 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDiffLocks: Generating 3D Hair from a Single Image using Diffusion Models
May 09, 2025



We address the task of generating 3D hair geometry from a single image, which is challenging due to the diversity of hairstyles and the lack of paired image-to-3D hair data. Previous methods are primarily trained on synthetic data and cope with the limited amount of such data by using low-dimensional intermediate representations, such as guide strands and scalp-level embeddings, that require post-processing to decode, upsample, and add realism. These approaches fail to reconstruct detailed hair, struggle with curly hair, or are limited to handling only a few hairstyles. To overcome these limitations, we propose DiffLocks, a novel framework that enables detailed reconstruction of a wide variety of hairstyles directly from a single image. First, we address the lack of 3D hair data by automating the creation of the largest synthetic hair dataset to date, containing 40K hairstyles. Second, we leverage the synthetic hair dataset to learn an image-conditioned diffusion-transfomer model that generates accurate 3D strands from a single frontal image. By using a pretrained image backbone, our method generalizes to in-the-wild images despite being trained only on synthetic data. Our diffusion model predicts a scalp texture map in which any point in the map contains the latent code for an individual hair strand. These codes are directly decoded to 3D strands without post-processing techniques. Representing individual strands, instead of guide strands, enables the transformer to model the detailed spatial structure of complex hairstyles. With this, DiffLocks can recover highly curled hair, like afro hairstyles, from a single image for the first time. Data and code is available at https://radualexandru.github.io/difflocks/
Field Robot for High-throughput and High-resolution 3D Plant Phenotyping
Nov 05, 2023With the need to feed a growing world population, the efficiency of crop production is of paramount importance. To support breeding and field management, various characteristics of the plant phenotype need to be measured -- a time-consuming process when performed manually. We present a robotic platform equipped with multiple laser and camera sensors for high-throughput, high-resolution in-field plant scanning. We create digital twins of the plants through 3D reconstruction. This allows the estimation of phenotypic traits such as leaf area, leaf angle, and plant height. We validate our system on a real field, where we reconstruct accurate point clouds and meshes of sugar beet, soybean, and maize.
HashSDF: Accurate Implicit Surfaces with Fast Local Features on Permutohedral Lattices
Nov 22, 2022Neural radiance-density field methods have become increasingly popular for the task of novel-view rendering. Their recent extension to hash-based positional encoding ensures fast training and inference with state-of-the-art results. However, density-based methods struggle with recovering accurate surface geometry. Hybrid methods alleviate this issue by optimizing the density based on an underlying SDF. However, current SDF methods are overly smooth and miss fine geometric details. In this work, we combine the strengths of these two lines of work in a novel hash-based implicit surface representation. We propose improvements to the two areas by replacing the voxel hash encoding with a permutohedral lattice which optimizes faster in three and higher dimensions. We additionally propose a regularization scheme which is crucial for recovering high-frequency geometric detail. We evaluate our method on multiple datasets and show that we can recover geometric detail at the level of pores and wrinkles while using only RGB images for supervision. Furthermore, using sphere tracing we can render novel views at 30 fps on an RTX 3090.
Neural Strands: Learning Hair Geometry and Appearance from Multi-View Images
Jul 28, 2022

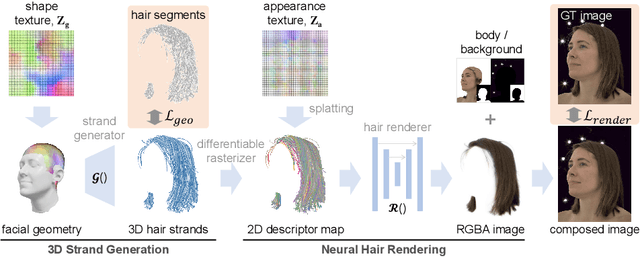
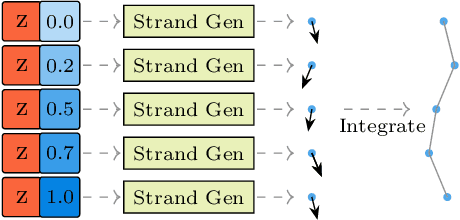
We present Neural Strands, a novel learning framework for modeling accurate hair geometry and appearance from multi-view image inputs. The learned hair model can be rendered in real-time from any viewpoint with high-fidelity view-dependent effects. Our model achieves intuitive shape and style control unlike volumetric counterparts. To enable these properties, we propose a novel hair representation based on a neural scalp texture that encodes the geometry and appearance of individual strands at each texel location. Furthermore, we introduce a novel neural rendering framework based on rasterization of the learned hair strands. Our neural rendering is strand-accurate and anti-aliased, making the rendering view-consistent and photorealistic. Combining appearance with a multi-view geometric prior, we enable, for the first time, the joint learning of appearance and explicit hair geometry from a multi-view setup. We demonstrate the efficacy of our approach in terms of fidelity and efficiency for various hairstyles.
