 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeFM: Learning Foundation Representations from Depth for Robotics
Jan 26, 2026Depth sensors are widely deployed across robotic platforms, and advances in fast, high-fidelity depth simulation have enabled robotic policies trained on depth observations to achieve robust sim-to-real transfer for a wide range of tasks. Despite this, representation learning for depth modality remains underexplored compared to RGB, where large-scale foundation models now define the state of the art. To address this gap, we present DeFM, a self-supervised foundation model trained entirely on depth images for robotic applications. Using a DINO-style self-distillation objective on a curated dataset of 60M depth images, DeFM learns geometric and semantic representations that generalize to diverse environments, tasks, and sensors. To retain metric awareness across multiple scales, we introduce a novel input normalization strategy. We further distill DeFM into compact models suitable for resource-constrained robotic systems. When evaluated on depth-based classification, segmentation, navigation, locomotion, and manipulation benchmarks, DeFM achieves state-of-the-art performance and demonstrates strong generalization from simulation to real-world environments. We release all our pretrained models, which can be adopted off-the-shelf for depth-based robotic learning without task-specific fine-tuning. Webpage: https://de-fm.github.io/
Large-Scale Autonomous Gas Monitoring for Volcanic Environments: A Legged Robot on Mount Etna
Jan 12, 2026Volcanic gas emissions are key precursors of eruptive activity. Yet, obtaining accurate near-surface measurements remains hazardous and logistically challenging, motivating the need for autonomous solutions. Limited mobility in rough volcanic terrain has prevented wheeled systems from performing reliable in situ gas measurements, reducing their usefulness as sensing platforms. We present a legged robotic system for autonomous volcanic gas analysis, utilizing the quadruped ANYmal, equipped with a quadrupole mass spectrometer system. Our modular autonomy stack integrates a mission planning interface, global planner, localization framework, and terrain-aware local navigation. We evaluated the system on Mount Etna across three autonomous missions in varied terrain, achieving successful gas-source detections with autonomy rates of 93-100%. In addition, we conducted a teleoperated mission in which the robot measured natural fumaroles, detecting sulfur dioxide and carbon dioxide. We discuss lessons learned from the gas-analysis and autonomy perspectives, emphasizing the need for adaptive sensing strategies, tighter integration of global and local planning, and improved hardware design.
SAHA: Supervised Autonomous HArvester for selective forest thinning
Jan 03, 2026Forestry plays a vital role in our society, creating significant ecological, economic, and recreational value. Efficient forest management involves labor-intensive and complex operations. One essential task for maintaining forest health and productivity is selective thinning, which requires skilled operators to remove specific trees to create optimal growing conditions for the remaining ones. In this work, we present a solution based on a small-scale robotic harvester (SAHA) designed for executing this task with supervised autonomy. We build on a 4.5-ton harvester platform and implement key hardware modifications for perception and automatic control. We implement learning- and model-based approaches for precise control of hydraulic actuators, accurate navigation through cluttered environments, robust state estimation, and reliable semantic estimation of terrain traversability. Integrating state-of-the-art techniques in perception, planning, and control, our robotic harvester can autonomously navigate forest environments and reach targeted trees for selective thinning. We present experimental results from extensive field trials over kilometer-long autonomous missions in northern European forests, demonstrating the harvester's ability to operate in real forests. We analyze the performance and provide the lessons learned for advancing robotic forest management.
