 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLiPS: Lightweight Panoptic Segmentation for Resource-Constrained Robotics
Apr 01, 2026Panoptic segmentation is a key enabler for robotic perception, as it unifies semantic understanding with object-level reasoning. However, the increasing complexity of state-of-the-art models makes them unsuitable for deployment on resource-constrained platforms such as mobile robots. We propose a novel approach called LiPS that addresses the challenge of efficient-to-compute panoptic segmentation with a lightweight design that retains query-based decoding while introducing a streamlined feature extraction and fusion pathway. It aims at providing a strong panoptic segmentation performance while substantially lowering the computational demands. Evaluations on standard benchmarks demonstrate that LiPS attains accuracy comparable to much heavier baselines, while providing up to 4.5 higher throughput, measured in frames per second, and requiring nearly 6.8 times fewer computations. This efficiency makes LiPS a highly relevant bridge between modern panoptic models and real-world robotic applications.
Loop Closure via Maximal Cliques in 3D LiDAR-Based SLAM
Mar 05, 2026Reliable loop closure detection remains a critical challenge in 3D LiDAR-based SLAM, especially under sensor noise, environmental ambiguity, and viewpoint variation conditions. RANSAC is often used in the context of loop closures for geometric model fitting in the presence of outliers. However, this approach may fail, leading to map inconsistency. We introduce a novel deterministic algorithm, CliReg, for loop closure validation that replaces RANSAC verification with a maximal clique search over a compatibility graph of feature correspondences. This formulation avoids random sampling and increases robustness in the presence of noise and outliers. We integrated our approach into a real- time pipeline employing binary 3D descriptors and a Hamming distance embedding binary search tree-based matching. We evaluated it on multiple real-world datasets featuring diverse LiDAR sensors. The results demonstrate that our proposed technique consistently achieves a lower pose error and more reliable loop closures than RANSAC, especially in sparse or ambiguous conditions. Additional experiments on 2D projection-based maps confirm its generality across spatial domains, making our approach a robust and efficient alternative for loop closure detection.
SAHA: Supervised Autonomous HArvester for selective forest thinning
Jan 03, 2026Forestry plays a vital role in our society, creating significant ecological, economic, and recreational value. Efficient forest management involves labor-intensive and complex operations. One essential task for maintaining forest health and productivity is selective thinning, which requires skilled operators to remove specific trees to create optimal growing conditions for the remaining ones. In this work, we present a solution based on a small-scale robotic harvester (SAHA) designed for executing this task with supervised autonomy. We build on a 4.5-ton harvester platform and implement key hardware modifications for perception and automatic control. We implement learning- and model-based approaches for precise control of hydraulic actuators, accurate navigation through cluttered environments, robust state estimation, and reliable semantic estimation of terrain traversability. Integrating state-of-the-art techniques in perception, planning, and control, our robotic harvester can autonomously navigate forest environments and reach targeted trees for selective thinning. We present experimental results from extensive field trials over kilometer-long autonomous missions in northern European forests, demonstrating the harvester's ability to operate in real forests. We analyze the performance and provide the lessons learned for advancing robotic forest management.
SemRaFiner: Panoptic Segmentation in Sparse and Noisy Radar Point Clouds
Jul 09, 2025Semantic scene understanding, including the perception and classification of moving agents, is essential to enabling safe and robust driving behaviours of autonomous vehicles. Cameras and LiDARs are commonly used for semantic scene understanding. However, both sensor modalities face limitations in adverse weather and usually do not provide motion information. Radar sensors overcome these limitations and directly offer information about moving agents by measuring the Doppler velocity, but the measurements are comparably sparse and noisy. In this paper, we address the problem of panoptic segmentation in sparse radar point clouds to enhance scene understanding. Our approach, called SemRaFiner, accounts for changing density in sparse radar point clouds and optimizes the feature extraction to improve accuracy. Furthermore, we propose an optimized training procedure to refine instance assignments by incorporating a dedicated data augmentation. Our experiments suggest that our approach outperforms state-of-the-art methods for radar-based panoptic segmentation.