Abstract Flow for Temporal Semantic Segmentation on the Permutohedral Lattice
Mar 29, 2022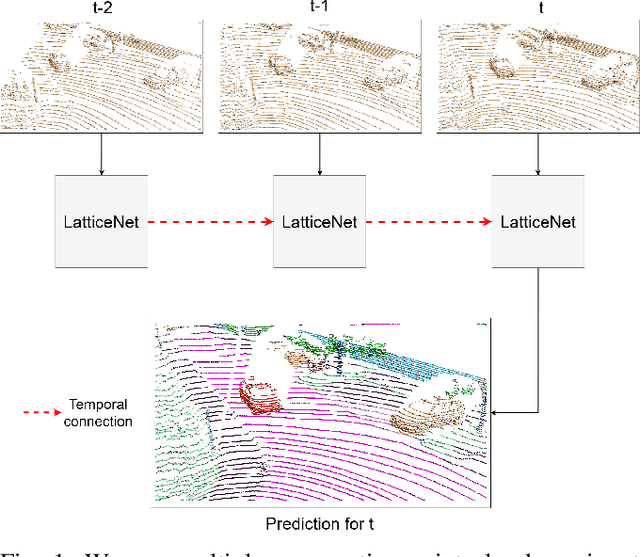
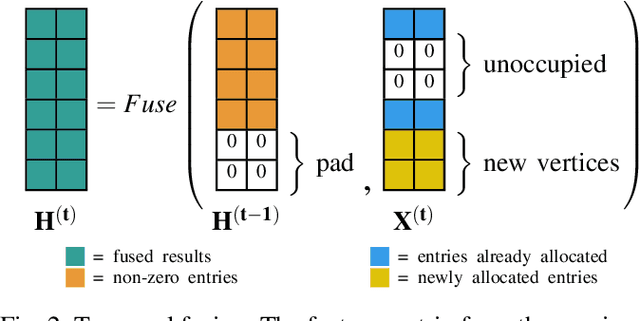
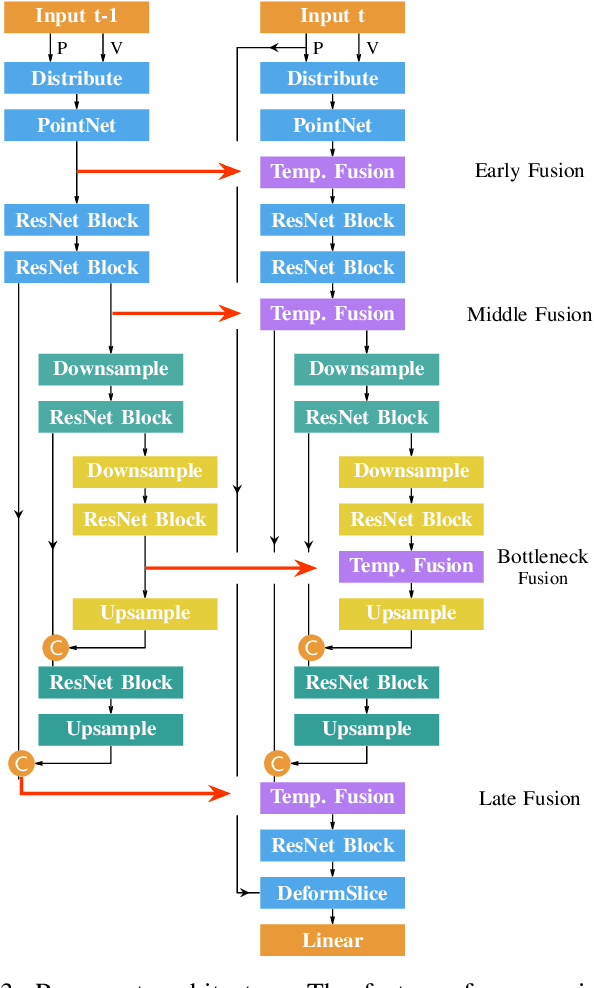
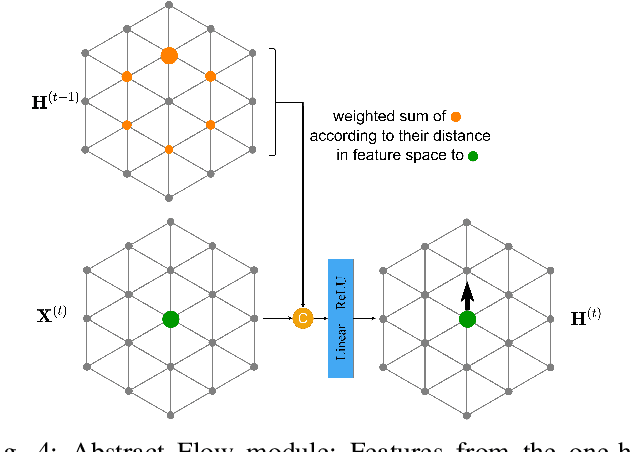
Semantic segmentation is a core ability required by autonomous agents, as being able to distinguish which parts of the scene belong to which object class is crucial for navigation and interaction with the environment. Approaches which use only one time-step of data cannot distinguish between moving objects nor can they benefit from temporal integration. In this work, we extend a backbone LatticeNet to process temporal point cloud data. Additionally, we take inspiration from optical flow methods and propose a new module called Abstract Flow which allows the network to match parts of the scene with similar abstract features and gather the information temporally. We obtain state-of-the-art results on the SemanticKITTI dataset that contains LiDAR scans from real urban environments. We share the PyTorch implementation of TemporalLatticeNet at https://github.com/AIS-Bonn/temporal_latticenet .
Target Chase, Wall Building, and Fire Fighting: Autonomous UAVs of Team NimbRo at MBZIRC 2020
Jan 11, 2022

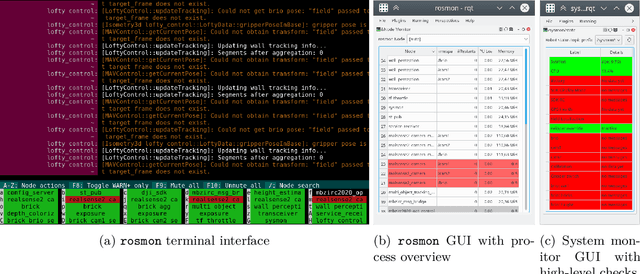

