 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInfoAtlas: A Foundation Model for Zero-Shot Statistical Dependence Estimate
May 29, 2026Measuring statistical dependency between high-dimensional random variables is a fundamental task in data science and machine learning. Neural mutual information (MI) estimators offer a promising avenue, but they typically require costly iterative optimization for each new dataset, making them impractical for real-time applications. We present InfoAtlas, a foundation model-like architecture that eliminates this bottleneck by directly inferring MI in a single forward pass. Pretrained on large-scale synthetic data with rich dependence patterns, InfoAtlas learns to identify diverse dependence structures and predict MI directly from the dataset. Comprehensive experiments demonstrate that InfoAtlas matches state-of-the-art neural estimators in accuracy while achieving $100\times$ speedup, can flexibly handle varying dimensions and sample sizes through a single unified model, and generalizes effectively to complex, real-world scenarios. By reformulating MI estimation as an inference task, InfoAtlas establishes a foundation for real-time dependency analysis.
EchoAvatar: Real-time Generative Avatar Animation from Audio Streams
May 27, 2026Real-time synthesis of high-fidelity 3D character motion from audio is a pivotal component for next-generation interactive avatars and virtual assistants. However, most existing approaches are limited to offline processing of complete audio sequences or are constrained to specific domains, rarely handling both speech and music effectively. In this paper, we introduce a novel framework designed to generate continuous, coherent full-body motion from streaming speech and music with low latency. Central to our approach is a unified streaming architecture capable of synthesizing continuous motion from incremental audio inputs. We employ a robust training strategy that enforces strong audio dependency, allowing the model to seamlessly generalize across conversational speech and rhythmic music without requiring explicit domain labels or mode switching. Additionally, we explored Reinforcement Learning to refine the quality of online generation. Furthermore, we bridge reactive animation with intent-driven behavior via a tool-call interface that allows upstream Large Language Models to inject explicit semantic control. By combining this controllability with stream audio-driven synthesis, our framework serves as a plug-and-play solution for transforming voice agents into interactive humanoid avatars. Extensive experiments demonstrate that our method outperforms state-of-the-art realtime baselines in motion quality and synchronization while maintaining the flexibility required for live deployment. Our code, pre-trained models, and videos are available at https://robinwitch.github.io/EchoAvatar-Page.
CamLit: Unified Video Diffusion with Explicit Camera and Lighting Control
Mar 15, 2026We present CamLit, the first unified video diffusion model that jointly performs novel view synthesis (NVS) and relighting from a single input image. Given one reference image, a user-defined camera trajectory, and an environment map, CamLit synthesizes a video of the scene from new viewpoints under the specified illumination. Within a single generative process, our model produces temporally coherent and spatially aligned outputs, including relit novel-view frames and corresponding albedo frames, enabling high-quality control of both camera pose and lighting. Qualitative and quantitative experiments demonstrate that CamLit achieves high-fidelity outputs on par with state-of-the-art methods in both novel view synthesis and relighting, without sacrificing visual quality in either task. We show that a single generative model can effectively integrate camera and lighting control, simplifying the video generation pipeline while maintaining competitive performance and consistent realism.
3DTeethSAM: Taming SAM2 for 3D Teeth Segmentation
Dec 12, 2025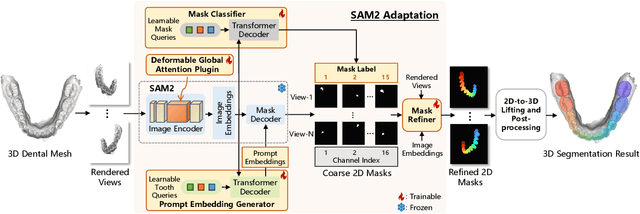
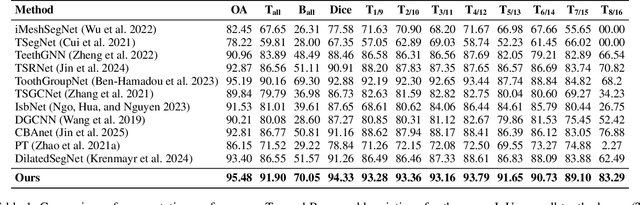
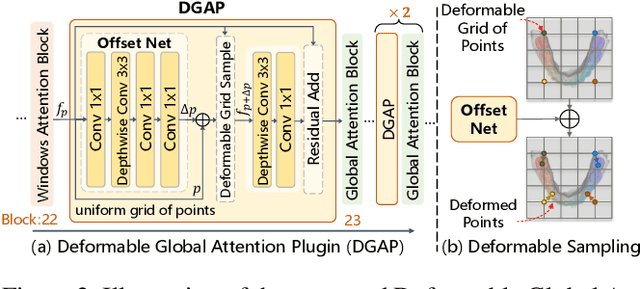
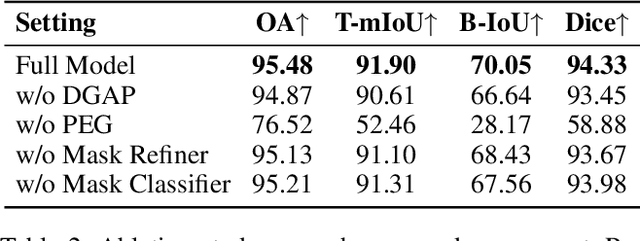
