 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Dataset and Benchmark for Shape Completion of Fruits for Agricultural Robotics
Jul 18, 2024As the population is expected to reach 10 billion by 2050, our agricultural production system needs to double its productivity despite a decline of human workforce in the agricultural sector. Autonomous robotic systems are one promising pathway to increase productivity by taking over labor-intensive manual tasks like fruit picking. To be effective, such systems need to monitor and interact with plants and fruits precisely, which is challenging due to the cluttered nature of agricultural environments causing, for example, strong occlusions. Thus, being able to estimate the complete 3D shapes of objects in presence of occlusions is crucial for automating operations such as fruit harvesting. In this paper, we propose the first publicly available 3D shape completion dataset for agricultural vision systems. We provide an RGB-D dataset for estimating the 3D shape of fruits. Specifically, our dataset contains RGB-D frames of single sweet peppers in lab conditions but also in a commercial greenhouse. For each fruit, we additionally collected high-precision point clouds that we use as ground truth. For acquiring the ground truth shape, we developed a measuring process that allows us to record data of real sweet pepper plants, both in the lab and in the greenhouse with high precision, and determine the shape of the sensed fruits. We release our dataset, consisting of almost 7000 RGB-D frames belonging to more than 100 different fruits. We provide segmented RGB-D frames, with camera instrinsics to easily obtain colored point clouds, together with the corresponding high-precision, occlusion-free point clouds obtained with a high-precision laser scanner. We additionally enable evaluation ofshape completion approaches on a hidden test set through a public challenge on a benchmark server.
BonnBot-I Plus: A Bio-diversity Aware Precise Weed Management Robotic Platform
May 15, 2024In this article, we focus on the critical tasks of plant protection in arable farms, addressing a modern challenge in agriculture: integrating ecological considerations into the operational strategy of precision weeding robots like \bbot. This article presents the recent advancements in weed management algorithms and the real-world performance of \bbot\ at the University of Bonn's Klein-Altendorf campus. We present a novel Rolling-view observation model for the BonnBot-Is weed monitoring section which leads to an average absolute weeding performance enhancement of $3.4\%$. Furthermore, for the first time, we show how precision weeding robots could consider bio-diversity-aware concerns in challenging weeding scenarios. We carried out comprehensive weeding experiments in sugar-beet fields, covering both weed-only and mixed crop-weed situations, and introduced a new dataset compatible with precision weeding. Our real-field experiments revealed that our weeding approach is capable of handling diverse weed distributions, with a minimal loss of only $11.66\%$ attributable to intervention planning and $14.7\%$ to vision system limitations highlighting required improvements of the vision system.
PAg-NeRF: Towards fast and efficient end-to-end panoptic 3D representations for agricultural robotics
Sep 11, 2023Precise scene understanding is key for most robot monitoring and intervention tasks in agriculture. In this work we present PAg-NeRF which is a novel NeRF-based system that enables 3D panoptic scene understanding. Our representation is trained using an image sequence with noisy robot odometry poses and automatic panoptic predictions with inconsistent IDs between frames. Despite this noisy input, our system is able to output scene geometry, photo-realistic renders and 3D consistent panoptic representations with consistent instance IDs. We evaluate this novel system in a very challenging horticultural scenario and in doing so demonstrate an end-to-end trainable system that can make use of noisy robot poses rather than precise poses that have to be pre-calculated. Compared to a baseline approach the peak signal to noise ratio is improved from 21.34dB to 23.37dB while the panoptic quality improves from 56.65% to 70.08%. Furthermore, our approach is faster and can be tuned to improve inference time by more than a factor of 2 while being memory efficient with approximately 12 times fewer parameters.