The Mohamed Bin Zayed International Robotics Challenge (MBZIRC) 2020 posed diverse challenges for unmanned aerial vehicles (UAVs). We present our four tailored UAVs, specifically developed for individual aerial-robot tasks of MBZIRC, including custom hardware- and software components. In Challenge 1, a target UAV is pursued using a high-efficiency, onboard object detection pipeline to capture a ball from the target UAV. A second UAV uses a similar detection method to find and pop balloons scattered throughout the arena. For Challenge 2, we demonstrate a larger UAV capable of autonomous aerial manipulation: Bricks are found and tracked from camera images. Subsequently, they are approached, picked, transported, and placed on a wall. Finally, in Challenge 3, our UAV autonomously finds fires using LiDAR and thermal cameras. It extinguishes the fires with an onboard fire extinguisher. While every robot features task-specific subsystems, all UAVs rely on a standard software stack developed for this particular and future competitions. We present our mostly open-source software solutions, including tools for system configuration, monitoring, robust wireless communication, high-level control, and agile trajectory generation. For solving the MBZIRC 2020 tasks, we advanced the state of the art in multiple research areas like machine vision and trajectory generation. We present our scientific contributions that constitute the foundation for our algorithms and systems and analyze the results from the MBZIRC competition 2020 in Abu Dhabi, where our systems reached second place in the Grand Challenge. Furthermore, we discuss lessons learned from our participation in this complex robotic challenge.
