 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGuided Reinforcement Learning for Robust Multi-Contact Loco-Manipulation
Paper and Code

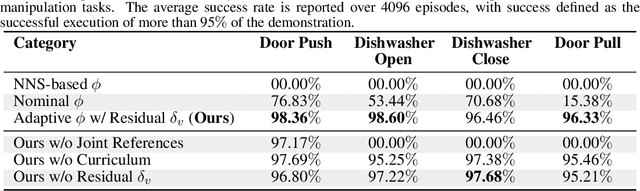
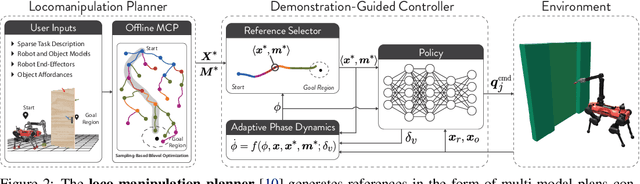

Reinforcement learning (RL) often necessitates a meticulous Markov Decision Process (MDP) design tailored to each task. This work aims to address this challenge by proposing a systematic approach to behavior synthesis and control for multi-contact loco-manipulation tasks, such as navigating spring-loaded doors and manipulating heavy dishwashers. We define a task-independent MDP to train RL policies using only a single demonstration per task generated from a model-based trajectory optimizer. Our approach incorporates an adaptive phase dynamics formulation to robustly track the demonstrations while accommodating dynamic uncertainties and external disturbances. We compare our method against prior motion imitation RL works and show that the learned policies achieve higher success rates across all considered tasks. These policies learn recovery maneuvers that are not present in the demonstration, such as re-grasping objects during execution or dealing with slippages. Finally, we successfully transfer the policies to a real robot, demonstrating the practical viability of our approach.