BonnBot-I: A Precise Weed Management and Crop Monitoring Platform
Jul 24, 2023Cultivation and weeding are two of the primary tasks performed by farmers today. A recent challenge for weeding is the desire to reduce herbicide and pesticide treatments while maintaining crop quality and quantity. In this paper we introduce BonnBot-I a precise weed management platform which can also performs field monitoring. Driven by crop monitoring approaches which can accurately locate and classify plants (weed and crop) we further improve their performance by fusing the platform available GNSS and wheel odometry. This improves tracking accuracy of our crop monitoring approach from a normalized average error of 8.3% to 3.5%, evaluated on a new publicly available corn dataset. We also present a novel arrangement of weeding tools mounted on linear actuators evaluated in simulated environments. We replicate weed distributions from a real field, using the results from our monitoring approach, and show the validity of our work-space division techniques which require significantly less movement (a 50% reduction) to achieve similar results. Overall, BonnBot-I is a significant step forward in precise weed management with a novel method of selectively spraying and controlling weeds in an arable field
Panoptic One-Click Segmentation: Applied to Agricultural Data
Mar 15, 2023In weed control, precision agriculture can help to greatly reduce the use of herbicides, resulting in both economical and ecological benefits. A key element is the ability to locate and segment all the plants from image data. Modern instance segmentation techniques can achieve this, however, training such systems requires large amounts of hand-labelled data which is expensive and laborious to obtain. Weakly supervised training can help to greatly reduce labelling efforts and costs. We propose panoptic one-click segmentation, an efficient and accurate offline tool to produce pseudo-labels from click inputs which reduces labelling effort. Our approach jointly estimates the pixel-wise location of all N objects in the scene, compared to traditional approaches which iterate independently through all N objects; this greatly reduces training time. Using just 10% of the data to train our panoptic one-click segmentation approach yields 68.1% and 68.8% mean object intersection over union (IoU) on challenging sugar beet and corn image data respectively, providing comparable performance to traditional one-click approaches while being approximately 12 times faster to train. We demonstrate the applicability of our system by generating pseudo-labels from clicks on the remaining 90% of the data. These pseudo-labels are then used to train Mask R-CNN, in a semi-supervised manner, improving the absolute performance (of mean foreground IoU) by 9.4 and 7.9 points for sugar beet and corn data respectively. Finally, we show that our technique can recover missed clicks during annotation outlining a further benefit over traditional approaches.
Panoptic Mapping with Fruit Completion and Pose Estimation for Horticultural Robots
Mar 15, 2023Monitoring plants and fruits at high resolution play a key role in the future of agriculture. Accurate 3D information can pave the way to a diverse number of robotic applications in agriculture ranging from autonomous harvesting to precise yield estimation. Obtaining such 3D information is non-trivial as agricultural environments are often repetitive and cluttered, and one has to account for the partial observability of fruit and plants. In this paper, we address the problem of jointly estimating complete 3D shapes of fruit and their pose in a 3D multi-resolution map built by a mobile robot. To this end, we propose an online multi-resolution panoptic mapping system where regions of interest are represented with a higher resolution. We exploit data to learn a general fruit shape representation that we use at inference time together with an occlusion-aware differentiable rendering pipeline to complete partial fruit observations and estimate the 7 DoF pose of each fruit in the map. The experiments presented in this paper, evaluated both in the controlled environment and in a commercial greenhouse, show that our novel algorithm yields higher completion and pose estimation accuracy than existing methods, with an improvement of 41% in completion accuracy and 52% in pose estimation accuracy while keeping a low inference time of 0.6s in average.
Explicitly incorporating spatial information to recurrent networks for agriculture
Jun 27, 2022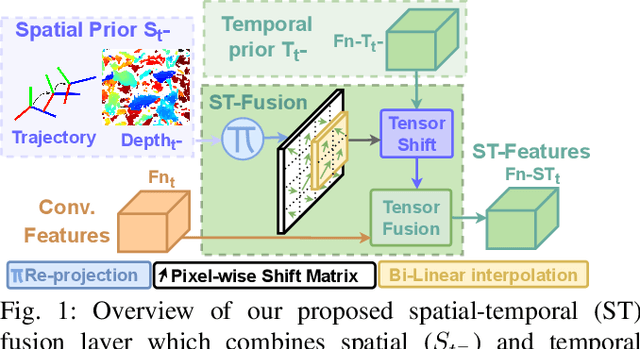
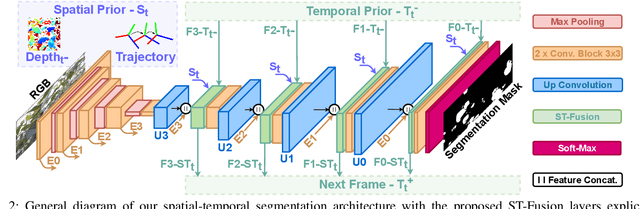
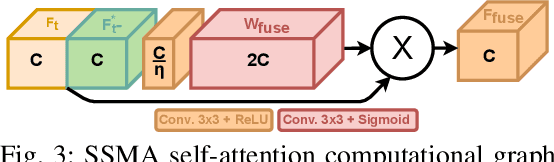

In agriculture, the majority of vision systems perform still image classification. Yet, recent work has highlighted the potential of spatial and temporal cues as a rich source of information to improve the classification performance. In this paper, we propose novel approaches to explicitly capture both spatial and temporal information to improve the classification of deep convolutional neural networks. We leverage available RGB-D images and robot odometry to perform inter-frame feature map spatial registration. This information is then fused within recurrent deep learnt models, to improve their accuracy and robustness. We demonstrate that this can considerably improve the classification performance with our best performing spatial-temporal model (ST-Atte) achieving absolute performance improvements for intersection-over-union (IoU[%]) of 4.7 for crop-weed segmentation and 2.6 for fruit (sweet pepper) segmentation. Furthermore, we show that these approaches are robust to variable framerates and odometry errors, which are frequently observed in real-world applications.