3D teeth segmentation, involving the localization of tooth instances and their semantic categorization in 3D dental models, is a critical yet challenging task in digital dentistry due to the complexity of real-world dentition. In this paper, we propose 3DTeethSAM, an adaptation of the Segment Anything Model 2 (SAM2) for 3D teeth segmentation. SAM2 is a pretrained foundation model for image and video segmentation, demonstrating a strong backbone in various downstream scenarios. To adapt SAM2 for 3D teeth data, we render images of 3D teeth models from predefined views, apply SAM2 for 2D segmentation, and reconstruct 3D results using 2D-3D projections. Since SAM2's performance depends on input prompts and its initial outputs often have deficiencies, and given its class-agnostic nature, we introduce three light-weight learnable modules: (1) a prompt embedding generator to derive prompt embeddings from image embeddings for accurate mask decoding, (2) a mask refiner to enhance SAM2's initial segmentation results, and (3) a mask classifier to categorize the generated masks. Additionally, we incorporate Deformable Global Attention Plugins (DGAP) into SAM2's image encoder. The DGAP enhances both the segmentation accuracy and the speed of the training process. Our method has been validated on the 3DTeethSeg benchmark, achieving an IoU of 91.90% on high-resolution 3D teeth meshes, establishing a new state-of-the-art in the field.
Detecting Dental Landmarks from Intraoral 3D Scans: the 3DTeethLand challenge
Dec 09, 2025Teeth landmark detection is a critical task in modern clinical orthodontics. Their precise identification enables advanced diagnostics, facilitates personalized treatment strategies, and supports more effective monitoring of treatment progress in clinical dentistry. However, several significant challenges may arise due to the intricate geometry of individual teeth and the substantial variations observed across different individuals. To address these complexities, the development of advanced techniques, especially through the application of deep learning, is essential for the precise and reliable detection of 3D tooth landmarks. In this context, the 3DTeethLand challenge was held in collaboration with the International Conference on Medical Image Computing and Computer-Assisted Intervention (MICCAI) in 2024, calling for algorithms focused on teeth landmark detection from intraoral 3D scans. This challenge introduced the first publicly available dataset for 3D teeth landmark detection, offering a valuable resource to assess the state-of-the-art methods in this task and encourage the community to provide methodological contributions towards the resolution of their problem with significant clinical implications.
Motion-example-controlled Co-speech Gesture Generation Leveraging Large Language Models
Jul 27, 2025The automatic generation of controllable co-speech gestures has recently gained growing attention. While existing systems typically achieve gesture control through predefined categorical labels or implicit pseudo-labels derived from motion examples, these approaches often compromise the rich details present in the original motion examples. We present MECo, a framework for motion-example-controlled co-speech gesture generation by leveraging large language models (LLMs). Our method capitalizes on LLMs' comprehension capabilities through fine-tuning to simultaneously interpret speech audio and motion examples, enabling the synthesis of gestures that preserve example-specific characteristics while maintaining speech congruence. Departing from conventional pseudo-labeling paradigms, we position motion examples as explicit query contexts within the prompt structure to guide gesture generation. Experimental results demonstrate state-of-the-art performance across three metrics: Fr\'echet Gesture Distance (FGD), motion diversity, and example-gesture similarity. Furthermore, our framework enables granular control of individual body parts and accommodates diverse input modalities including motion clips, static poses, human video sequences, and textual descriptions. Our code, pre-trained models, and videos are available at https://robinwitch.github.io/MECo-Page.
