenes, while learning-based methods predict lighting from a single image and are viewpoint-sensitive. We observe that 3D object-scene composition primarily concerns the object's appearance and nearby shadows. Thus, we simplify the challenging task of full scene lighting estimation by focusing on the environment lighting at the object's placement. Specifically, we capture a 360 degrees reconstructed radiance field of the scene at the location and fine-tune a diffusion model to complete the lighting. Building on these advances, we propose ComGS, a novel 3D object-scene composition framework. Our method achieves high-quality, real-time rendering at around 28 FPS, produces visually harmonious results with vivid shadows, and requires only 36 seconds for editing. Code and dataset are available at https://nju-3dv.github.io/projects/ComGS/.
Direct3D-S2: Gigascale 3D Generation Made Easy with Spatial Sparse Attention
May 26, 2025Generating high-resolution 3D shapes using volumetric representations such as Signed Distance Functions (SDFs) presents substantial computational and memory challenges. We introduce Direct3D-S2, a scalable 3D generation framework based on sparse volumes that achieves superior output quality with dramatically reduced training costs. Our key innovation is the Spatial Sparse Attention (SSA) mechanism, which greatly enhances the efficiency of Diffusion Transformer (DiT) computations on sparse volumetric data. SSA allows the model to effectively process large token sets within sparse volumes, substantially reducing computational overhead and achieving a 3.9x speedup in the forward pass and a 9.6x speedup in the backward pass. Our framework also includes a variational autoencoder (VAE) that maintains a consistent sparse volumetric format across input, latent, and output stages. Compared to previous methods with heterogeneous representations in 3D VAE, this unified design significantly improves training efficiency and stability. Our model is trained on public available datasets, and experiments demonstrate that Direct3D-S2 not only surpasses state-of-the-art methods in generation quality and efficiency, but also enables training at 1024 resolution using only 8 GPUs, a task typically requiring at least 32 GPUs for volumetric representations at 256 resolution, thus making gigascale 3D generation both practical and accessible. Project page: https://www.neural4d.com/research/direct3d-s2.
Direct3D: Scalable Image-to-3D Generation via 3D Latent Diffusion Transformer
May 23, 2024Generating high-quality 3D assets from text and images has long been challenging, primarily due to the absence of scalable 3D representations capable of capturing intricate geometry distributions. In this work, we introduce Direct3D, a native 3D generative model scalable to in-the-wild input images, without requiring a multiview diffusion model or SDS optimization. Our approach comprises two primary components: a Direct 3D Variational Auto-Encoder (D3D-VAE) and a Direct 3D Diffusion Transformer (D3D-DiT). D3D-VAE efficiently encodes high-resolution 3D shapes into a compact and continuous latent triplane space. Notably, our method directly supervises the decoded geometry using a semi-continuous surface sampling strategy, diverging from previous methods relying on rendered images as supervision signals. D3D-DiT models the distribution of encoded 3D latents and is specifically designed to fuse positional information from the three feature maps of the triplane latent, enabling a native 3D generative model scalable to large-scale 3D datasets. Additionally, we introduce an innovative image-to-3D generation pipeline incorporating semantic and pixel-level image conditions, allowing the model to produce 3D shapes consistent with the provided conditional image input. Extensive experiments demonstrate the superiority of our large-scale pre-trained Direct3D over previous image-to-3D approaches, achieving significantly better generation quality and generalization ability, thus establishing a new state-of-the-art for 3D content creation. Project page: https://nju-3dv.github.io/projects/Direct3D/.
STAG4D: Spatial-Temporal Anchored Generative 4D Gaussians
Mar 22, 2024
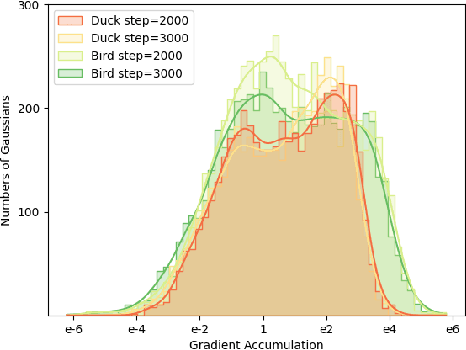

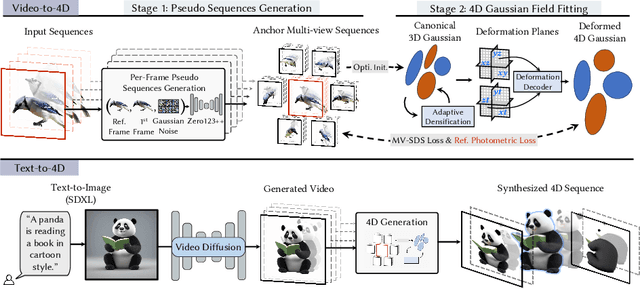
Recent progress in pre-trained diffusion models and 3D generation have spurred interest in 4D content creation. However, achieving high-fidelity 4D generation with spatial-temporal consistency remains a challenge. In this work, we propose STAG4D, a novel framework that combines pre-trained diffusion models with dynamic 3D Gaussian splatting for high-fidelity 4D generation. Drawing inspiration from 3D generation techniques, we utilize a multi-view diffusion model to initialize multi-view images anchoring on the input video frames, where the video can be either real-world captured or generated by a video diffusion model. To ensure the temporal consistency of the multi-view sequence initialization, we introduce a simple yet effective fusion strategy to leverage the first frame as a temporal anchor in the self-attention computation. With the almost consistent multi-view sequences, we then apply the score distillation sampling to optimize the 4D Gaussian point cloud. The 4D Gaussian spatting is specially crafted for the generation task, where an adaptive densification strategy is proposed to mitigate the unstable Gaussian gradient for robust optimization. Notably, the proposed pipeline does not require any pre-training or fine-tuning of diffusion networks, offering a more accessible and practical solution for the 4D generation task. Extensive experiments demonstrate that our method outperforms prior 4D generation works in rendering quality, spatial-temporal consistency, and generation robustness, setting a new state-of-the-art for 4D generation from diverse inputs, including text, image, and video.
AvatarBooth: High-Quality and Customizable 3D Human Avatar Generation
Jun 16, 2023



We introduce AvatarBooth, a novel method for generating high-quality 3D avatars using text prompts or specific images. Unlike previous approaches that can only synthesize avatars based on simple text descriptions, our method enables the creation of personalized avatars from casually captured face or body images, while still supporting text-based model generation and editing. Our key contribution is the precise avatar generation control by using dual fine-tuned diffusion models separately for the human face and body. This enables us to capture intricate details of facial appearance, clothing, and accessories, resulting in highly realistic avatar generations. Furthermore, we introduce pose-consistent constraint to the optimization process to enhance the multi-view consistency of synthesized head images from the diffusion model and thus eliminate interference from uncontrolled human poses. In addition, we present a multi-resolution rendering strategy that facilitates coarse-to-fine supervision of 3D avatar generation, thereby enhancing the performance of the proposed system. The resulting avatar model can be further edited using additional text descriptions and driven by motion sequences. Experiments show that AvatarBooth outperforms previous text-to-3D methods in terms of rendering and geometric quality from either text prompts or specific images. Please check our project website at https://zeng-yifei.github.io/avatarbooth_page/.