Towards Autonomous Crop-Agnostic Visual Navigation in Arable Fields
Sep 24, 2021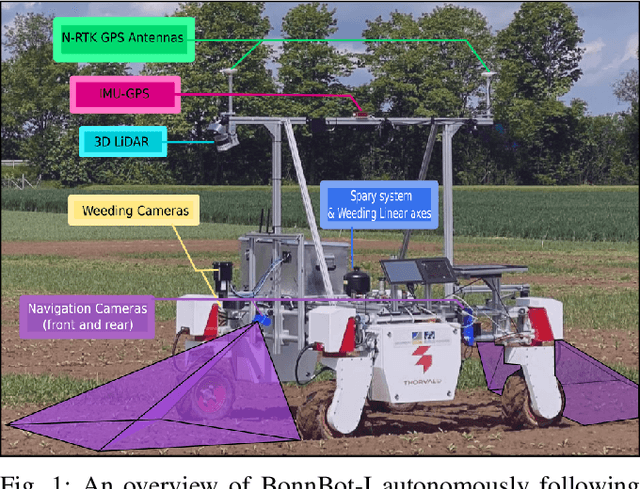
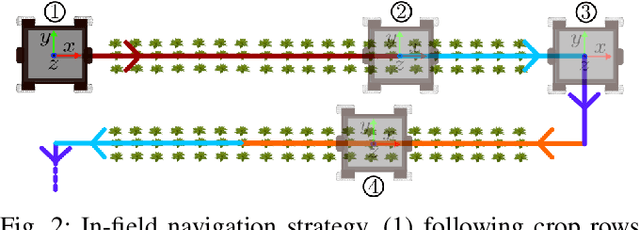

Autonomous navigation of a robot in agricultural fields is essential for every task from crop monitoring through to weed management and fertilizer application. Many current approaches rely on accurate GPS, however, such technology is expensive and also prone to failure~(e.g. through lack of coverage). As such, navigation through sensors that can interpret their environment (such as cameras) is important to achieve the goal of autonomy in agriculture. In this paper, we introduce a purely vision-based navigation scheme which is able to reliably guide the robot through row-crop fields. Independent of any global localization or mapping, this approach is able to accurately follow the crop-rows and switch between the rows, only using on-board cameras. With the help of a novel crop-row detection and a novel crop-row switching technique, our navigation scheme can be deployed in a wide range of fields with different canopy types in various growth stages. We have extensively tested our approach in five different fields under various illumination conditions using our agricultural robotic platform (BonnBot-I). And our evaluations show that we have achieved a navigation accuracy of 3.82cm over five different crop fields.
Combining Local and Global Viewpoint Planning for Fruit Coverage
Aug 18, 2021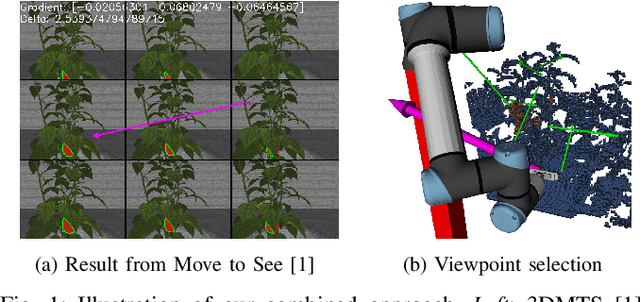
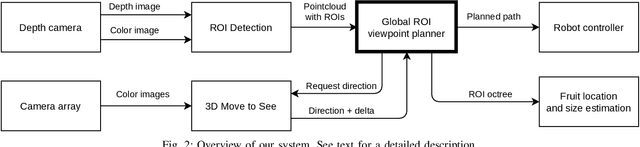
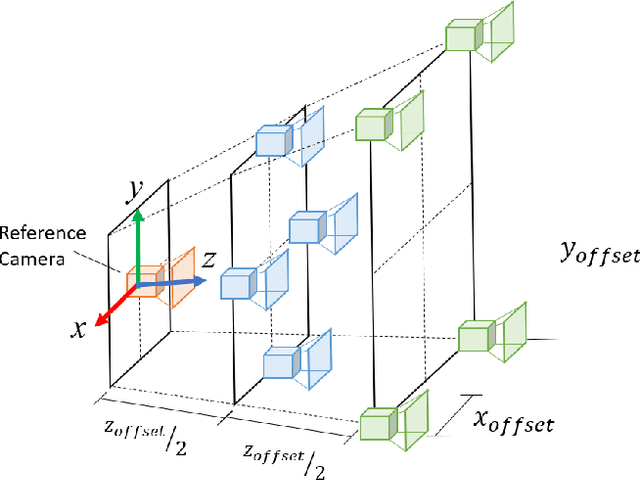

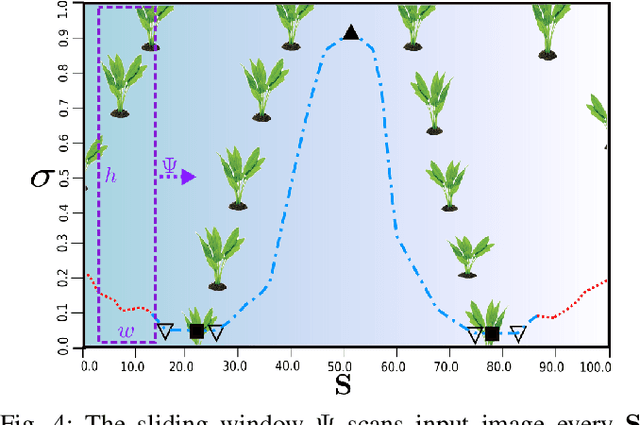
Obtaining 3D sensor data of complete plants or plant parts (e.g., the crop or fruit) is difficult due to their complex structure and a high degree of occlusion. However, especially for the estimation of the position and size of fruits, it is necessary to avoid occlusions as much as possible and acquire sensor information of the relevant parts. Global viewpoint planners exist that suggest a series of viewpoints to cover the regions of interest up to a certain