Coherent Online Road Topology Estimation and Reasoning with Standard-Definition Maps
Jul 02, 2025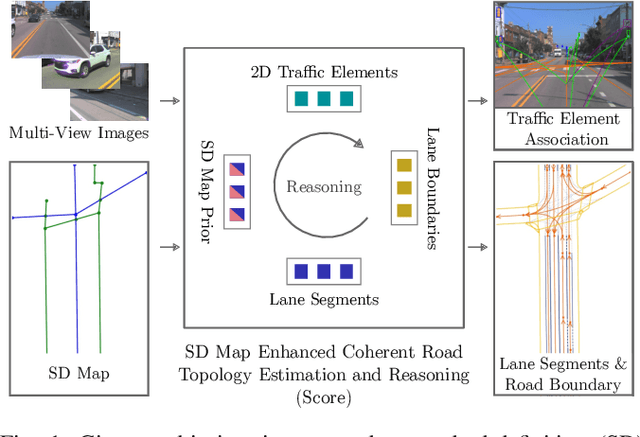
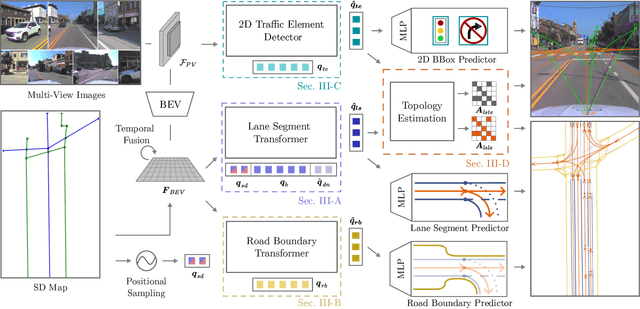
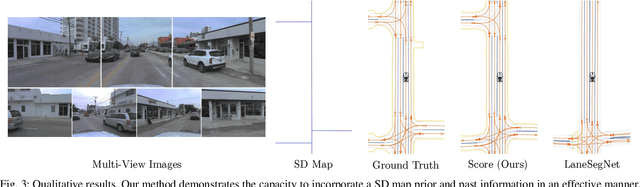
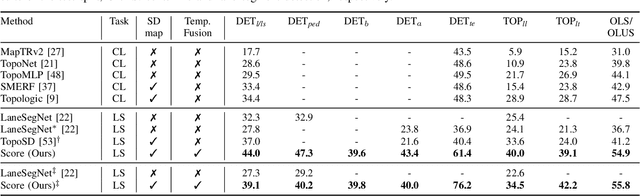
Most autonomous cars rely on the availability of high-definition (HD) maps. Current research aims to address this constraint by directly predicting HD map elements from onboard sensors and reasoning about the relationships between the predicted map and traffic elements. Despite recent advancements, the coherent online construction of HD maps remains a challenging endeavor, as it necessitates modeling the high complexity of road topologies in a unified and consistent manner. To address this challenge, we propose a coherent approach to predict lane segments and their corresponding topology, as well as road boundaries, all by leveraging prior map information represented by commonly available standard-definition (SD) maps. We propose a network architecture, which leverages hybrid lane segment encodings comprising prior information and denoising techniques to enhance training stability and performance. Furthermore, we facilitate past frames for temporal consistency. Our experimental evaluation demonstrates that our approach outperforms previous methods by a large margin, highlighting the benefits of our modeling scheme.
Uncertainty-Informed Active Perception for Open Vocabulary Object Goal Navigation
Jun 16, 2025



Mobile robots exploring indoor environments increasingly rely on vision-language models to perceive high-level semantic cues in camera images, such as object categories. Such models offer the potential to substantially advance robot behaviour for tasks such as object-goal navigation (ObjectNav), where the robot must locate objects specified in natural language by exploring the environment. Current ObjectNav methods heavily depend on prompt engineering for perception and do not address the semantic uncertainty induced by variations in prompt phrasing. Ignoring semantic uncertainty can lead to suboptimal exploration, which in turn limits performance. Hence, we propose a semantic uncertainty-informed active perception pipeline for ObjectNav in indoor environments. We introduce a novel probabilistic sensor model for quantifying semantic uncertainty in vision-language models and incorporate it into a probabilistic geometric-semantic map to enhance spatial understanding. Based on this map, we develop a frontier exploration planner with an uncertainty-informed multi-armed bandit objective to guide efficient object search. Experimental results demonstrate that our method achieves ObjectNav success rates comparable to those of state-of-the-art approaches, without requiring extensive prompt engineering.
DM-OSVP++: One-Shot View Planning Using 3D Diffusion Models for Active RGB-Based Object Reconstruction
Apr 16, 2025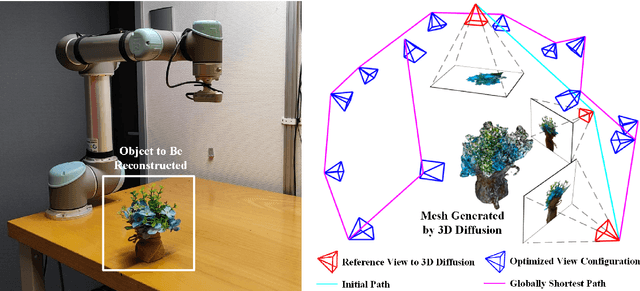


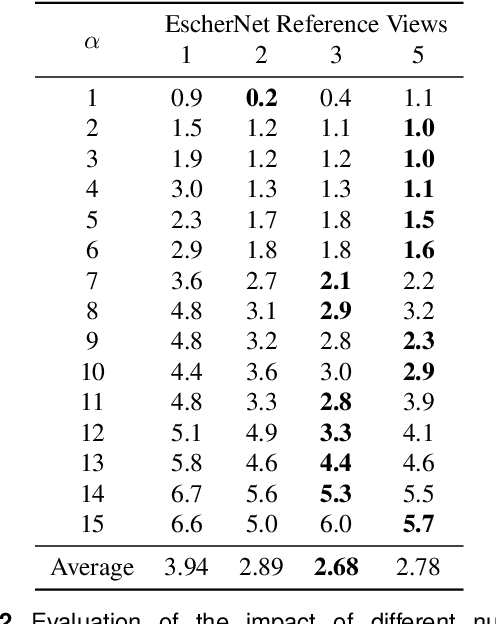
Active object reconstruction is crucial for many robotic applications. A key aspect in these scenarios is generating object-specific view configurations to obtain informative measurements for reconstruction. One-shot view planning enables efficient data collection by predicting all views at once, eliminating the need for time-consuming online replanning. Our primary insight is to leverage the generative power of 3D diffusion models as valuable prior information. By conditioning on initial multi-view images, we exploit the priors from the 3D diffusion model to generate an approximate object model, serving as the foundation for our view planning. Our novel approach integrates the geometric and textural distributions of the object model into the view planning process, generating views that focus on the complex parts of the object to be reconstructed. We validate the proposed active object reconstruction system through both simulation and real-world experiments, demonstrating the effectiveness of using 3D diffusion priors for one-shot view planning.
