 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSemanticFeels: Semantic Labeling during In-Hand Manipulation
Feb 15, 2026As robots become increasingly integrated into everyday tasks, their ability to perceive both the shape and properties of objects during in-hand manipulation becomes critical for adaptive and intelligent behavior. We present SemanticFeels, an extension of the NeuralFeels framework that integrates semantic labeling with neural implicit shape representation, from vision and touch. To illustrate its application, we focus on material classification: high-resolution Digit tactile readings are processed by a fine-tuned EfficientNet-B0 convolutional neural network (CNN) to generate local material predictions, which are then embedded into an augmented signed distance field (SDF) network that jointly predicts geometry and continuous material regions. Experimental results show that the system achieves a high correspondence between predicted and actual materials on both single- and multi-material objects, with an average matching accuracy of 79.87% across multiple manipulation trials on a multi-material object.
Robot Control Stack: A Lean Ecosystem for Robot Learning at Scale
Sep 18, 2025



Vision-Language-Action models (VLAs) mark a major shift in robot learning. They replace specialized architectures and task-tailored components of expert policies with large-scale data collection and setup-specific fine-tuning. In this machine learning-focused workflow that is centered around models and scalable training, traditional robotics software frameworks become a bottleneck, while robot simulations offer only limited support for transitioning from and to real-world experiments. In this work, we close this gap by introducing Robot Control Stack (RCS), a lean ecosystem designed from the ground up to support research in robot learning with large-scale generalist policies. At its core, RCS features a modular and easily extensible layered architecture with a unified interface for simulated and physical robots, facilitating sim-to-real transfer. Despite its minimal footprint and dependencies, it offers a complete feature set, enabling both real-world experiments and large-scale training in simulation. Our contribution is twofold: First, we introduce the architecture of RCS and explain its design principles. Second, we evaluate its usability and performance along the development cycle of VLA and RL policies. Our experiments also provide an extensive evaluation of Octo, OpenVLA, and Pi Zero on multiple robots and shed light on how simulation data can improve real-world policy performance. Our code, datasets, weights, and videos are available at: https://robotcontrolstack.github.io/
Effective Explanations for Belief-Desire-Intention Robots: When and What to Explain
Jul 02, 2025When robots perform complex and context-dependent tasks in our daily lives, deviations from expectations can confuse users. Explanations of the robot's reasoning process can help users to understand the robot intentions. However, when to provide explanations and what they contain are important to avoid user annoyance. We have investigated user preferences for explanation demand and content for a robot that helps with daily cleaning tasks in a kitchen. Our results show that users want explanations in surprising situations and prefer concise explanations that clearly state the intention behind the confusing action and the contextual factors that were relevant to this decision. Based on these findings, we propose two algorithms to identify surprising actions and to construct effective explanations for Belief-Desire-Intention (BDI) robots. Our algorithms can be easily integrated in the BDI reasoning process and pave the way for better human-robot interaction with context- and user-specific explanations.
Active Perception for Tactile Sensing: A Task-Agnostic Attention-Based Approach
May 09, 2025Humans make extensive use of haptic exploration to map and identify the properties of the objects that we touch. In robotics, active tactile perception has emerged as an important research domain that complements vision for tasks such as object classification, shape reconstruction, and manipulation. This work introduces TAP (Task-agnostic Active Perception) -- a novel framework that leverages reinforcement learning (RL) and transformer-based architectures to address the challenges posed by partially observable environments. TAP integrates Soft Actor-Critic (SAC) and CrossQ algorithms within a unified optimization objective, jointly training a perception module and decision-making policy. By design, TAP is completely task-agnostic and can, in principle, generalize to any active perception problem. We evaluate TAP across diverse tasks, including toy examples and realistic applications involving haptic exploration of 3D models from the Tactile MNIST benchmark. Experiments demonstrate the efficacy of TAP, achieving high accuracies on the Tactile MNIST haptic digit recognition task and a tactile pose estimation task. These findings underscore the potential of TAP as a versatile and generalizable framework for advancing active tactile perception in robotics.
On the Importance of Tactile Sensing for Imitation Learning: A Case Study on Robotic Match Lighting
Apr 18, 2025The field of robotic manipulation has advanced significantly in the last years. At the sensing level, several novel tactile sensors have been developed, capable of providing accurate contact information. On a methodological level, learning from demonstrations has proven an efficient paradigm to obtain performant robotic manipulation policies. The combination of both holds the promise to extract crucial contact-related information from the demonstration data and actively exploit it during policy rollouts. However, despite its potential, it remains an underexplored direction. This work therefore proposes a multimodal, visuotactile imitation learning framework capable of efficiently learning fast and dexterous manipulation policies. We evaluate our framework on the dynamic, contact-rich task of robotic match lighting - a task in which tactile feedback influences human manipulation performance. The experimental results show that adding tactile information into the policies significantly improves performance by over 40%, thereby underlining the importance of tactile sensing for contact-rich manipulation tasks. Project website: https://sites.google.com/view/tactile-il .
Learning to Play Piano in the Real World
Mar 19, 2025