degree, but they usually prioritize global coverage and do not emphasize the avoidance of local occlusions. On the other hand, there are approaches that aim at avoiding local occlusions, but they cannot be used in larger environments since they only reach a local maximum of coverage. In this paper, we therefore propose to combine a local, gradient-based method with global viewpoint planning to enable local occlusion avoidance while still being able to cover large areas. Our simulated experiments with a robotic arm equipped with a camera array as well as an RGB-D camera show that this combination leads to a significantly increased coverage of the regions of interest compared to just applying global coverage planning.
Virtual Temporal Samples for Recurrent Neural Networks: applied to semantic segmentation in agriculture
Jun 18, 2021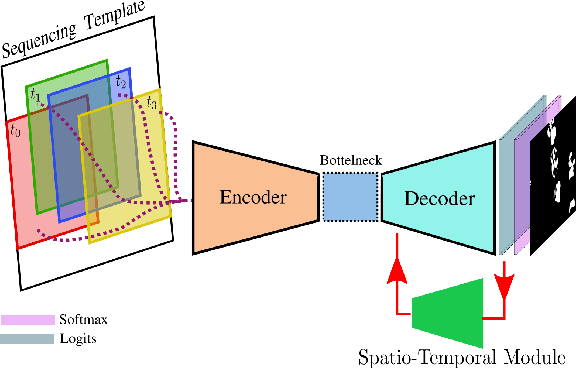

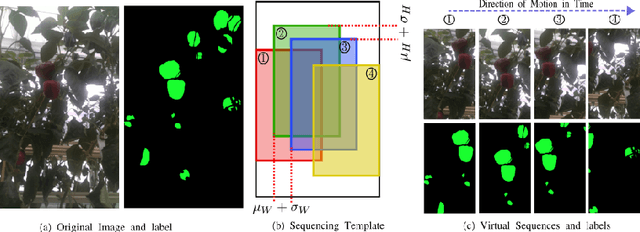

This paper explores the potential for performing temporal semantic segmentation in the context of agricultural robotics without temporally labelled data. We achieve this by proposing to generate virtual temporal samples from labelled still images. This allows us, with no extra annotation effort, to generate virtually labelled temporal sequences. Normally, to train a recurrent neural network (RNN), labelled samples from a video (temporal) sequence are required which is laborious and has stymied work in this direction. By generating virtual temporal samples, we demonstrate that it is possible to train a lightweight RNN to perform semantic segmentation on two challenging agricultural datasets. Our results show that by training a temporal semantic segmenter using virtual samples we can increase the performance by an absolute amount of 4.6 and 4.9 on sweet pepper and sugar beet datasets, respectively. This indicates that our virtual data augmentation technique is able to accurately classify agricultural images temporally without the use of complicated synthetic data generation techniques nor with the overhead of labelling large amounts of temporal sequences.