Doppler-SLAM: Doppler-Aided Radar-Inertial and LiDAR-Inertial Simultaneous Localization and Mapping
Apr 15, 2025Simultaneous localization and mapping (SLAM) is a critical capability for autonomous systems. Traditional SLAM approaches, which often rely on visual or LiDAR sensors, face significant challenges in adverse conditions such as low light or featureless environments. To overcome these limitations, we propose a novel Doppler-aided radar-inertial and LiDAR-inertial SLAM framework that leverages the complementary strengths of 4D radar, FMCW LiDAR, and inertial measurement units. Our system integrates Doppler velocity measurements and spatial data into a tightly-coupled front-end and graph optimization back-end to provide enhanced ego velocity estimation, accurate odometry, and robust mapping. We also introduce a Doppler-based scan-matching technique to improve front-end odometry in dynamic environments. In addition, our framework incorporates an innovative online extrinsic calibration mechanism, utilizing Doppler velocity and loop closure to dynamically maintain sensor alignment. Extensive evaluations on both public and proprietary datasets show that our system significantly outperforms state-of-the-art radar-SLAM and LiDAR-SLAM frameworks in terms of accuracy and robustness. To encourage further research, the code of our Doppler-SLAM and our dataset are available at: https://github.com/Wayne-DWA/Doppler-SLAM.
Improving Indoor Localization Accuracy by Using an Efficient Implicit Neural Map Representation
Mar 30, 2025Globally localizing a mobile robot in a known map is often a foundation for enabling robots to navigate and operate autonomously. In indoor environments, traditional Monte Carlo localization based on occupancy grid maps is considered the gold standard, but its accuracy is limited by the representation capabilities of the occupancy grid map. In this paper, we address the problem of building an effective map representation that allows to accurately perform probabilistic global localization. To this end, we propose an implicit neural map representation that is able to capture positional and directional geometric features from 2D LiDAR scans to efficiently represent the environment and learn a neural network that is able to predict both, the non-projective signed distance and a direction-aware projective distance for an arbitrary point in the mapped environment. This combination of neural map representation with a light-weight neural network allows us to design an efficient observation model within a conventional Monte Carlo localization framework for pose estimation of a robot in real time. We evaluated our approach to indoor localization on a publicly available dataset for global localization and the experimental results indicate that our approach is able to more accurately localize a mobile robot than other localization approaches employing occupancy or existing neural map representations. In contrast to other approaches employing an implicit neural map representation for 2D LiDAR localization, our approach allows to perform real-time pose tracking after convergence and near real-time global localization. The code of our approach is available at: https://github.com/PRBonn/enm-mcl.
Towards Generating Realistic 3D Semantic Training Data for Autonomous Driving
Mar 27, 2025



Semantic scene understanding is crucial for robotics and computer vision applications. In autonomous driving, 3D semantic segmentation plays an important role for enabling safe navigation. Despite significant advances in the field, the complexity of collecting and annotating 3D data is a bottleneck in this developments. To overcome that data annotation limitation, synthetic simulated data has been used to generate annotated data on demand. There is still however a domain gap between real and simulated data. More recently, diffusion models have been in the spotlight, enabling close-to-real data synthesis. Those generative models have been recently applied to the 3D data domain for generating scene-scale data with semantic annotations. Still, those methods either rely on image projection or decoupled models trained with different resolutions in a coarse-to-fine manner. Such intermediary representations impact the generated data quality due to errors added in those transformations. In this work, we propose a novel approach able to generate 3D semantic scene-scale data without relying on any projection or decoupled trained multi-resolution models, achieving more realistic semantic scene data generation compared to previous state-of-the-art methods. Besides improving 3D semantic scene-scale data synthesis, we thoroughly evaluate the use of the synthetic scene samples as labeled data to train a semantic segmentation network. In our experiments, we show that using the synthetic annotated data generated by our method as training data together with the real semantic segmentation labels, leads to an improvement in the semantic segmentation model performance. Our results show the potential of generated scene-scale point clouds to generate more training data to extend existing datasets, reducing the data annotation effort. Our code is available at https://github.com/PRBonn/3DiSS.