NaviTrace: Evaluating Embodied Navigation of Vision-Language Models
Oct 30, 2025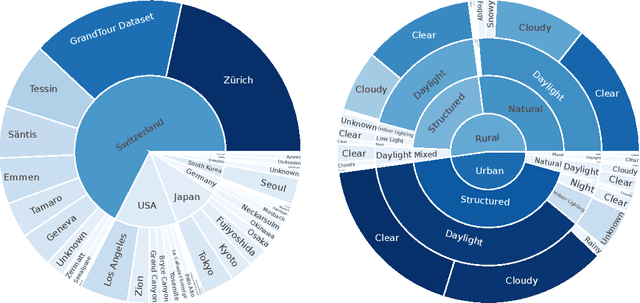
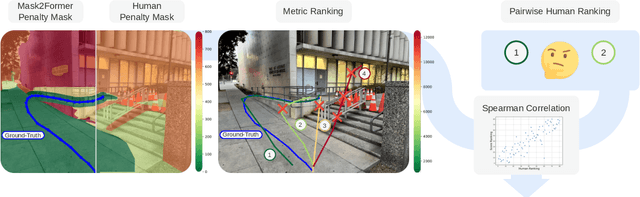
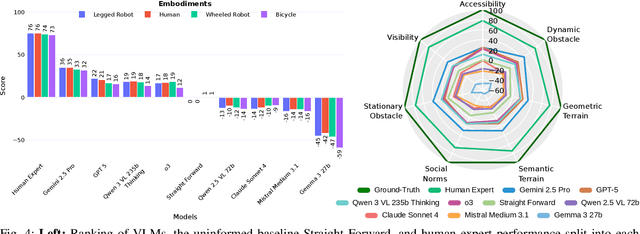
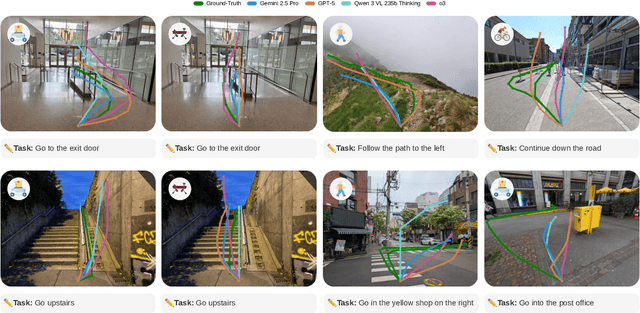
Vision-language models demonstrate unprecedented performance and generalization across a wide range of tasks and scenarios. Integrating these foundation models into robotic navigation systems opens pathways toward building general-purpose robots. Yet, evaluating these models' navigation capabilities remains constrained by costly real-world trials, overly simplified simulations, and limited benchmarks. We introduce NaviTrace, a high-quality Visual Question Answering benchmark where a model receives an instruction and embodiment type (human, legged robot, wheeled robot, bicycle) and must output a 2D navigation trace in image space. Across 1000 scenarios and more than 3000 expert traces, we systematically evaluate eight state-of-the-art VLMs using a newly introduced semantic-aware trace score. This metric combines Dynamic Time Warping distance, goal endpoint error, and embodiment-conditioned penalties derived from per-pixel semantics and correlates with human preferences. Our evaluation reveals consistent gap to human performance caused by poor spatial grounding and goal localization. NaviTrace establishes a scalable and reproducible benchmark for real-world robotic navigation. The benchmark and leaderboard can be found at https://leggedrobotics.github.io/navitrace_webpage/.
Improving Long-Range Navigation with Spatially-Enhanced Recurrent Memory via End-to-End Reinforcement Learning
Jun 06, 2025



Recent advancements in robot navigation, especially with end-to-end learning approaches like reinforcement learning (RL), have shown remarkable efficiency and effectiveness. Yet, successful navigation still relies on two key capabilities: mapping and planning, whether explicit or implicit. Classical approaches use explicit mapping pipelines to register ego-centric observations into a coherent map frame for the planner. In contrast, end-to-end learning achieves this implicitly, often through recurrent neural networks (RNNs) that fuse current and past observations into a latent space for planning. While architectures such as LSTM and GRU capture temporal dependencies, our findings reveal a key limitation: their inability to perform effective spatial memorization. This skill is essential for transforming and integrating sequential observations from varying perspectives to build spatial representations that support downstream planning. To address this, we propose Spatially-Enhanced Recurrent Units (SRUs), a simple yet effective modification to existing RNNs, designed to enhance spatial memorization capabilities. We introduce an attention-based architecture with SRUs, enabling long-range navigation using a single forward-facing stereo camera. Regularization techniques are employed to ensure robust end-to-end recurrent training via RL. Experimental results show our approach improves long-range navigation by 23.5% compared to existing RNNs. Furthermore, with SRU memory, our method outperforms the RL baseline with explicit mapping and memory modules, achieving a 29.6% improvement in diverse environments requiring long-horizon mapping and memorization. Finally, we address the sim-to-real gap by leveraging large-scale pretraining on synthetic depth data, enabling zero-shot transfer to diverse and complex real-world environments.
