 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Dataset and Benchmark for Shape Completion of Fruits for Agricultural Robotics
Jul 18, 2024As the population is expected to reach 10 billion by 2050, our agricultural production system needs to double its productivity despite a decline of human workforce in the agricultural sector. Autonomous robotic systems are one promising pathway to increase productivity by taking over labor-intensive manual tasks like fruit picking. To be effective, such systems need to monitor and interact with plants and fruits precisely, which is challenging due to the cluttered nature of agricultural environments causing, for example, strong occlusions. Thus, being able to estimate the complete 3D shapes of objects in presence of occlusions is crucial for automating operations such as fruit harvesting. In this paper, we propose the first publicly available 3D shape completion dataset for agricultural vision systems. We provide an RGB-D dataset for estimating the 3D shape of fruits. Specifically, our dataset contains RGB-D frames of single sweet peppers in lab conditions but also in a commercial greenhouse. For each fruit, we additionally collected high-precision point clouds that we use as ground truth. For acquiring the ground truth shape, we developed a measuring process that allows us to record data of real sweet pepper plants, both in the lab and in the greenhouse with high precision, and determine the shape of the sensed fruits. We release our dataset, consisting of almost 7000 RGB-D frames belonging to more than 100 different fruits. We provide segmented RGB-D frames, with camera instrinsics to easily obtain colored point clouds, together with the corresponding high-precision, occlusion-free point clouds obtained with a high-precision laser scanner. We additionally enable evaluation ofshape completion approaches on a hidden test set through a public challenge on a benchmark server.
PAg-NeRF: Towards fast and efficient end-to-end panoptic 3D representations for agricultural robotics
Sep 11, 2023Precise scene understanding is key for most robot monitoring and intervention tasks in agriculture. In this work we present PAg-NeRF which is a novel NeRF-based system that enables 3D panoptic scene understanding. Our representation is trained using an image sequence with noisy robot odometry poses and automatic panoptic predictions with inconsistent IDs between frames. Despite this noisy input, our system is able to output scene geometry, photo-realistic renders and 3D consistent panoptic representations with consistent instance IDs. We evaluate this novel system in a very challenging horticultural scenario and in doing so demonstrate an end-to-end trainable system that can make use of noisy robot poses rather than precise poses that have to be pre-calculated. Compared to a baseline approach the peak signal to noise ratio is improved from 21.34dB to 23.37dB while the panoptic quality improves from 56.65% to 70.08%. Furthermore, our approach is faster and can be tuned to improve inference time by more than a factor of 2 while being memory efficient with approximately 12 times fewer parameters.
Panoptic Mapping with Fruit Completion and Pose Estimation for Horticultural Robots
Mar 15, 2023Monitoring plants and fruits at high resolution play a key role in the future of agriculture. Accurate 3D information can pave the way to a diverse number of robotic applications in agriculture ranging from autonomous harvesting to precise yield estimation. Obtaining such 3D information is non-trivial as agricultural environments are often repetitive and cluttered, and one has to account for the partial observability of fruit and plants. In this paper, we address the problem of jointly estimating complete 3D shapes of fruit and their pose in a 3D multi-resolution map built by a mobile robot. To this end, we propose an online multi-resolution panoptic mapping system where regions of interest are represented with a higher resolution. We exploit data to learn a general fruit shape representation that we use at inference time together with an occlusion-aware differentiable rendering pipeline to complete partial fruit observations and estimate the 7 DoF pose of each fruit in the map. The experiments presented in this paper, evaluated both in the controlled environment and in a commercial greenhouse, show that our novel algorithm yields higher completion and pose estimation accuracy than existing methods, with an improvement of 41% in completion accuracy and 52% in pose estimation accuracy while keeping a low inference time of 0.6s in average.