LatticeNet: Fast Spatio-Temporal Point Cloud Segmentation Using Permutohedral Lattices
Aug 09, 2021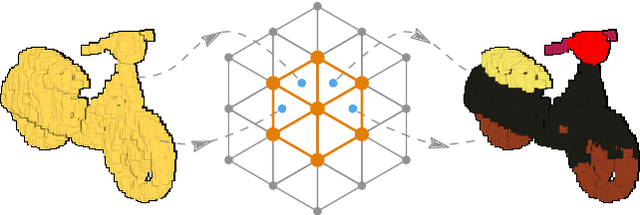
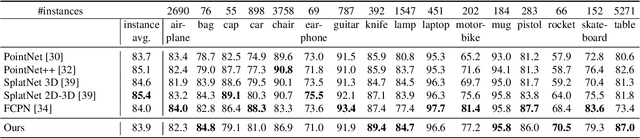
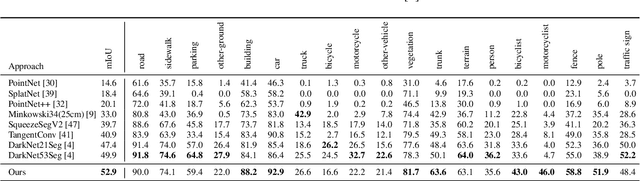
Deep convolutional neural networks (CNNs) have shown outstanding performance in the task of semantically segmenting images. Applying the same methods on 3D data still poses challenges due to the heavy memory requirements and the lack of structured data. Here, we propose LatticeNet, a novel approach for 3D semantic segmentation, which takes raw point clouds as input. A PointNet describes the local geometry which we embed into a sparse permutohedral lattice. The lattice allows for fast convolutions while keeping a low memory footprint. Further, we introduce DeformSlice, a novel learned data-dependent interpolation for projecting lattice features back onto the point cloud. We present results of 3D segmentation on multiple datasets where our method achieves state-of-the-art performance. We also extend and evaluate our network for instance and dynamic object segmentation.
NeuralMVS: Bridging Multi-View Stereo and Novel View Synthesis
Aug 09, 2021
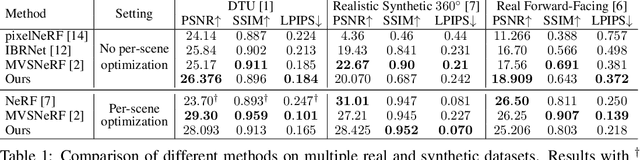
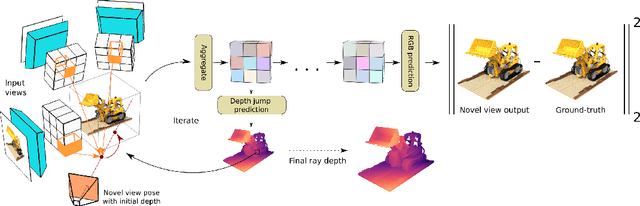
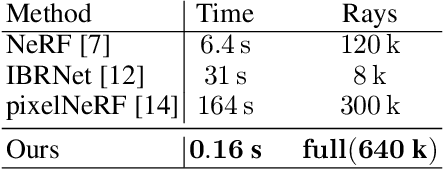
Multi-View Stereo (MVS) is a core task in 3D computer vision. With the surge of novel deep learning methods, learned MVS has surpassed the accuracy of classical approaches, but still relies on building a memory intensive dense cost volume. Novel View Synthesis (NVS) is a parallel line of research and has recently seen an increase in popularity with Neural Radiance Field (NeRF) models, which optimize a per scene radiance field. However, NeRF methods do not generalize to novel scenes and are slow to train and test. We propose to bridge the gap between these two methodologies with a novel network that can recover 3D scene geometry as a distance function, together with high-resolution color images. Our method uses only a sparse set of images as input and can generalize well to novel scenes. Additionally, we propose a coarse-to-fine sphere tracing approach in order to significantly increase speed. We show on various datasets that our method reaches comparable accuracy to per-scene optimized methods while being able to generalize and running significantly faster.
