 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAutomating Deformable Gasket Assembly
Aug 22, 2024
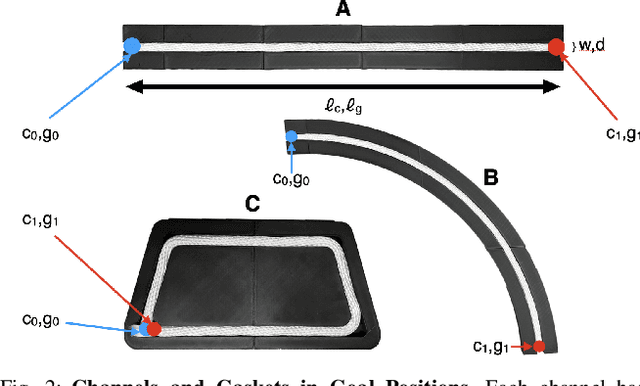
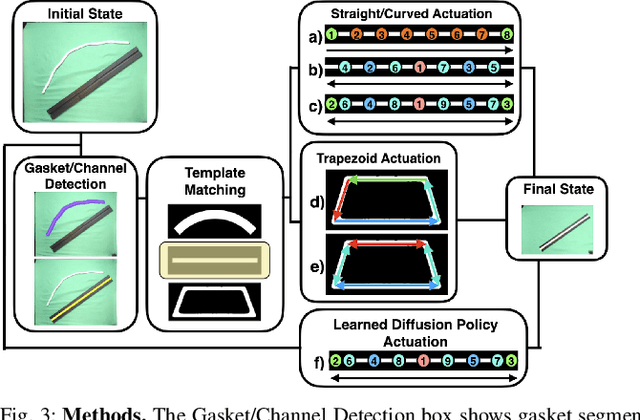

In Gasket Assembly, a deformable gasket must be aligned and pressed into a narrow channel. This task is common for sealing surfaces in the manufacturing of automobiles, appliances, electronics, and other products. Gasket Assembly is a long-horizon, high-precision task and the gasket must align with the channel and be fully pressed in to achieve a secure fit. To compare approaches, we present 4 methods for Gasket Assembly: one policy from deep imitation learning and three procedural algorithms. We evaluate these methods with 100 physical trials. Results suggest that the Binary+ algorithm succeeds in 10/10 on the straight channel whereas the learned policy based on 250 human teleoperated demonstrations succeeds in 8/10 trials and is significantly slower. Code, CAD models, videos, and data can be found at https://berkeleyautomation.github.io/robot-gasket/
DROID: A Large-Scale In-The-Wild Robot Manipulation Dataset
Mar 19, 2024



The creation of large, diverse, high-quality robot manipulation datasets is an important stepping stone on the path toward more capable and robust robotic manipulation policies. However, creating such datasets is challenging: collecting robot manipulation data in diverse environments poses logistical and safety challenges and requires substantial investments in hardware and human labour. As a result, even the most general robot manipulation policies today are mostly trained on data collected in a small number of environments with limited scene and task diversity. In this work, we introduce DROID (Distributed Robot Interaction Dataset), a diverse robot manipulation dataset with 76k demonstration trajectories or 350 hours of interaction data, collected across 564 scenes and 84 tasks by 50 data collectors in North America, Asia, and Europe over the course of 12 months. We demonstrate that training with DROID leads to policies with higher performance and improved generalization ability. We open source the full dataset, policy learning code, and a detailed guide for reproducing our robot hardware setup.
A Touch, Vision, and Language Dataset for Multimodal Alignment
Feb 20, 2024Touch is an important sensing modality for humans, but it has not yet been incorporated into a multimodal generative language model. This is partially due to the difficulty of obtaining natural language labels for tactile data and the complexity of aligning tactile readings with both visual observations and language descriptions. As a step towards bridging that gap, this work introduces a new dataset of 44K in-the-wild vision-touch pairs, with English language labels annotated by humans (10%) and textual pseudo-labels from GPT-4V (90%). We use this dataset to train a vision-language-aligned tactile encoder for open-vocabulary classification and a touch-vision-language (TVL) model for text generation using the trained encoder. Results suggest that by incorporating touch, the TVL model improves (+29% classification accuracy) touch-vision-language alignment over existing models trained on any pair of those modalities. Although only a small fraction of the dataset is human-labeled, the TVL model demonstrates improved visual-tactile understanding over GPT-4V (+12%) and open-source vision-language models (+32%) on a new touch-vision understanding benchmark. Code and data: https://tactile-vlm.github.io.
FogROS2-Sky: Optimizing Latency and Cost for Multi-Cloud Robot Applications
Nov 09, 2023This paper studies the cost-performance tradeoffs in cloud robotics with heterogeneous cloud service providers, which have complex pricing models and varying application requirements. We present FogROS2-Sky, a cost-efficient open source robotics platform that offloads unmodified ROS2 applications to multiple cloud providers and enables fine-grained cost analysis for ROS2 applications' communication with multiple cloud providers. As each provider offers different options for CPU, GPU, memory, and latency, it can be very difficult for users to decide which to choose. FogROS2-Sky includes an optimization algorithm, which either finds the best available hardware specification that fulfills the user's latency and cost constraints or reports that such a specification does not exist. We use FogROS2-Sky to perform time-cost analysis on three robotics applications: visual SLAM, grasp planning, and motion planning. We are able to sample different hardware setups at nearly half the cost while still create cost and latency functions suitable for the optimizer. We also evaluate the optimizer's efficacy for these applications with the Pareto frontier and show that the optimizer selects efficient hardware configurations to balance cost and latency. Videos and code are available on the website https://sites.google.com/view/fogros2-sky