Robust Onboard Localization in Changing Environments Exploiting Text Spotting
Mar 23, 2022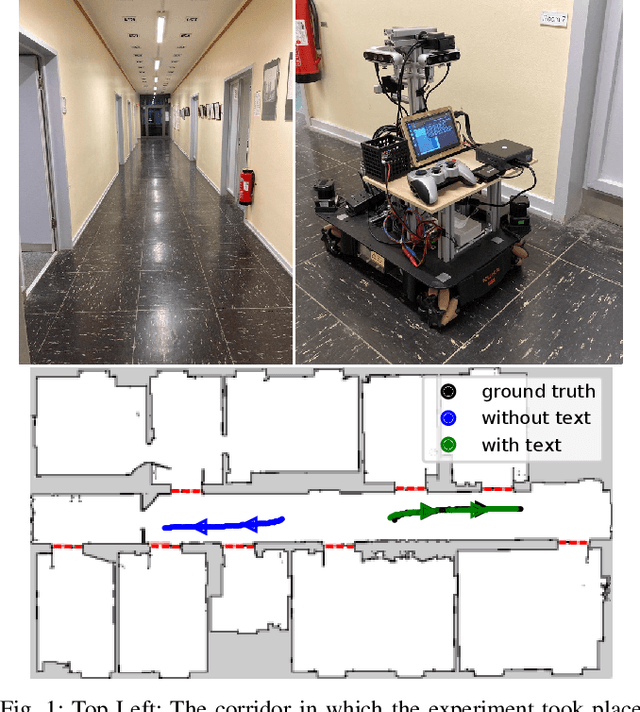
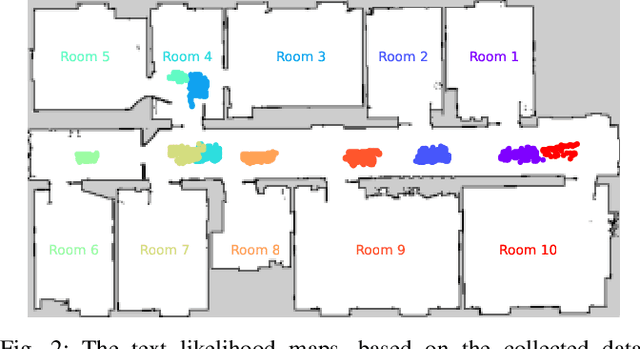

Robust localization in a given map is a crucial component of most autonomous robots. In this paper, we address the problem of localizing in an indoor environment that changes and where prominent structures have no correspondence in the map built at a different point in time. To overcome the discrepancy between the map and the observed environment caused by such changes, we exploit human-readable localization cues to assist localization. These cues are readily available in most facilities and can be detected using RGB camera images by utilizing text spotting. We integrate these cues into a Monte Carlo localization framework using a particle filter that operates on 2D LiDAR scans and camera data. By this, we provide a robust localization solution for environments with structural changes and dynamics by humans walking. We evaluate our localization framework on multiple challenging indoor scenarios in an office environment. The experiments suggest that our approach is robust to structural changes and can run on an onboard computer. We release an open source implementation of our approach (upon paper acceptance), which uses off-the-shelf text spotting, written in C++ with a ROS wrapper.