Towards the grand challenge of achieving human-level manipulation in robots, playing piano is a compelling testbed that requires strategic, precise, and flowing movements. Over the years, several works demonstrated hand-designed controllers on real world piano playing, while other works evaluated robot learning approaches on simulated piano scenarios. In this paper, we develop the first piano playing robotic system that makes use of learning approaches while also being deployed on a real world dexterous robot. Specifically, we make use of Sim2Real to train a policy in simulation using reinforcement learning before deploying the learned policy on a real world dexterous robot. In our experiments, we thoroughly evaluate the interplay between domain randomization and the accuracy of the dynamics model used in simulation. Moreover, we evaluate the robot's performance across multiple songs with varying complexity to study the generalization of our learned policy. By providing a proof-of-concept of learning to play piano in the real world, we want to encourage the community to adopt piano playing as a compelling benchmark towards human-level manipulation. We open-source our code and show additional videos at https://lasr.org/research/learning-to-play-piano .
Learning Gentle Grasping Using Vision, Sound, and Touch
Mar 11, 2025



In our daily life, we often encounter objects that are fragile and can be damaged by excessive grasping force, such as fruits. For these objects, it is paramount to grasp gently -- not using the maximum amount of force possible, but rather the minimum amount of force necessary. This paper proposes using visual, tactile, and auditory signals to learn to grasp and regrasp objects stably and gently. Specifically, we use audio signals as an indicator of gentleness during the grasping, and then train end-to-end an action-conditional model from raw visuo-tactile inputs that predicts both the stability and the gentleness of future grasping candidates, thus allowing the selection and execution of the most promising action. Experimental results on a multi-fingered hand over 1,500 grasping trials demonstrated that our model is useful for gentle grasping by validating the predictive performance (3.27\% higher accuracy than the vision-only variant) and providing interpretations of their behavior. Finally, real-world experiments confirmed that the grasping performance with the trained multi-modal model outperformed other baselines (17\% higher rate for stable and gentle grasps than vision-only). Our approach requires neither tactile sensor calibration nor analytical force modeling, drastically reducing the engineering effort to grasp fragile objects. Dataset and videos are available at https://lasr.org/research/gentle-grasping.
From Simple to Complex Skills: The Case of In-Hand Object Reorientation
Jan 09, 2025