Visually Guided Balloon Popping with an Autonomous MAV at MBZIRC 2020
Oct 28, 2020
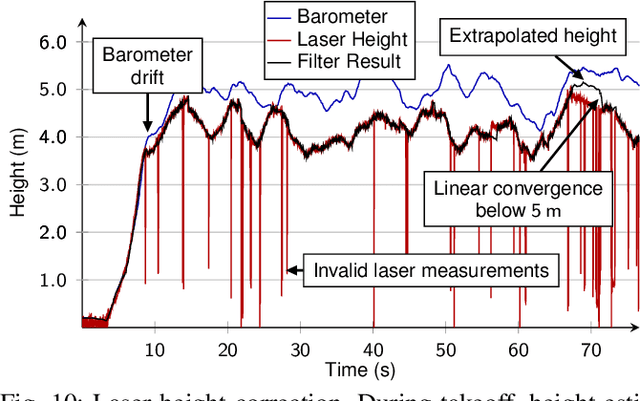
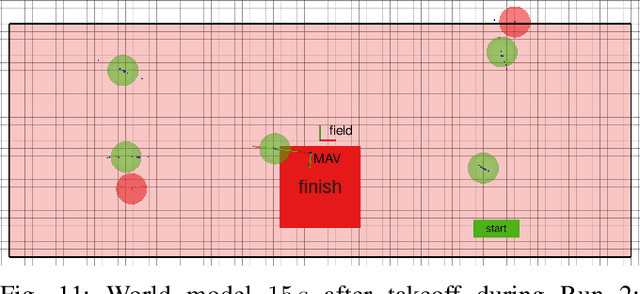
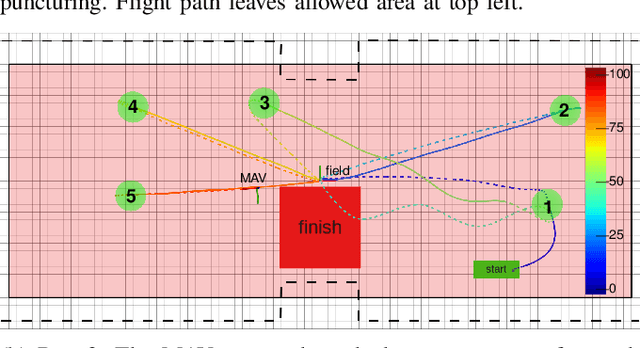
Visually guided control of micro aerial vehicles (MAV) demands for robust real-time perception, fast trajectory generation, and a capable flight platform. We present a fully autonomous MAV that is able to pop balloons, relying only on onboard sensing and computing. The system is evaluated with real robot experiments during the Mohamed Bin Zayed International Robotics Challenge (MBZIRC) 2020 where it showed its resilience and speed. In all three competition runs we were able to pop all five balloons in less than two minutes flight time with a single MAV.
Beyond Photometric Consistency: Gradient-based Dissimilarity for Improving Visual Odometry and Stereo Matching
Apr 08, 2020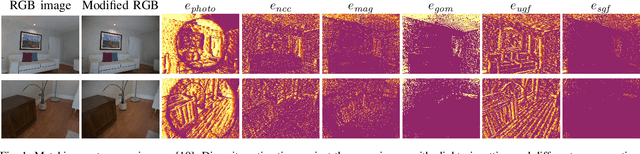
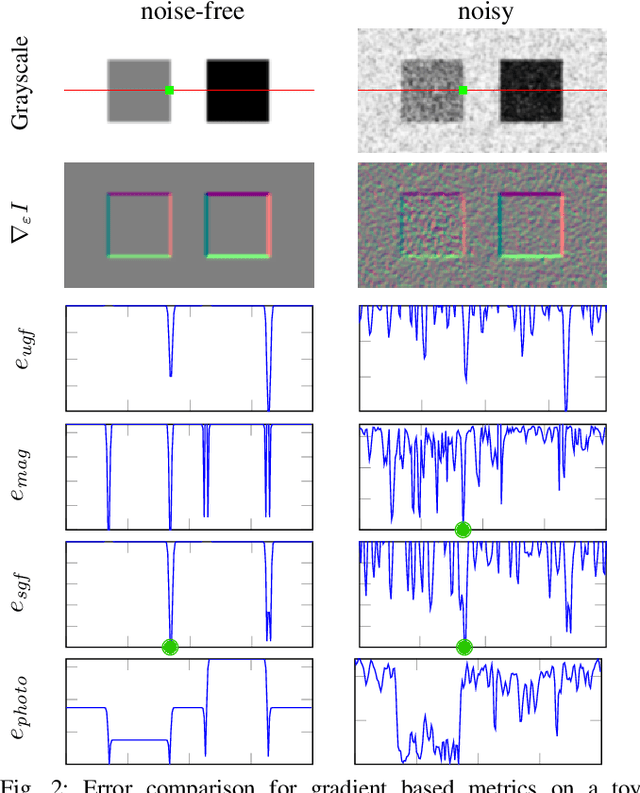
