 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFastGHA: Generalized Few-Shot 3D Gaussian Head Avatars with Real-Time Animation
Jan 20, 2026Despite recent progress in 3D Gaussian-based head avatar modeling, efficiently generating high fidelity avatars remains a challenge. Current methods typically rely on extensive multi-view capture setups or monocular videos with per-identity optimization during inference, limiting their scalability and ease of use on unseen subjects. To overcome these efficiency drawbacks, we propose \OURS, a feed-forward method to generate high-quality Gaussian head avatars from only a few input images while supporting real-time animation. Our approach directly learns a per-pixel Gaussian representation from the input images, and aggregates multi-view information using a transformer-based encoder that fuses image features from both DINOv3 and Stable Diffusion VAE. For real-time animation, we extend the explicit Gaussian representations with per-Gaussian features and introduce a lightweight MLP-based dynamic network to predict 3D Gaussian deformations from expression codes. Furthermore, to enhance geometric smoothness of the 3D head, we employ point maps from a pre-trained large reconstruction model as geometry supervision. Experiments show that our approach significantly outperforms existing methods in both rendering quality and inference efficiency, while supporting real-time dynamic avatar animation.
Joint Learning of Depth and Appearance for Portrait Image Animation
Jan 15, 20252D portrait animation has experienced significant advancements in recent years. Much research has utilized the prior knowledge embedded in large generative diffusion models to enhance high-quality image manipulation. However, most methods only focus on generating RGB images as output, and the co-generation of consistent visual plus 3D output remains largely under-explored. In our work, we propose to jointly learn the visual appearance and depth simultaneously in a diffusion-based portrait image generator. Our method embraces the end-to-end diffusion paradigm and introduces a new architecture suitable for learning this conditional joint distribution, consisting of a reference network and a channel-expanded diffusion backbone. Once trained, our framework can be efficiently adapted to various downstream applications, such as facial depth-to-image and image-to-depth generation, portrait relighting, and audio-driven talking head animation with consistent 3D output.
EmoTalk3D: High-Fidelity Free-View Synthesis of Emotional 3D Talking Head
Aug 01, 2024



We present a novel approach for synthesizing 3D talking heads with controllable emotion, featuring enhanced lip synchronization and rendering quality. Despite significant progress in the field, prior methods still suffer from multi-view consistency and a lack of emotional expressiveness. To address these issues, we collect EmoTalk3D dataset with calibrated multi-view videos, emotional annotations, and per-frame 3D geometry. By training on the EmoTalk3D dataset, we propose a \textit{`Speech-to-Geometry-to-Appearance'} mapping framework that first predicts faithful 3D geometry sequence from the audio features, then the appearance of a 3D talking head represented by 4D Gaussians is synthesized from the predicted geometry. The appearance is further disentangled into canonical and dynamic Gaussians, learned from multi-view videos, and fused to render free-view talking head animation. Moreover, our model enables controllable emotion in the generated talking heads and can be rendered in wide-range views. Our method exhibits improved rendering quality and stability in lip motion generation while capturing dynamic facial details such as wrinkles and subtle expressions. Experiments demonstrate the effectiveness of our approach in generating high-fidelity and emotion-controllable 3D talking heads. The code and EmoTalk3D dataset are released at https://nju-3dv.github.io/projects/EmoTalk3D.
VividTalk: One-Shot Audio-Driven Talking Head Generation Based on 3D Hybrid Prior
Dec 07, 2023Audio-driven talking head generation has drawn much attention in recent years, and many efforts have been made in lip-sync, expressive facial expressions, natural head pose generation, and high video quality. However, no model has yet led or tied on all these metrics due to the one-to-many mapping between audio and motion. In this paper, we propose VividTalk, a two-stage generic framework that supports generating high-visual quality talking head videos with all the above properties. Specifically, in the first stage, we map the audio to mesh by learning two motions, including non-rigid expression motion and rigid head motion. For expression motion, both blendshape and vertex are adopted as the intermediate representation to maximize the representation ability of the model. For natural head motion, a novel learnable head pose codebook with a two-phase training mechanism is proposed. In the second stage, we proposed a dual branch motion-vae and a generator to transform the meshes into dense motion and synthesize high-quality video frame-by-frame. Extensive experiments show that the proposed VividTalk can generate high-visual quality talking head videos with lip-sync and realistic enhanced by a large margin, and outperforms previous state-of-the-art works in objective and subjective comparisons.
AvatarBooth: High-Quality and Customizable 3D Human Avatar Generation
Jun 16, 2023



