 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIsaac Lab: A GPU-Accelerated Simulation Framework for Multi-Modal Robot Learning
Nov 06, 2025



We present Isaac Lab, the natural successor to Isaac Gym, which extends the paradigm of GPU-native robotics simulation into the era of large-scale multi-modal learning. Isaac Lab combines high-fidelity GPU parallel physics, photorealistic rendering, and a modular, composable architecture for designing environments and training robot policies. Beyond physics and rendering, the framework integrates actuator models, multi-frequency sensor simulation, data collection pipelines, and domain randomization tools, unifying best practices for reinforcement and imitation learning at scale within a single extensible platform. We highlight its application to a diverse set of challenges, including whole-body control, cross-embodiment mobility, contact-rich and dexterous manipulation, and the integration of human demonstrations for skill acquisition. Finally, we discuss upcoming integration with the differentiable, GPU-accelerated Newton physics engine, which promises new opportunities for scalable, data-efficient, and gradient-based approaches to robot learning. We believe Isaac Lab's combination of advanced simulation capabilities, rich sensing, and data-center scale execution will help unlock the next generation of breakthroughs in robotics research.
Learned Perceptive Forward Dynamics Model for Safe and Platform-aware Robotic Navigation
Apr 29, 2025
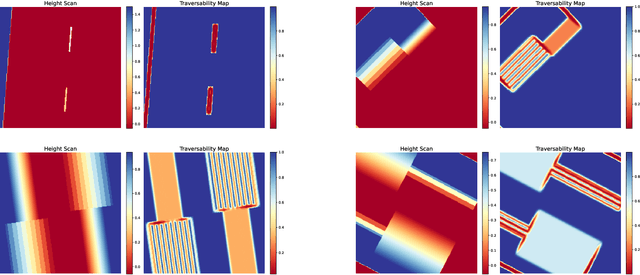
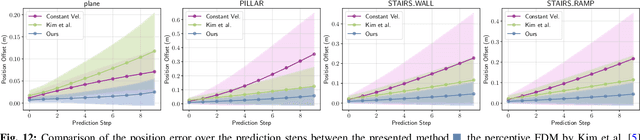
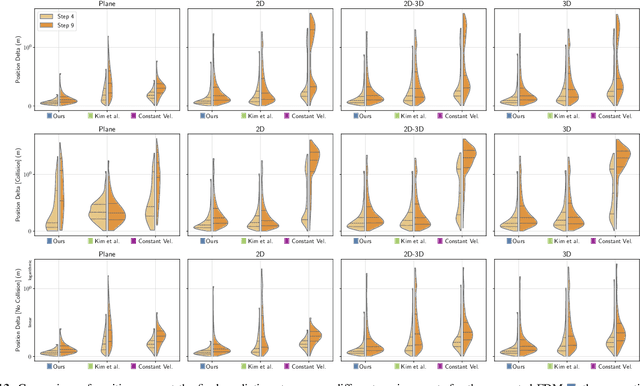
Ensuring safe navigation in complex environments requires accurate real-time traversability assessment and understanding of environmental interactions relative to the robot`s capabilities. Traditional methods, which assume simplified dynamics, often require designing and tuning cost functions to safely guide paths or actions toward the goal. This process is tedious, environment-dependent, and not generalizable. To overcome these issues, we propose a novel learned perceptive Forward Dynamics Model (FDM) that predicts the robot`s future state conditioned on the surrounding geometry and history of proprioceptive measurements, proposing a more scalable, safer, and heuristic-free solution. The FDM is trained on multiple years of simulated navigation experience, including high-risk maneuvers, and real-world interactions to incorporate the full system dynamics beyond rigid body simulation. We integrate our perceptive FDM into a zero-shot Model Predictive Path Integral (MPPI) planning framework, leveraging the learned mapping between actions, future states, and failure probability. This allows for optimizing a simplified cost function, eliminating the need for extensive cost-tuning to ensure safety. On the legged robot ANYmal, the proposed perceptive FDM improves the position estimation by on average 41% over competitive baselines, which translates into a 27% higher navigation success rate in rough simulation environments. Moreover, we demonstrate effective sim-to-real transfer and showcase the benefit of training on synthetic and real data. Code and models are made publicly available under https://github.com/leggedrobotics/fdm.
ETHcavation: A Dataset and Pipeline for Panoptic Scene Understanding and Object Tracking in Dynamic Construction Environments
Oct 05, 2024



Construction sites are challenging environments for autonomous systems due to their unstructured nature and the presence of dynamic actors, such as workers and machinery. This work presents a comprehensive panoptic scene understanding solution designed to handle the complexities of such environments by integrating 2D panoptic segmentation with 3D LiDAR mapping. Our system generates detailed environmental representations in real-time by combining semantic and geometric data, supported by Kalman Filter-based tracking for dynamic object detection. We introduce a fine-tuning method that adapts large pre-trained panoptic segmentation models for construction site applications using a limited number of domain-specific samples. For this use case, we release a first-of-its-kind dataset of 502 hand-labeled sample images with panoptic annotations from construction sites. In addition, we propose a dynamic panoptic mapping technique that enhances scene understanding in unstructured environments. As a case study, we demonstrate the system's application for autonomous navigation, utilizing real-time RRT* for reactive path planning in dynamic scenarios. The dataset (https://leggedrobotics.github.io/panoptic-scene-understanding.github.io/) and code (https://github.com/leggedrobotics/rsl_panoptic_mapping) for training and deployment are publicly available to support future research.
ViPlanner: Visual Semantic Imperative Learning for Local Navigation
Oct 02, 2023



Real-time path planning in outdoor environments still challenges modern robotic systems due to differences in terrain traversability, diverse obstacles, and the necessity for fast decision-making. Established approaches have primarily focused on geometric navigation solutions, which work well for structured geometric obstacles but have limitations regarding the semantic interpretation of different terrain types and their affordances. Moreover, these methods fail to identify traversable geometric occurrences, such as stairs. To overcome these issues, we introduce ViPlanner, a learned local path planning approach that generates local plans based on geometric and semantic information. The system is trained using the Imperative Learning paradigm, for which the network weights are optimized end-to-end based on the planning task objective. This optimization uses a differentiable formulation of a semantic costmap, which enables the planner to distinguish between the traversability of different terrains and accurately identify obstacles. The semantic information is represented in 30 classes using an RGB colorspace that can effectively encode the multiple levels of traversability. We show that the planner can adapt to diverse real-world environments without requiring any real-world training. In fact, the planner is trained purely in simulation, enabling a highly scalable training data generation. Experimental results demonstrate resistance to noise, zero-shot sim-to-real transfer, and a decrease of 38.02% in terms of traversability cost compared to purely geometric-based approaches. Code and models are made publicly available: https://github.com/leggedrobotics/viplanner.