TartanGround: A Large-Scale Dataset for Ground Robot Perception and Navigation
May 15, 2025We present TartanGround, a large-scale, multi-modal dataset to advance the perception and autonomy of ground robots operating in diverse environments. This dataset, collected in various photorealistic simulation environments includes multiple RGB stereo cameras for 360-degree coverage, along with depth, optical flow, stereo disparity, LiDAR point clouds, ground truth poses, semantic segmented images, and occupancy maps with semantic labels. Data is collected using an integrated automatic pipeline, which generates trajectories mimicking the motion patterns of various ground robot platforms, including wheeled and legged robots. We collect 910 trajectories across 70 environments, resulting in 1.5 million samples. Evaluations on occupancy prediction and SLAM tasks reveal that state-of-the-art methods trained on existing datasets struggle to generalize across diverse scenes. TartanGround can serve as a testbed for training and evaluation of a broad range of learning-based tasks, including occupancy prediction, SLAM, neural scene representation, perception-based navigation, and more, enabling advancements in robotic perception and autonomy towards achieving robust models generalizable to more diverse scenarios. The dataset and codebase for data collection will be made publicly available upon acceptance. Webpage: https://tartanair.org/tartanground
Learned Perceptive Forward Dynamics Model for Safe and Platform-aware Robotic Navigation
Apr 29, 2025
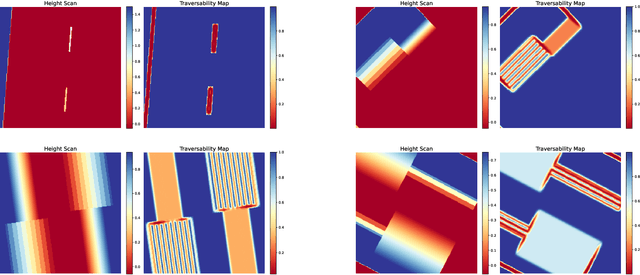
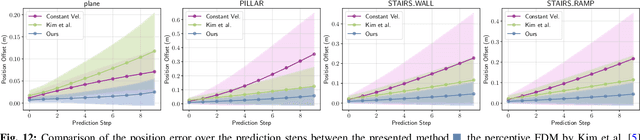
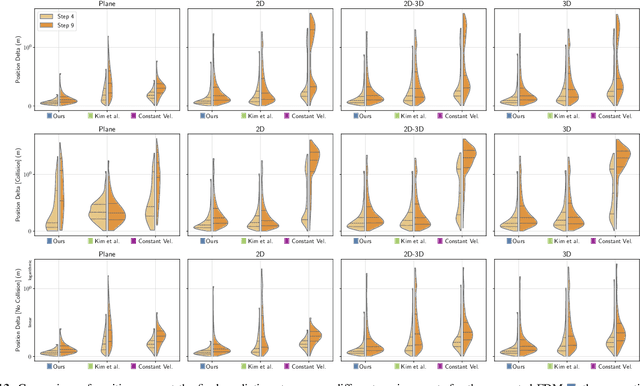
Ensuring safe navigation in complex environments requires accurate real-time traversability assessment and understanding of environmental interactions relative to the robot`s capabilities. Traditional methods, which assume simplified dynamics, often require designing and tuning cost functions to safely guide paths or actions toward the goal. This process is tedious, environment-dependent, and not generalizable. To overcome these issues, we propose a novel learned perceptive Forward Dynamics Model (FDM) that predicts the robot`s future state conditioned on the surrounding geometry and history of proprioceptive measurements, proposing a more scalable, safer, and heuristic-free solution. The FDM is trained on multiple years of simulated navigation experience, including high-risk maneuvers, and real-world interactions to incorporate the full system dynamics beyond rigid body simulation. We integrate our perceptive FDM into a zero-shot Model Predictive Path Integral (MPPI) planning framework, leveraging the learned mapping between actions, future states, and failure probability. This allows for optimizing a simplified cost function, eliminating the need for extensive cost-tuning to ensure safety. On the legged robot ANYmal, the proposed perceptive FDM improves the position estimation by on average 41% over competitive baselines, which translates into a 27% higher navigation success rate in rough simulation environments. Moreover, we demonstrate effective sim-to-real transfer and showcase the benefit of training on synthetic and real data. Code and models are made publicly available under https://github.com/leggedrobotics/fdm.
