 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLatent Dynamics for Full Body Avatar Animation
May 20, 2026Pose-driven full-body avatars built on neural rendering produce high-quality novel views of a captured subject. Yet loose clothing and other dynamic elements deform in ways pose alone cannot explain: the same pose can correspond to many different states, because their motion depends on history, inertia, and contact. Explicit simulation and layered-garment methods can model such dynamics, but they require either a dedicated garment template, which raw multi-view capture does not naturally provide, or a test-time physics simulator with non-trivial runtime cost. A parallel line of work learns data-driven clothing avatars that avoid explicit garment layers. These methods add an auxiliary latent for variation beyond pose; at inference, they fix it, regress it from pose, or retrieve it from training data, without explicitly modeling how the latent evolves with its own dynamics. Additionally, even in everyday motion with loose clothing, existing architectures often struggle to capture fine-grained detail, producing blurry renderings and temporal artifacts. We augment a pose-conditioned 3D Gaussian avatar with a transformer-based decoder and a dynamics residual latent that captures temporal appearance and geometry variation beyond the driving signals. At inference, a learned latent dynamics model evolves the residual latent from a short pose history and the previous latent state. The model decomposes each update into driving, restoring, and dissipative forces, producing temporally coherent, history-dependent rollouts with negligible added cost. Different initial conditions yield diverse yet plausible motion trajectories, and the force decomposition exposes controls such as stiffness. Across nine captured sequences of everyday motion with diverse loose garments, quantitative metrics and a perceptual user study show improved animation quality over recent data-driven baselines.
HyperBones: Realtime Bone-driven Neural Garment Simulation with Hypernetwork Conditioning
May 19, 2026Recent advances in garment simulation have brought high-quality results closer to real-time performance. Physics-based simulators can produce accurate motion, but remain too computationally expensive for interactive applications. In contrast, linear blend skinning is efficient, but cannot capture the complex dynamics of loose-fitting garments, often leading to unrealistic motion and visual artifacts. Neural methods offer a promising alternative, yet they still struggle to animate loose clothing plausibly under strict runtime constraints. We present a fast and physically plausible approach for dynamic garment simulation. Our method trains a reduced-space neural dynamics simulator composed of independent coarse- and fine-level components. At the coarse level, the garment is driven by a set of virtual bones integrated with a lightweight neural network. Fine-scale wrinkle details are then recovered using a trained convolutional neural map. By decoupling identity-specific computation from real-time neural integration, our architecture maintains high performance while supporting diverse body shapes and motions. We further introduce an effective physics-supervision scheme that enables accurate results without relying on an external simulator. Experiments show that our method produces physically plausible garment dynamics, generalizes across a range of motions and body shapes, and supports a fixed set of garments. Our simulator runs at 300+ FPS on a commodity GPU, making it suitable for real-time applications.
Large-scale Codec Avatars: The Unreasonable Effectiveness of Large-scale Avatar Pretraining
Apr 02, 2026High-quality 3D avatar modeling faces a critical trade-off between fidelity and generalization. On the one hand, multi-view studio data enables high-fidelity modeling of humans with precise control over expressions and poses, but it struggles to generalize to real-world data due to limited scale and the domain gap between the studio environment and the real world. On the other hand, recent large-scale avatar models trained on millions of in-the-wild samples show promise for generalization across a wide range of identities, yet the resulting avatars are often of low-quality due to inherent 3D ambiguities. To address this, we present Large-Scale Codec Avatars (LCA), a high-fidelity, full-body 3D avatar model that generalizes to world-scale populations in a feedforward manner, enabling efficient inference. Inspired by the success of large language models and vision foundation models, we present, for the first time, a pre/post-training paradigm for 3D avatar modeling at scale: we pretrain on 1M in-the-wild videos to learn broad priors over appearance and geometry, then post-train on high-quality curated data to enhance expressivity and fidelity. LCA generalizes across hair styles, clothing, and demographics while providing precise, fine-grained facial expressions and finger-level articulation control, with strong identity preservation. Notably, we observe emergent generalization to relightability and loose garment support to unconstrained inputs, and zero-shot robustness to stylized imagery, despite the absence of direct supervision.
Joint Learning of Depth and Appearance for Portrait Image Animation
Jan 15, 20252D portrait animation has experienced significant advancements in recent years. Much research has utilized the prior knowledge embedded in large generative diffusion models to enhance high-quality image manipulation. However, most methods only focus on generating RGB images as output, and the co-generation of consistent visual plus 3D output remains largely under-explored. In our work, we propose to jointly learn the visual appearance and depth simultaneously in a diffusion-based portrait image generator. Our method embraces the end-to-end diffusion paradigm and introduces a new architecture suitable for learning this conditional joint distribution, consisting of a reference network and a channel-expanded diffusion backbone. Once trained, our framework can be efficiently adapted to various downstream applications, such as facial depth-to-image and image-to-depth generation, portrait relighting, and audio-driven talking head animation with consistent 3D output.
MonoHair: High-Fidelity Hair Modeling from a Monocular Video
Mar 27, 2024