DiffLocks: Generating 3D Hair from a Single Image using Diffusion Models
May 09, 2025



We address the task of generating 3D hair geometry from a single image, which is challenging due to the diversity of hairstyles and the lack of paired image-to-3D hair data. Previous methods are primarily trained on synthetic data and cope with the limited amount of such data by using low-dimensional intermediate representations, such as guide strands and scalp-level embeddings, that require post-processing to decode, upsample, and add realism. These approaches fail to reconstruct detailed hair, struggle with curly hair, or are limited to handling only a few hairstyles. To overcome these limitations, we propose DiffLocks, a novel framework that enables detailed reconstruction of a wide variety of hairstyles directly from a single image. First, we address the lack of 3D hair data by automating the creation of the largest synthetic hair dataset to date, containing 40K hairstyles. Second, we leverage the synthetic hair dataset to learn an image-conditioned diffusion-transfomer model that generates accurate 3D strands from a single frontal image. By using a pretrained image backbone, our method generalizes to in-the-wild images despite being trained only on synthetic data. Our diffusion model predicts a scalp texture map in which any point in the map contains the latent code for an individual hair strand. These codes are directly decoded to 3D strands without post-processing techniques. Representing individual strands, instead of guide strands, enables the transformer to model the detailed spatial structure of complex hairstyles. With this, DiffLocks can recover highly curled hair, like afro hairstyles, from a single image for the first time. Data and code is available at https://radualexandru.github.io/difflocks/
RGBAvatar: Reduced Gaussian Blendshapes for Online Modeling of Head Avatars
Mar 17, 2025We present Reduced Gaussian Blendshapes Avatar (RGBAvatar), a method for reconstructing photorealistic, animatable head avatars at speeds sufficient for on-the-fly reconstruction. Unlike prior approaches that utilize linear bases from 3D morphable models (3DMM) to model Gaussian blendshapes, our method maps tracked 3DMM parameters into reduced blendshape weights with an MLP, leading to a compact set of blendshape bases. The learned compact base composition effectively captures essential facial details for specific individuals, and does not rely on the fixed base composition weights of 3DMM, leading to enhanced reconstruction quality and higher efficiency. To further expedite the reconstruction process, we develop a novel color initialization estimation method and a batch-parallel Gaussian rasterization process, achieving state-of-the-art quality with training throughput of about 630 images per second. Moreover, we propose a local-global sampling strategy that enables direct on-the-fly reconstruction, immediately reconstructing the model as video streams in real time while achieving quality comparable to offline settings. Our source code is available at https://github.com/gapszju/RGBAvatar.
InfoNorm: Mutual Information Shaping of Normals for Sparse-View Reconstruction
Jul 17, 2024



3D surface reconstruction from multi-view images is essential for scene understanding and interaction. However, complex indoor scenes pose challenges such as ambiguity due to limited observations. Recent implicit surface representations, such as Neural Radiance Fields (NeRFs) and signed distance functions (SDFs), employ various geometric priors to resolve the lack of observed information. Nevertheless, their performance heavily depends on the quality of the pre-trained geometry estimation models. To ease such dependence, we propose regularizing the geometric modeling by explicitly encouraging the mutual information among surface normals of highly correlated scene points. In this way, the geometry learning process is modulated by the second-order correlations from noisy (first-order) geometric priors, thus eliminating the bias due to poor generalization. Additionally, we introduce a simple yet effective scheme that utilizes semantic and geometric features to identify correlated points, enhancing their mutual information accordingly. The proposed technique can serve as a plugin for SDF-based neural surface representations. Our experiments demonstrate the effectiveness of the proposed in improving the surface reconstruction quality of major states of the arts. Our code is available at: \url{https://github.com/Muliphein/InfoNorm}.
SG-NeRF: Neural Surface Reconstruction with Scene Graph Optimization
Jul 17, 2024
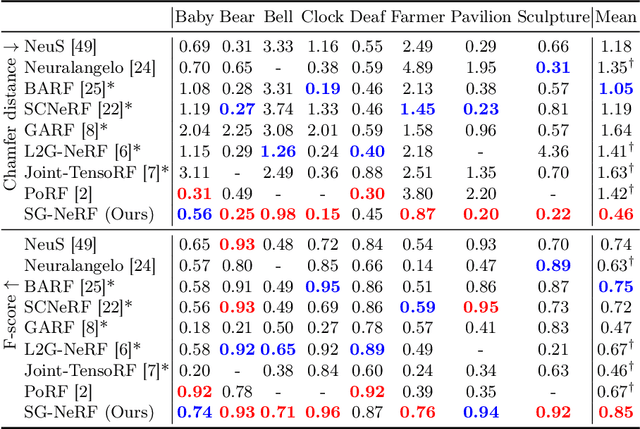


3D surface reconstruction from images is essential for numerous applications. Recently, Neural Radiance Fields (NeRFs) have emerged as a promising framework for 3D modeling. However, NeRFs require accurate camera poses as input, and existing methods struggle to handle significantly noisy pose estimates (i.e., outliers), which are commonly encountered in real-world scenarios. To tackle this challenge, we present a novel approach that optimizes radiance fields with scene graphs to mitigate the influence of outlier poses. Our method incorporates an adaptive inlier-outlier confidence estimation scheme based on scene graphs, emphasizing images of high compatibility with the neighborhood and consistency in the rendering quality. We also introduce an effective intersection-over-union (IoU) loss to optimize the camera pose and surface geometry, together with a coarse-to-fine strategy to facilitate the training. Furthermore, we propose a new dataset containing typical outlier poses for a detailed evaluation. Experimental results on various datasets consistently demonstrate the effectiveness and superiority of our method over existing approaches, showcasing its robustness in handling outliers and producing high-quality 3D reconstructions. Our code and data are available at: \url{https://github.com/Iris-cyy/SG-NeRF}.