Range Image-based LiDAR Localization for Autonomous Vehicles
May 25, 2021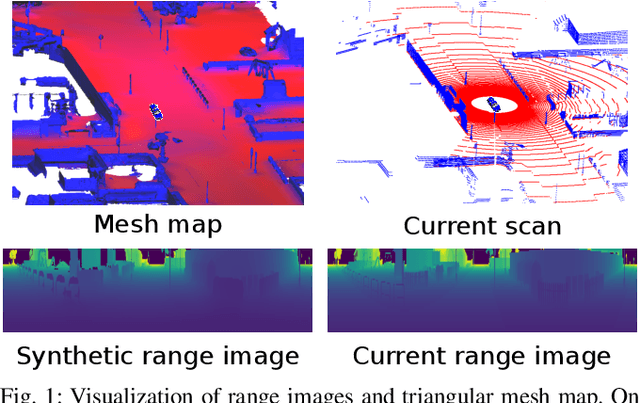
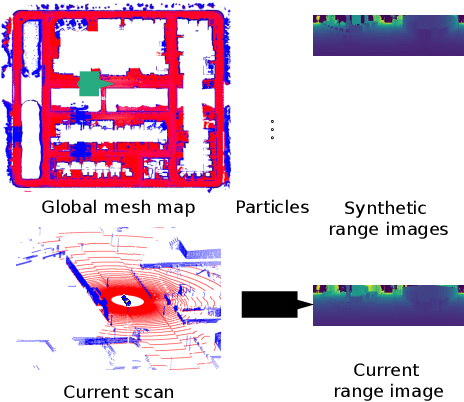
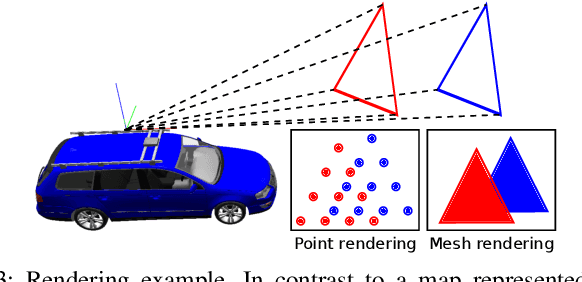
Robust and accurate, map-based localization is crucial for autonomous mobile systems. In this paper, we exploit range images generated from 3D LiDAR scans to address the problem of localizing mobile robots or autonomous cars in a map of a large-scale outdoor environment represented by a triangular mesh. We use the Poisson surface reconstruction to generate the mesh-based map representation. Based on the range images generated from the current LiDAR scan and the synthetic rendered views from the mesh-based map, we propose a new observation model and integrate it into a Monte Carlo localization framework, which achieves better localization performance and generalizes well to different environments. We test the proposed localization approach on multiple datasets collected in different environments with different LiDAR scanners. The experimental results show that our method can reliably and accurately localize a mobile system in different environments and operate online at the LiDAR sensor frame rate to track the vehicle pose.
Learning an Overlap-based Observation Model for 3D LiDAR Localization
May 25, 2021



Localization is a crucial capability for mobile robots and autonomous cars. In this paper, we address learning an observation model for Monte-Carlo localization using 3D LiDAR data. We propose a novel, neural network-based observation model that computes the expected overlap of two 3D LiDAR scans. The model predicts the overlap and yaw angle offset between the current sensor reading and virtual frames generated from a pre-built map. We integrate this observation model into a Monte-Carlo localization framework and tested it on urban datasets collected with a car in different seasons. The experiments presented in this paper illustrate that our method can reliably localize a vehicle in typical urban environments. We furthermore provide comparisons to a beam-end point and a histogram-based method indicating a superior global localization performance of our method with fewer particles.
OverlapNet: Loop Closing for LiDAR-based SLAM
May 24, 2021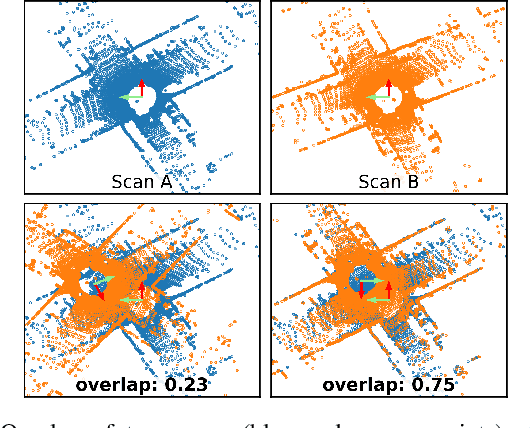
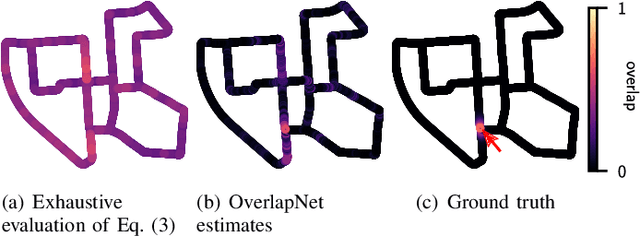

Simultaneous localization and mapping (SLAM) is a fundamental capability required by most autonomous systems. In this paper, we address the problem of loop closing for SLAM based on 3D laser scans recorded by autonomous cars. Our approach utilizes a deep neural network exploiting different cues generated from LiDAR data for finding loop closures. It estimates an image overlap generalized to range images and provides a relative yaw angle estimate between pairs of scans. Based on such predictions, we tackle loop closure detection and integrate our approach into an existing SLAM system to improve its mapping results. We evaluate our approach on sequences of the KITTI odometry benchmark and the Ford campus dataset. We show that our method can effectively detect loop closures surpassing the detection performance of state-of-the-art methods. To highlight the generalization capabilities of our approach, we evaluate our model on the Ford campus dataset while using only KITTI for training. The experiments show that the learned representation is able to provide reliable loop closure candidates, also in unseen environments.
