 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeViserDex: Visual Sim-to-Real for Robust Dexterous In-hand Reorientation
Apr 13, 2026In-hand object reorientation requires precise estimation of the object pose to handle complex task dynamics. While RGB sensing offers rich semantic cues for pose tracking, existing solutions rely on multi-camera setups or costly ray tracing. We present a sim-to-real framework for monocular RGB in-hand reorientation that integrates 3D Gaussian Splatting (3DGS) to bridge the visual sim-to-real gap. Our key insight is performing domain randomization in the Gaussian representation space: by applying physically consistent, pre-rendering augmentations to 3D Gaussians, we generate photorealistic, randomized visual data for object pose estimation. The manipulation policy is trained using curriculum-based reinforcement learning with teacher-student distillation, enabling efficient learning of complex behaviors. Importantly, both perception and control models can be trained independently on consumer-grade hardware, eliminating the need for large compute clusters. Experiments show that the pose estimator trained with 3DGS data outperforms those trained using conventional rendering data in challenging visual environments. We validate the system on a physical multi-fingered hand equipped with an RGB camera, demonstrating robust reorientation of five diverse objects even under challenging lighting conditions. Our results highlight Gaussian splatting as a practical path for RGB-only dexterous manipulation. For videos of the hardware deployments and additional supplementary materials, please refer to the project website: https://rffr.leggedrobotics.com/works/viserdex/
DeFM: Learning Foundation Representations from Depth for Robotics
Jan 26, 2026Depth sensors are widely deployed across robotic platforms, and advances in fast, high-fidelity depth simulation have enabled robotic policies trained on depth observations to achieve robust sim-to-real transfer for a wide range of tasks. Despite this, representation learning for depth modality remains underexplored compared to RGB, where large-scale foundation models now define the state of the art. To address this gap, we present DeFM, a self-supervised foundation model trained entirely on depth images for robotic applications. Using a DINO-style self-distillation objective on a curated dataset of 60M depth images, DeFM learns geometric and semantic representations that generalize to diverse environments, tasks, and sensors. To retain metric awareness across multiple scales, we introduce a novel input normalization strategy. We further distill DeFM into compact models suitable for resource-constrained robotic systems. When evaluated on depth-based classification, segmentation, navigation, locomotion, and manipulation benchmarks, DeFM achieves state-of-the-art performance and demonstrates strong generalization from simulation to real-world environments. We release all our pretrained models, which can be adopted off-the-shelf for depth-based robotic learning without task-specific fine-tuning. Webpage: https://de-fm.github.io/
Isaac Lab: A GPU-Accelerated Simulation Framework for Multi-Modal Robot Learning
Nov 06, 2025