Boxi: Design Decisions in the Context of Algorithmic Performance for Robotics
Apr 25, 2025Achieving robust autonomy in mobile robots operating in complex and unstructured environments requires a multimodal sensor suite capable of capturing diverse and complementary information. However, designing such a sensor suite involves multiple critical design decisions, such as sensor selection, component placement, thermal and power limitations, compute requirements, networking, synchronization, and calibration. While the importance of these key aspects is widely recognized, they are often overlooked in academia or retained as proprietary knowledge within large corporations. To improve this situation, we present Boxi, a tightly integrated sensor payload that enables robust autonomy of robots in the wild. This paper discusses the impact of payload design decisions made to optimize algorithmic performance for downstream tasks, specifically focusing on state estimation and mapping. Boxi is equipped with a variety of sensors: two LiDARs, 10 RGB cameras including high-dynamic range, global shutter, and rolling shutter models, an RGB-D camera, 7 inertial measurement units (IMUs) of varying precision, and a dual antenna RTK GNSS system. Our analysis shows that time synchronization, calibration, and sensor modality have a crucial impact on the state estimation performance. We frame this analysis in the context of cost considerations and environment-specific challenges. We also present a mobile sensor suite `cookbook` to serve as a comprehensive guideline, highlighting generalizable key design considerations and lessons learned during the development of Boxi. Finally, we demonstrate the versatility of Boxi being used in a variety of applications in real-world scenarios, contributing to robust autonomy. More details and code: https://github.com/leggedrobotics/grand_tour_box
Holistic Fusion: Task- and Setup-Agnostic Robot Localization and State Estimation with Factor Graphs
Apr 08, 2025Seamless operation of mobile robots in challenging environments requires low-latency local motion estimation (e.g., dynamic maneuvers) and accurate global localization (e.g., wayfinding). While most existing sensor-fusion approaches are designed for specific scenarios, this work introduces a flexible open-source solution for task- and setup-agnostic multimodal sensor fusion that is distinguished by its generality and usability. Holistic Fusion formulates sensor fusion as a combined estimation problem of i) the local and global robot state and ii) a (theoretically unlimited) number of dynamic context variables, including automatic alignment of reference frames; this formulation fits countless real-world applications without any conceptual modifications. The proposed factor-graph solution enables the direct fusion of an arbitrary number of absolute, local, and landmark measurements expressed with respect to different reference frames by explicitly including them as states in the optimization and modeling their evolution as random walks. Moreover, local smoothness and consistency receive particular attention to prevent jumps in the robot state belief. HF enables low-latency and smooth online state estimation on typical robot hardware while simultaneously providing low-drift global localization at the IMU measurement rate. The efficacy of this released framework is demonstrated in five real-world scenarios on three robotic platforms, each with distinct task requirements.
Event-based Civil Infrastructure Visual Defect Detection: ev-CIVIL Dataset and Benchmark
Apr 08, 2025Small Unmanned Aerial Vehicle (UAV) based visual inspections are a more efficient alternative to manual methods for examining civil structural defects, offering safe access to hazardous areas and significant cost savings by reducing labor requirements. However, traditional frame-based cameras, widely used in UAV-based inspections, often struggle to capture defects under low or dynamic lighting conditions. In contrast, Dynamic Vision Sensors (DVS), or event-based cameras, excel in such scenarios by minimizing motion blur, enhancing power efficiency, and maintaining high-quality imaging across diverse lighting conditions without saturation or information loss. Despite these advantages, existing research lacks studies exploring the feasibility of using DVS for detecting civil structural defects.Moreover, there is no dedicated event-based dataset tailored for this purpose. Addressing this gap, this study introduces the first event-based civil infrastructure defect detection dataset, capturing defective surfaces as a spatio-temporal event stream using DVS.In addition to event-based data, the dataset includes grayscale intensity image frames captured simultaneously using an Active Pixel Sensor (APS). Both data types were collected using the DAVIS346 camera, which integrates DVS and APS sensors.The dataset focuses on two types of defects: cracks and spalling, and includes data from both field and laboratory environments. The field dataset comprises 318 recording sequences,documenting 458 distinct cracks and 121 distinct spalling instances.The laboratory dataset includes 362 recording sequences, covering 220 distinct cracks and 308 spalling instances.Four realtime object detection models were evaluated on it to validate the dataset effectiveness.The results demonstrate the dataset robustness in enabling accurate defect detection and classification,even under challenging lighting conditions.