Adaptive Robust Kernels for Non-Linear Least Squares Problems
May 27, 2020
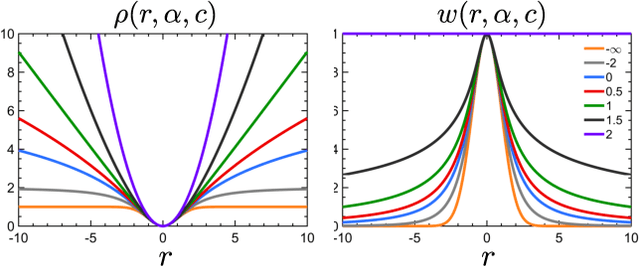
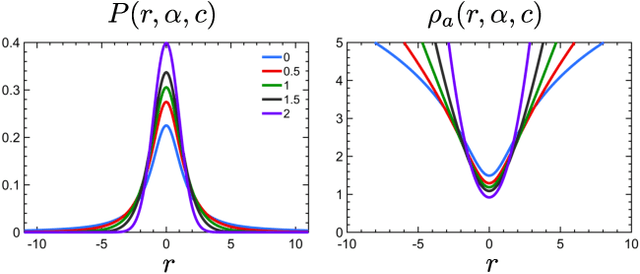

State estimation is a key ingredient in most robotic systems. Often, state estimation is performed using some form of least squares minimization. Basically, all error minimization procedures that work on real-world data use robust kernels as the standard way for dealing with outliers in the data. These kernels, however, are often hand-picked, sometimes in different combinations, and their parameters need to be tuned manually for a particular problem. In this paper, we propose the use of a generalized robust kernel family, which is automatically tuned based on the distribution of the residuals and includes the common m-estimators. We tested our adaptive kernel with two popular estimation problems in robotics, namely ICP and bundle adjustment. The experiments presented in this paper suggest that our approach provides higher robustness while avoiding a manual tuning of the kernel parameters.
Beyond Photometric Consistency: Gradient-based Dissimilarity for Improving Visual Odometry and Stereo Matching