We present Isaac Lab, the natural successor to Isaac Gym, which extends the paradigm of GPU-native robotics simulation into the era of large-scale multi-modal learning. Isaac Lab combines high-fidelity GPU parallel physics, photorealistic rendering, and a modular, composable architecture for designing environments and training robot policies. Beyond physics and rendering, the framework integrates actuator models, multi-frequency sensor simulation, data collection pipelines, and domain randomization tools, unifying best practices for reinforcement and imitation learning at scale within a single extensible platform. We highlight its application to a diverse set of challenges, including whole-body control, cross-embodiment mobility, contact-rich and dexterous manipulation, and the integration of human demonstrations for skill acquisition. Finally, we discuss upcoming integration with the differentiable, GPU-accelerated Newton physics engine, which promises new opportunities for scalable, data-efficient, and gradient-based approaches to robot learning. We believe Isaac Lab's combination of advanced simulation capabilities, rich sensing, and data-center scale execution will help unlock the next generation of breakthroughs in robotics research.
Divide, Discover, Deploy: Factorized Skill Learning with Symmetry and Style Priors
Aug 27, 2025Unsupervised Skill Discovery (USD) allows agents to autonomously learn diverse behaviors without task-specific rewards. While recent USD methods have shown promise, their application to real-world robotics remains underexplored. In this paper, we propose a modular USD framework to address the challenges in the safety, interpretability, and deployability of the learned skills. Our approach employs user-defined factorization of the state space to learn disentangled skill representations. It assigns different skill discovery algorithms to each factor based on the desired intrinsic reward function. To encourage structured morphology-aware skills, we introduce symmetry-based inductive biases tailored to individual factors. We also incorporate a style factor and regularization penalties to promote safe and robust behaviors. We evaluate our framework in simulation using a quadrupedal robot and demonstrate zero-shot transfer of the learned skills to real hardware. Our results show that factorization and symmetry lead to the discovery of structured human-interpretable behaviors, while the style factor and penalties enhance safety and diversity. Additionally, we show that the learned skills can be used for downstream tasks and perform on par with oracle policies trained with hand-crafted rewards.
SonoGym: High Performance Simulation for Challenging Surgical Tasks with Robotic Ultrasound
Jul 01, 2025Ultrasound (US) is a widely used medical imaging modality due to its real-time capabilities, non-invasive nature, and cost-effectiveness. Robotic ultrasound can further enhance its utility by reducing operator dependence and improving access to complex anatomical regions. For this, while deep reinforcement learning (DRL) and imitation learning (IL) have shown potential for autonomous navigation, their use in complex surgical tasks such as anatomy reconstruction and surgical guidance remains limited -- largely due to the lack of realistic and efficient simulation environments tailored to these tasks. We introduce SonoGym, a scalable simulation platform for complex robotic ultrasound tasks that enables parallel simulation across tens to hundreds of environments. Our framework supports realistic and real-time simulation of US data from CT-derived 3D models of the anatomy through both a physics-based and a generative modeling approach. Sonogym enables the training of DRL and recent IL agents (vision transformers and diffusion policies) for relevant tasks in robotic orthopedic surgery by integrating common robotic platforms and orthopedic end effectors. We further incorporate submodular DRL -- a recent method that handles history-dependent rewards -- for anatomy reconstruction and safe reinforcement learning for surgery. Our results demonstrate successful policy learning across a range of scenarios, while also highlighting the limitations of current methods in clinically relevant environments. We believe our simulation can facilitate research in robot learning approaches for such challenging robotic surgery applications. Dataset, codes, and videos are publicly available at https://sonogym.github.io/.
Dynamic object goal pushing with mobile manipulators through model-free constrained reinforcement learning
Feb 03, 2025Non-prehensile pushing to move and reorient objects to a goal is a versatile loco-manipulation skill. In the real world, the object's physical properties and friction with the floor contain significant uncertainties, which makes the task challenging for a mobile manipulator. In this paper, we develop a learning-based controller for a mobile manipulator to move an unknown object to a desired position and yaw orientation through a sequence of pushing actions. The proposed controller for the robotic arm and the mobile base motion is trained using a constrained Reinforcement Learning (RL) formulation. We demonstrate its capability in experiments with a quadrupedal robot equipped with an arm. The learned policy achieves a success rate of 91.35% in simulation and at least 80% on hardware in challenging scenarios. Through our extensive hardware experiments, we show that the approach demonstrates high robustness against unknown objects of different masses, materials, sizes, and shapes. It reactively discovers the pushing location and direction, thus achieving contact-rich behavior while observing only the pose of the object. Additionally, we demonstrate the adaptive behavior of the learned policy towards preventing the object from toppling.
Guided Reinforcement Learning for Robust Multi-Contact Loco-Manipulation
Oct 17, 2024
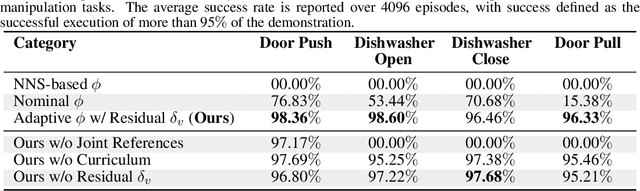
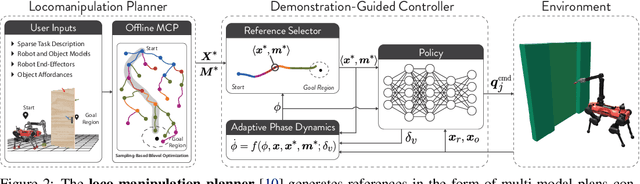