We introduce AvatarBooth, a novel method for generating high-quality 3D avatars using text prompts or specific images. Unlike previous approaches that can only synthesize avatars based on simple text descriptions, our method enables the creation of personalized avatars from casually captured face or body images, while still supporting text-based model generation and editing. Our key contribution is the precise avatar generation control by using dual fine-tuned diffusion models separately for the human face and body. This enables us to capture intricate details of facial appearance, clothing, and accessories, resulting in highly realistic avatar generations. Furthermore, we introduce pose-consistent constraint to the optimization process to enhance the multi-view consistency of synthesized head images from the diffusion model and thus eliminate interference from uncontrolled human poses. In addition, we present a multi-resolution rendering strategy that facilitates coarse-to-fine supervision of 3D avatar generation, thereby enhancing the performance of the proposed system. The resulting avatar model can be further edited using additional text descriptions and driven by motion sequences. Experiments show that AvatarBooth outperforms previous text-to-3D methods in terms of rendering and geometric quality from either text prompts or specific images. Please check our project website at https://zeng-yifei.github.io/avatarbooth_page/.
EAMM: One-Shot Emotional Talking Face via Audio-Based Emotion-Aware Motion Model
May 31, 2022
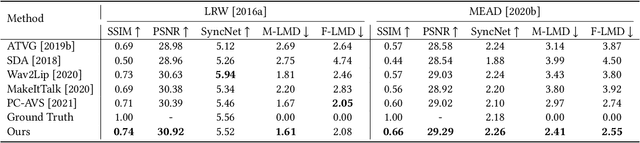
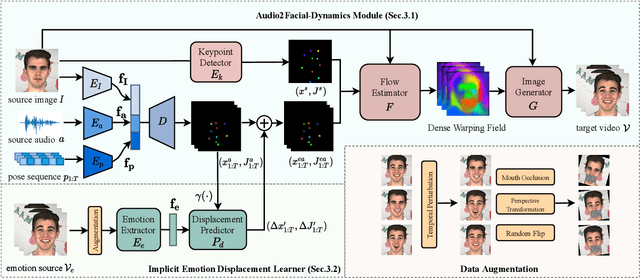

Although significant progress has been made to audio-driven talking face generation, existing methods either neglect facial emotion or cannot be applied to arbitrary subjects. In this paper, we propose the Emotion-Aware Motion Model (EAMM) to generate one-shot emotional talking faces by involving an emotion source video. Specifically, we first propose an Audio2Facial-Dynamics module, which renders talking faces from audio-driven unsupervised zero- and first-order key-points motion. Then through exploring the motion model's properties, we further propose an Implicit Emotion Displacement Learner to represent emotion-related facial dynamics as linearly additive displacements to the previously acquired motion representations. Comprehensive experiments demonstrate that by incorporating the results from both modules, our method can generate satisfactory talking face results on arbitrary subjects with realistic emotion patterns.
Audio-Driven Emotional Video Portraits
Apr 15, 2021


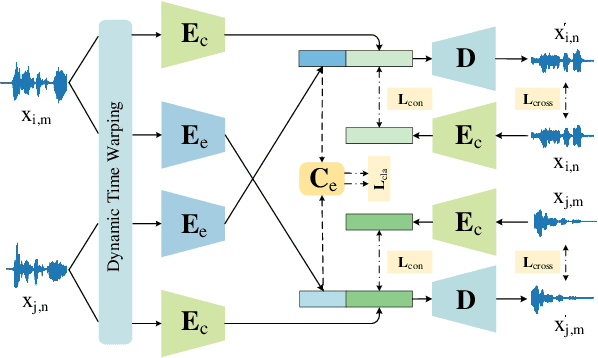
Despite previous success in generating audio-driven talking heads, most of the previous studies focus on the correlation between speech content and the mouth shape. Facial emotion, which is one of the most important features on natural human faces, is always neglected in their methods. In this work, we present Emotional Video Portraits (EVP), a system for synthesizing high-quality video portraits with vivid emotional dynamics driven by audios. Specifically, we propose the Cross-Reconstructed Emotion Disentanglement technique to decompose speech into two decoupled spaces, i.e., a duration-independent emotion space and a duration dependent content space. With the disentangled features, dynamic 2D emotional facial landmarks can be deduced. Then we propose the Target-Adaptive Face Synthesis technique to generate the final high-quality video portraits, by bridging the gap between the deduced landmarks and the natural head poses of target videos. Extensive experiments demonstrate the effectiveness of our method both qualitatively and quantitatively.