Apr 08, 2020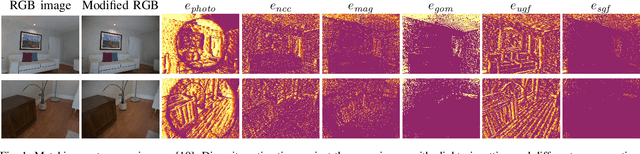
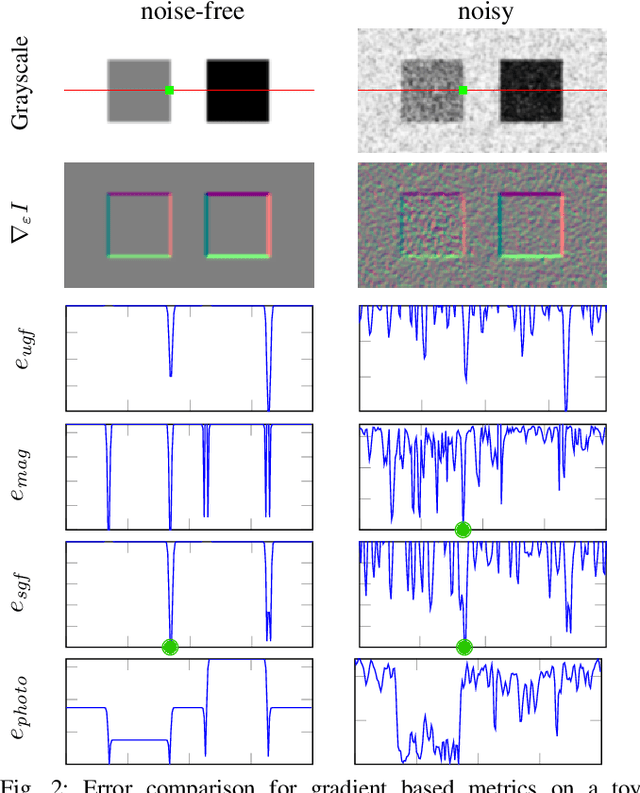
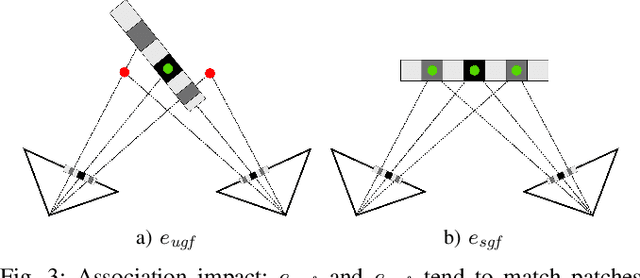
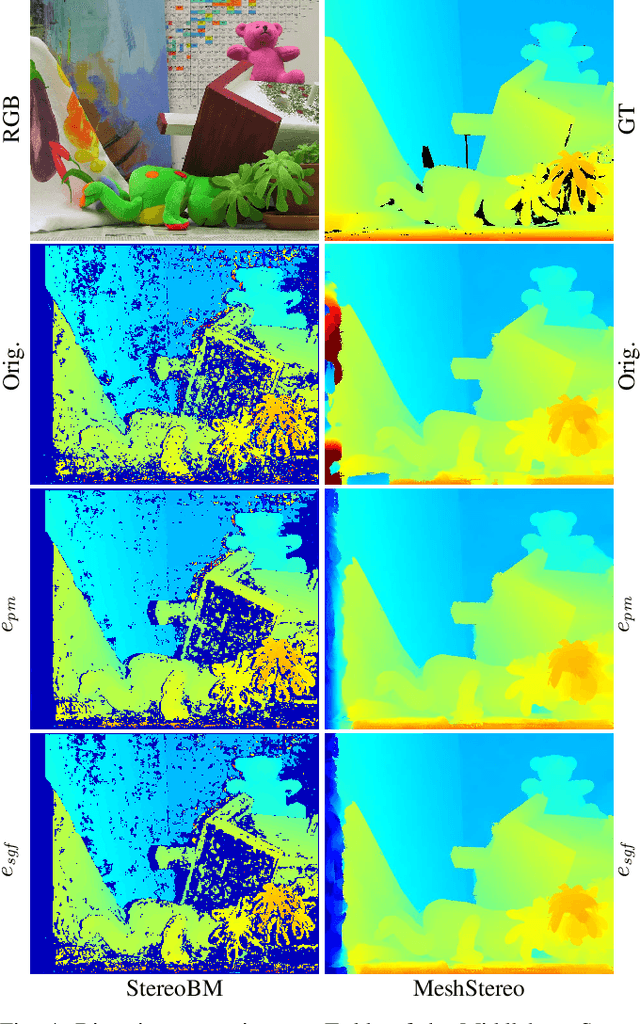
Pose estimation and map building are central ingredients of autonomous robots and typically rely on the registration of sensor data. In this paper, we investigate a new metric for registering images that builds upon on the idea of the photometric error. Our approach combines a gradient orientation-based metric with a magnitude-dependent scaling term. We integrate both into stereo estimation as well as visual odometry systems and show clear benefits for typical disparity and direct image registration tasks when using our proposed metric. Our experimental evaluation indicats that our metric leads to more robust and more accurate estimates of the scene depth as well as camera trajectory. Thus, the metric improves camera pose estimation and in turn the mapping capabilities of mobile robots. We believe that a series of existing visual odometry and visual SLAM systems can benefit from the findings reported in this paper.