 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIn-Context Imitation Learning via Next-Token Prediction
Aug 28, 2024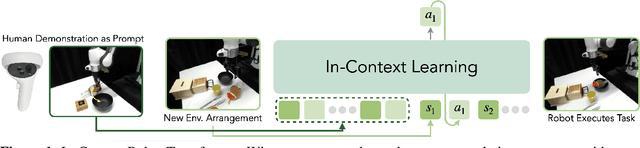
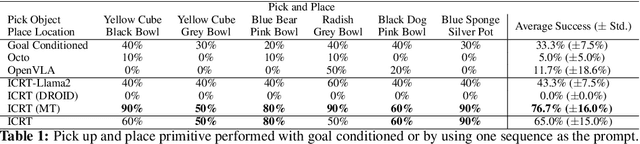
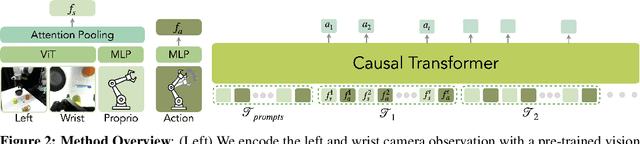
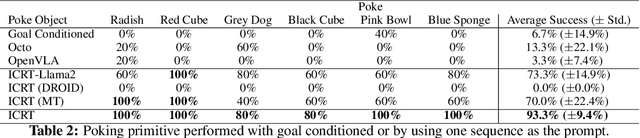
We explore how to enhance next-token prediction models to perform in-context imitation learning on a real robot, where the robot executes new tasks by interpreting contextual information provided during the input phase, without updating its underlying policy parameters. We propose In-Context Robot Transformer (ICRT), a causal transformer that performs autoregressive prediction on sensorimotor trajectories without relying on any linguistic data or reward function. This formulation enables flexible and training-free execution of new tasks at test time, achieved by prompting the model with sensorimotor trajectories of the new task composing of image observations, actions and states tuples, collected through human teleoperation. Experiments with a Franka Emika robot demonstrate that the ICRT can adapt to new tasks specified by prompts, even in environment configurations that differ from both the prompt and the training data. In a multitask environment setup, ICRT significantly outperforms current state-of-the-art next-token prediction models in robotics on generalizing to unseen tasks. Code, checkpoints and data are available on https://icrt.dev/
SuFIA: Language-Guided Augmented Dexterity for Robotic Surgical Assistants
May 08, 2024



In this work, we present SuFIA, the first framework for natural language-guided augmented dexterity for robotic surgical assistants. SuFIA incorporates the strong reasoning capabilities of large language models (LLMs) with perception modules to implement high-level planning and low-level control of a robot for surgical sub-task execution. This enables a learning-free approach to surgical augmented dexterity without any in-context examples or motion primitives. SuFIA uses a human-in-the-loop paradigm by restoring control to the surgeon in the case of insufficient information, mitigating unexpected errors for mission-critical tasks. We evaluate SuFIA on four surgical sub-tasks in a simulation environment and two sub-tasks on a physical surgical robotic platform in the lab, demonstrating its ability to perform common surgical sub-tasks through supervised autonomous operation under challenging physical and workspace conditions. Project website: orbit-surgical.github.io/sufia
ORBIT-Surgical: An Open-Simulation Framework for Learning Surgical Augmented Dexterity
Apr 24, 2024



Physics-based simulations have accelerated progress in robot learning for driving, manipulation, and locomotion. Yet, a fast, accurate, and robust surgical simulation environment remains a challenge. In this paper, we present ORBIT-Surgical, a physics-based surgical robot simulation framework with photorealistic rendering in NVIDIA Omniverse. We provide 14 benchmark surgical tasks for the da Vinci Research Kit (dVRK) and Smart Tissue Autonomous Robot (STAR) which represent common subtasks in surgical training. ORBIT-Surgical leverages GPU parallelization to train reinforcement learning and imitation learning algorithms to facilitate study of robot learning to augment human surgical skills. ORBIT-Surgical also facilitates realistic synthetic data generation for active perception tasks. We demonstrate ORBIT-Surgical sim-to-real transfer of learned policies onto a physical dVRK robot. Project website: orbit-surgical.github.io
A Touch, Vision, and Language Dataset for Multimodal Alignment
Feb 20, 2024Touch is an important sensing modality for humans, but it has not yet been incorporated into a multimodal generative language model. This is partially due to the difficulty of obtaining natural language labels for tactile data and the complexity of aligning tactile readings with both visual observations and language descriptions. As a step towards bridging that gap, this work introduces a new dataset of 44K in-the-wild vision-touch pairs, with English language labels annotated by humans (10%) and textual pseudo-labels from GPT-4V (90%). We use this dataset to train a vision-language-aligned tactile encoder for open-vocabulary classification and a touch-vision-language (TVL) model for text generation using the trained encoder. Results suggest that by incorporating touch, the TVL model improves (+29% classification accuracy) touch-vision-language alignment over existing models trained on any pair of those modalities. Although only a small fraction of the dataset is human-labeled, the TVL model demonstrates improved visual-tactile understanding over GPT-4V (+12%) and open-source vision-language models (+32%) on a new touch-vision understanding benchmark. Code and data: https://tactile-vlm.github.io.