Undoubtedly, high-fidelity 3D hair is crucial for achieving realism, artistic expression, and immersion in computer graphics. While existing 3D hair modeling methods have achieved impressive performance, the challenge of achieving high-quality hair reconstruction persists: they either require strict capture conditions, making practical applications difficult, or heavily rely on learned prior data, obscuring fine-grained details in images. To address these challenges, we propose MonoHair,a generic framework to achieve high-fidelity hair reconstruction from a monocular video, without specific requirements for environments. Our approach bifurcates the hair modeling process into two main stages: precise exterior reconstruction and interior structure inference. The exterior is meticulously crafted using our Patch-based Multi-View Optimization (PMVO). This method strategically collects and integrates hair information from multiple views, independent of prior data, to produce a high-fidelity exterior 3D line map. This map not only captures intricate details but also facilitates the inference of the hair's inner structure. For the interior, we employ a data-driven, multi-view 3D hair reconstruction method. This method utilizes 2D structural renderings derived from the reconstructed exterior, mirroring the synthetic 2D inputs used during training. This alignment effectively bridges the domain gap between our training data and real-world data, thereby enhancing the accuracy and reliability of our interior structure inference. Lastly, we generate a strand model and resolve the directional ambiguity by our hair growth algorithm. Our experiments demonstrate that our method exhibits robustness across diverse hairstyles and achieves state-of-the-art performance. For more results, please refer to our project page https://keyuwu-cs.github.io/MonoHair/.
Learning a Generalized Physical Face Model From Data
Feb 29, 2024



Physically-based simulation is a powerful approach for 3D facial animation as the resulting deformations are governed by physical constraints, allowing to easily resolve self-collisions, respond to external forces and perform realistic anatomy edits. Today's methods are data-driven, where the actuations for finite elements are inferred from captured skin geometry. Unfortunately, these approaches have not been widely adopted due to the complexity of initializing the material space and learning the deformation model for each character separately, which often requires a skilled artist followed by lengthy network training. In this work, we aim to make physics-based facial animation more accessible by proposing a generalized physical face model that we learn from a large 3D face dataset in a simulation-free manner. Once trained, our model can be quickly fit to any unseen identity and produce a ready-to-animate physical face model automatically. Fitting is as easy as providing a single 3D face scan, or even a single face image. After fitting, we offer intuitive animation controls, as well as the ability to retarget animations across characters. All the while, the resulting animations allow for physical effects like collision avoidance, gravity, paralysis, bone reshaping and more.
An Implicit Physical Face Model Driven by Expression and Style
Jan 27, 2024



3D facial animation is often produced by manipulating facial deformation models (or rigs), that are traditionally parameterized by expression controls. A key component that is usually overlooked is expression 'style', as in, how a particular expression is performed. Although it is common to define a semantic basis of expressions that characters can perform, most characters perform each expression in their own style. To date, style is usually entangled with the expression, and it is not possible to transfer the style of one character to another when considering facial animation. We present a new face model, based on a data-driven implicit neural physics model, that can be driven by both expression and style separately. At the core, we present a framework for learning implicit physics-based actuations for multiple subjects simultaneously, trained on a few arbitrary performance capture sequences from a small set of identities. Once trained, our method allows generalized physics-based facial animation for any of the trained identities, extending to unseen performances. Furthermore, it grants control over the animation style, enabling style transfer from one character to another or blending styles of different characters. Lastly, as a physics-based model, it is capable of synthesizing physical effects, such as collision handling, setting our method apart from conventional approaches.
Implicit Neural Representation for Physics-driven Actuated Soft Bodies
Jan 26, 2024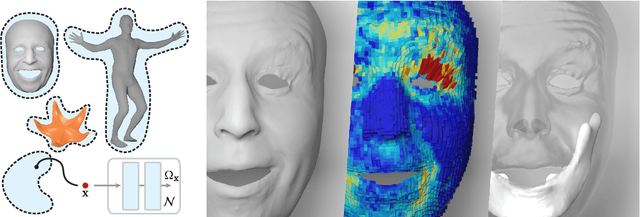