Learning policies in simulation and transferring them to the real world has become a promising approach in dexterous manipulation. However, bridging the sim-to-real gap for each new task requires substantial human effort, such as careful reward engineering, hyperparameter tuning, and system identification. In this work, we present a system that leverages low-level skills to address these challenges for more complex tasks. Specifically, we introduce a hierarchical policy for in-hand object reorientation based on previously acquired rotation skills. This hierarchical policy learns to select which low-level skill to execute based on feedback from both the environment and the low-level skill policies themselves. Compared to learning from scratch, the hierarchical policy is more robust to out-of-distribution changes and transfers easily from simulation to real-world environments. Additionally, we propose a generalizable object pose estimator that uses proprioceptive information, low-level skill predictions, and control errors as inputs to estimate the object pose over time. We demonstrate that our system can reorient objects, including symmetrical and textureless ones, to a desired pose.
ManiSkill-ViTac 2025: Challenge on Manipulation Skill Learning With Vision and Tactile Sensing
Nov 19, 2024This article introduces the ManiSkill-ViTac Challenge 2025, which focuses on learning contact-rich manipulation skills using both tactile and visual sensing. Expanding upon the 2024 challenge, ManiSkill-ViTac 2025 includes 3 independent tracks: tactile manipulation, tactile-vision fusion manipulation, and tactile sensor structure design. The challenge aims to push the boundaries of robotic manipulation skills, emphasizing the integration of tactile and visual data to enhance performance in complex, real-world tasks. Participants will be evaluated using standardized metrics across both simulated and real-world environments, spurring innovations in sensor design and significantly advancing the field of vision-tactile fusion in robotics.
Digitizing Touch with an Artificial Multimodal Fingertip
Nov 04, 2024

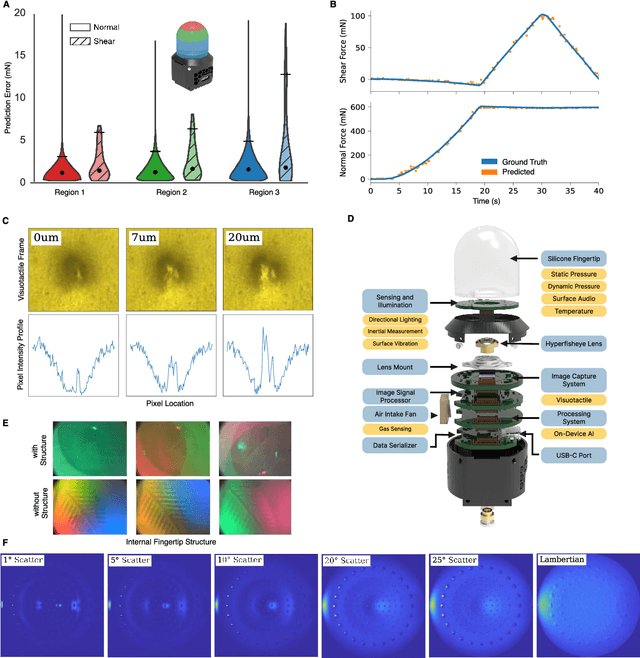

Touch is a crucial sensing modality that provides rich information about object properties and interactions with the physical environment. Humans and robots both benefit from using touch to perceive and interact with the surrounding environment (Johansson and Flanagan, 2009; Li et al., 2020; Calandra et al., 2017). However, no existing systems provide rich, multi-modal digital touch-sensing capabilities through a hemispherical compliant embodiment. Here, we describe several conceptual and technological innovations to improve the digitization of touch. These advances are embodied in an artificial finger-shaped sensor with advanced sensing capabilities. Significantly, this fingertip contains high-resolution sensors (~8.3 million taxels) that respond to omnidirectional touch, capture multi-modal signals, and use on-device artificial intelligence to process the data in real time. Evaluations show that the artificial fingertip can resolve spatial features as small as 7 um, sense normal and shear forces with a resolution of 1.01 mN and 1.27 mN, respectively, perceive vibrations up to 10 kHz, sense heat, and even sense odor. Furthermore, it embeds an on-device AI neural network accelerator that acts as a peripheral nervous system on a robot and mimics the reflex arc found in humans. These results demonstrate the possibility of digitizing touch with superhuman performance. The implications are profound, and we anticipate potential applications in robotics (industrial, medical, agricultural, and consumer-level), virtual reality and telepresence, prosthetics, and e-commerce. Toward digitizing touch at scale, we open-source a modular platform to facilitate future research on the nature of touch.