Reinforcement learning (RL) often necessitates a meticulous Markov Decision Process (MDP) design tailored to each task. This work aims to address this challenge by proposing a systematic approach to behavior synthesis and control for multi-contact loco-manipulation tasks, such as navigating spring-loaded doors and manipulating heavy dishwashers. We define a task-independent MDP to train RL policies using only a single demonstration per task generated from a model-based trajectory optimizer. Our approach incorporates an adaptive phase dynamics formulation to robustly track the demonstrations while accommodating dynamic uncertainties and external disturbances. We compare our method against prior motion imitation RL works and show that the learned policies achieve higher success rates across all considered tasks. These policies learn recovery maneuvers that are not present in the demonstration, such as re-grasping objects during execution or dealing with slippages. Finally, we successfully transfer the policies to a real robot, demonstrating the practical viability of our approach.
Whole-body end-effector pose tracking
Sep 24, 2024
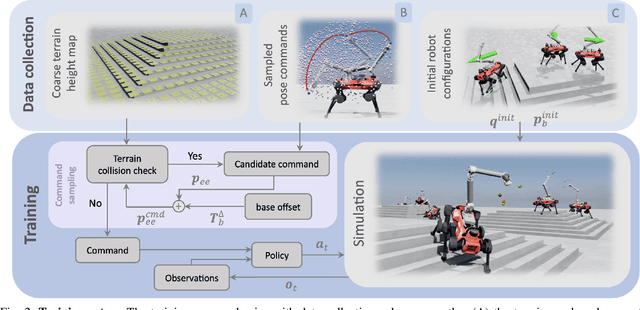

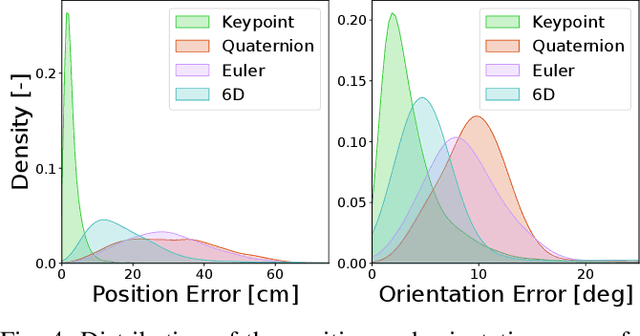
Combining manipulation with the mobility of legged robots is essential for a wide range of robotic applications. However, integrating an arm with a mobile base significantly increases the system's complexity, making precise end-effector control challenging. Existing model-based approaches are often constrained by their modeling assumptions, leading to limited robustness. Meanwhile, recent Reinforcement Learning (RL) implementations restrict the arm's workspace to be in front of the robot or track only the position to obtain decent tracking accuracy. In this work, we address these limitations by introducing a whole-body RL formulation for end-effector pose tracking in a large workspace on rough, unstructured terrains. Our proposed method involves a terrain-aware sampling strategy for the robot's initial configuration and end-effector pose commands, as well as a game-based curriculum to extend the robot's operating range. We validate our approach on the ANYmal quadrupedal robot with a six DoF robotic arm. Through our experiments, we show that the learned controller achieves precise command tracking over a large workspace and adapts across varying terrains such as stairs and slopes. On deployment, it achieves a pose-tracking error of 2.64 cm and 3.64 degrees, outperforming existing competitive baselines.
Perceptive Pedipulation with Local Obstacle Avoidance
Sep 11, 2024



Pedipulation leverages the feet of legged robots for mobile manipulation, eliminating the need for dedicated robotic arms. While previous works have showcased blind and task-specific pedipulation skills, they fail to account for static and dynamic obstacles in the environment. To address this limitation, we introduce a reinforcement learning-based approach to train a whole-body obstacle-aware policy that tracks foot position commands while simultaneously avoiding obstacles. Despite training the policy in only five different static scenarios in simulation, we show that it generalizes to unknown environments with different numbers and types of obstacles. We analyze the performance of our method through a set of simulation experiments and successfully deploy the learned policy on the ANYmal quadruped, demonstrating its capability to follow foot commands while navigating around static and dynamic obstacles.
ORBIT-Surgical: An Open-Simulation Framework for Learning Surgical Augmented Dexterity
Apr 24, 2024



Physics-based simulations have accelerated progress in robot learning for driving, manipulation, and locomotion. Yet, a fast, accurate, and robust surgical simulation environment remains a challenge. In this paper, we present ORBIT-Surgical, a physics-based surgical robot simulation framework with photorealistic rendering in NVIDIA Omniverse. We provide 14 benchmark surgical tasks for the da Vinci Research Kit (dVRK) and Smart Tissue Autonomous Robot (STAR) which represent common subtasks in surgical training. ORBIT-Surgical leverages GPU parallelization to train reinforcement learning and imitation learning algorithms to facilitate study of robot learning to augment human surgical skills. ORBIT-Surgical also facilitates realistic synthetic data generation for active perception tasks. We demonstrate ORBIT-Surgical sim-to-real transfer of learned policies onto a physical dVRK robot. Project website: orbit-surgical.github.io