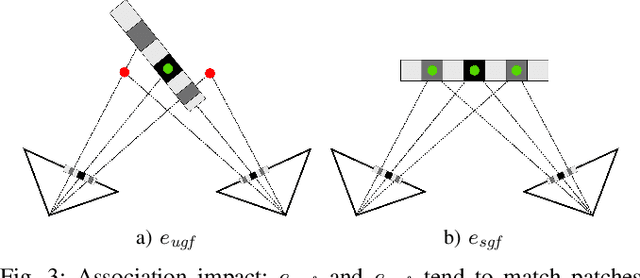
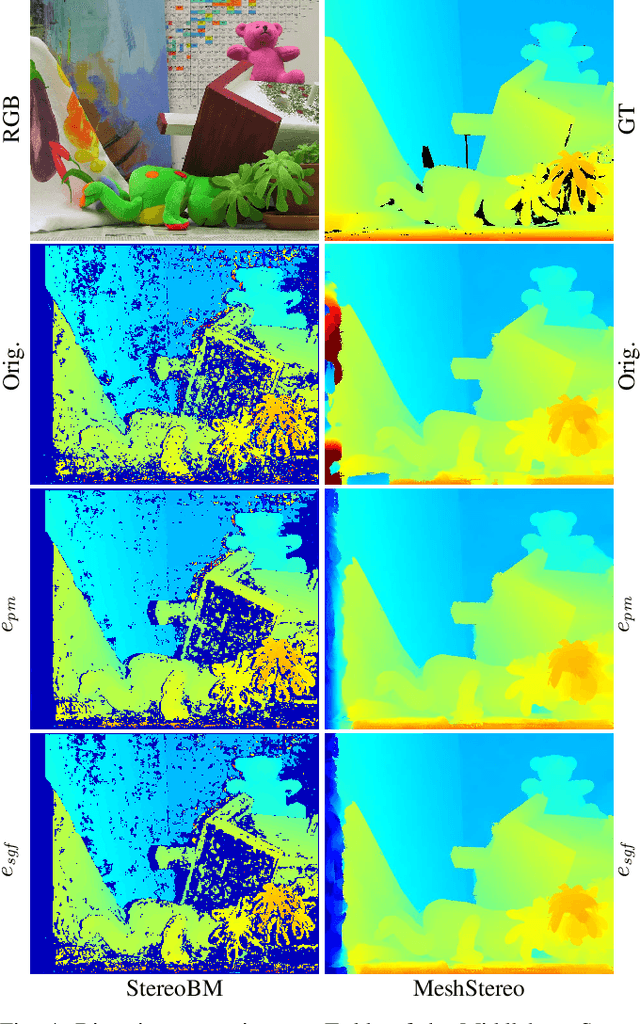
Pose estimation and map building are central ingredients of autonomous robots and typically rely on the registration of sensor data. In this paper, we investigate a new metric for registering images that builds upon on the idea of the photometric error. Our approach combines a gradient orientation-based metric with a magnitude-dependent scaling term. We integrate both into stereo estimation as well as visual odometry systems and show clear benefits for typical disparity and direct image registration tasks when using our proposed metric. Our experimental evaluation indicats that our metric leads to more robust and more accurate estimates of the scene depth as well as camera trajectory. Thus, the metric improves camera pose estimation and in turn the mapping capabilities of mobile robots. We believe that a series of existing visual odometry and visual SLAM systems can benefit from the findings reported in this paper.