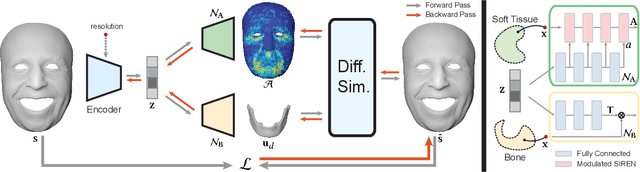
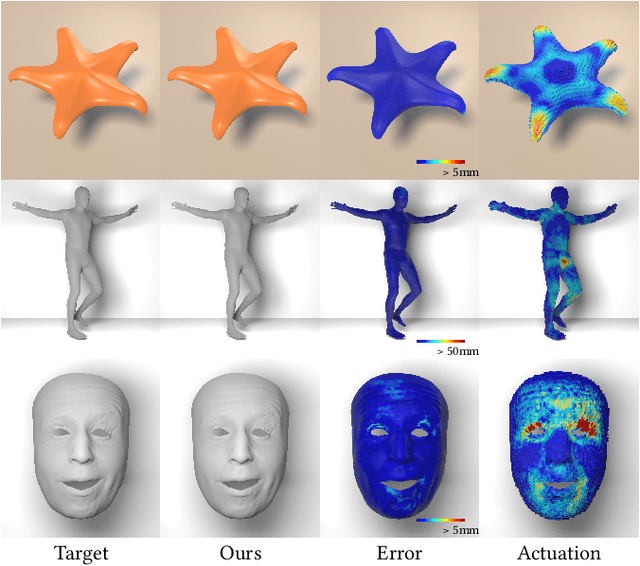
Active soft bodies can affect their shape through an internal actuation mechanism that induces a deformation. Similar to recent work, this paper utilizes a differentiable, quasi-static, and physics-based simulation layer to optimize for actuation signals parameterized by neural networks. Our key contribution is a general and implicit formulation to control active soft bodies by defining a function that enables a continuous mapping from a spatial point in the material space to the actuation value. This property allows us to capture the signal's dominant frequencies, making the method discretization agnostic and widely applicable. We extend our implicit model to mandible kinematics for the particular case of facial animation and show that we can reliably reproduce facial expressions captured with high-quality capture systems. We apply the method to volumetric soft bodies, human poses, and facial expressions, demonstrating artist-friendly properties, such as simple control over the latent space and resolution invariance at test time.
Efficient Incremental Potential Contact for Actuated Face Simulation
Dec 03, 2023


We present a quasi-static finite element simulator for human face animation. We model the face as an actuated soft body, which can be efficiently simulated using Projective Dynamics (PD). We adopt Incremental Potential Contact (IPC) to handle self-intersection. However, directly integrating IPC into the simulation would impede the high efficiency of the PD solver, since the stiffness matrix in the global step is no longer constant and cannot be pre-factorized. We notice that the actual number of vertices affected by the collision is only a small fraction of the whole model, and by utilizing this fact we effectively decrease the scale of the linear system to be solved. With the proposed optimization method for collision, we achieve high visual fidelity at a relatively low performance overhead.
NeuralHDHair: Automatic High-fidelity Hair Modeling from a Single Image Using Implicit Neural Representations
May 09, 2022

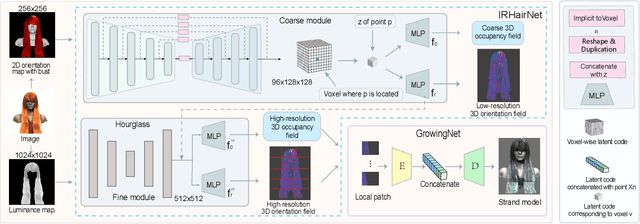

Undoubtedly, high-fidelity 3D hair plays an indispensable role in digital humans. However, existing monocular hair modeling methods are either tricky to deploy in digital systems (e.g., due to their dependence on complex user interactions or large databases) or can produce only a coarse geometry. In this paper, we introduce NeuralHDHair, a flexible, fully automatic system for modeling high-fidelity hair from a single image. The key enablers of our system are two carefully designed neural networks: an IRHairNet (Implicit representation for hair using neural network) for inferring high-fidelity 3D hair geometric features (3D orientation field and 3D occupancy field) hierarchically and a GrowingNet(Growing hair strands using neural network) to efficiently generate 3D hair strands in parallel. Specifically, we perform a coarse-to-fine manner and propose a novel voxel-aligned implicit function (VIFu) to represent the global hair feature, which is further enhanced by the local details extracted from a hair luminance map. To improve the efficiency of a traditional hair growth algorithm, we adopt a local neural implicit function to grow strands based on the estimated 3D hair geometric features. Extensive experiments show that our method is capable of constructing a high-fidelity 3D hair model from a single image, both efficiently and effectively, and achieves the-state-of-the-art performance.