 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOpen-H-Embodiment: A Large-Scale Dataset for Enabling Foundation Models in Medical Robotics
Apr 22, 2026Autonomous medical robots hold promise to improve patient outcomes, reduce provider workload, democratize access to care, and enable superhuman precision. However, autonomous medical robotics has been limited by a fundamental data problem: existing medical robotic datasets are small, single-embodiment, and rarely shared openly, restricting the development of foundation models that the field needs to advance. We introduce Open-H-Embodiment, the largest open dataset of medical robotic video with synchronized kinematics to date, spanning more than 49 institutions and multiple robotic platforms including the CMR Versius, Intuitive Surgical's da Vinci, da Vinci Research Kit (dVRK), Rob Surgical BiTrack, Virtual Incision's MIRA, Moon Surgical Maestro, and a variety of custom systems, spanning surgical manipulation, robotic ultrasound, and endoscopy procedures. We demonstrate the research enabled by this dataset through two foundation models. GR00T-H is the first open foundation vision-language-action model for medical robotics, which is the only evaluated model to achieve full end-to-end task completion on a structured suturing benchmark (25% of trials vs. 0% for all others) and achieves 64% average success across a 29-step ex vivo suturing sequence. We also train Cosmos-H-Surgical-Simulator, the first action-conditioned world model to enable multi-embodiment surgical simulation from a single checkpoint, spanning nine robotic platforms and supporting in silico policy evaluation and synthetic data generation for the medical domain. These results suggest that open, large-scale medical robot data collection can serve as critical infrastructure for the research community, enabling advances in robot learning, world modeling, and beyond.
IMPASTO: Integrating Model-Based Planning with Learned Dynamics Models for Robotic Oil Painting Reproduction
Mar 31, 2026Robotic reproduction of oil paintings using soft brushes and pigments requires force-sensitive control of deformable tools, prediction of brushstroke effects, and multi-step stroke planning, often without human step-by-step demonstrations or faithful simulators. Given only a sequence of target oil painting images, can a robot infer and execute the stroke trajectories, forces, and colors needed to reproduce it? We present IMPASTO, a robotic oil-painting system that integrates learned pixel dynamics models with model-based planning. The dynamics models predict canvas updates from image observations and parameterized stroke actions; a receding-horizon model predictive control optimizer then plans trajectories and forces, while a force-sensitive controller executes strokes on a 7-DoF robot arm. IMPASTO integrates low-level force control, learned dynamics models, and high-level closed-loop planning, learns solely from robot self-play, and approximates human artists' single-stroke datasets and multi-stroke artworks, outperforming baselines in reproduction accuracy. Project website: https://impasto-robopainting.github.io/
CaP-X: A Framework for Benchmarking and Improving Coding Agents for Robot Manipulation
Mar 23, 2026"Code-as-Policy" considers how executable code can complement data-intensive Vision-Language-Action (VLA) methods, yet their effectiveness as autonomous controllers for embodied manipulation remains underexplored. We present CaP-X, an open-access framework for systematically studying Code-as-Policy agents in robot manipulation. At its core is CaP-Gym, an interactive environment in which agents control robots by synthesizing and executing programs that compose perception and control primitives. Building on this foundation, CaP-Bench evaluates frontier language and vision-language models across varying levels of abstraction, interaction, and perceptual grounding. Across 12 models, CaP-Bench reveals a consistent trend: performance improves with human-crafted abstractions but degrades as these priors are removed, exposing a dependence on designer scaffolding. At the same time, we observe that this gap can be mitigated through scaling agentic test-time computation--through multi-turn interaction, structured execution feedback, visual differencing, automatic skill synthesis, and ensembled reasoning--substantially improves robustness even when agents operate over low-level primitives. These findings allow us to derive CaP-Agent0, a training-free framework that recovers human-level reliability on several manipulation tasks in simulation and on real embodiments. We further introduce CaP-RL, showing reinforcement learning with verifiable rewards improves success rates and transfers from sim2real with minimal gap. Together, CaP-X provides a principled, open-access platform for advancing embodied coding agents.
ManipulationNet: An Infrastructure for Benchmarking Real-World Robot Manipulation with Physical Skill Challenges and Embodied Multimodal Reasoning
Mar 04, 2026Dexterous manipulation enables robots to purposefully alter the physical world, transforming them from passive observers into active agents in unstructured environments. This capability is the cornerstone of physical artificial intelligence. Despite decades of advances in hardware, perception, control, and learning, progress toward general manipulation systems remains fragmented due to the absence of widely adopted standard benchmarks. The central challenge lies in reconciling the variability of the real world with the reproducibility and authenticity required for rigorous scientific evaluation. To address this, we introduce ManipulationNet, a global infrastructure that hosts real-world benchmark tasks for robotic manipulation. ManipulationNet delivers reproducible task setups through standardized hardware kits, and enables distributed performance evaluation via a unified software client that delivers real-time task instructions and collects benchmarking results. As a persistent and scalable infrastructure, ManipulationNet organizes benchmark tasks into two complementary tracks: 1) the Physical Skills Track, which evaluates low-level physical interaction skills, and 2) the Embodied Reasoning Track, which tests high-level reasoning and multimodal grounding abilities. This design fosters the systematic growth of an interconnected network of real-world abilities and skills, paving the path toward general robotic manipulation. By enabling comparable manipulation research in the real world at scale, this infrastructure establishes a sustainable foundation for measuring long-term scientific progress and identifying capabilities ready for real-world deployment.
VisGym: Diverse, Customizable, Scalable Environments for Multimodal Agents
Jan 23, 2026Modern Vision-Language Models (VLMs) remain poorly characterized in multi-step visual interactions, particularly in how they integrate perception, memory, and action over long horizons. We introduce VisGym, a gymnasium of 17 environments for evaluating and training VLMs. The suite spans symbolic puzzles, real-image understanding, navigation, and manipulation, and provides flexible controls over difficulty, input representation, planning horizon, and feedback. We also provide multi-step solvers that generate structured demonstrations, enabling supervised finetuning. Our evaluations show that all frontier models struggle in interactive settings, achieving low success rates in both the easy (46.6%) and hard (26.0%) configurations. Our experiments reveal notable limitations: models struggle to effectively leverage long context, performing worse with an unbounded history than with truncated windows. Furthermore, we find that several text-based symbolic tasks become substantially harder once rendered visually. However, explicit goal observations, textual feedback, and exploratory demonstrations in partially observable or unknown-dynamics settings for supervised finetuning yield consistent gains, highlighting concrete failure modes and pathways for improving multi-step visual decision-making. Code, data, and models can be found at: https://visgym.github.io/.
OXE-AugE: A Large-Scale Robot Augmentation of OXE for Scaling Cross-Embodiment Policy Learning
Dec 15, 2025

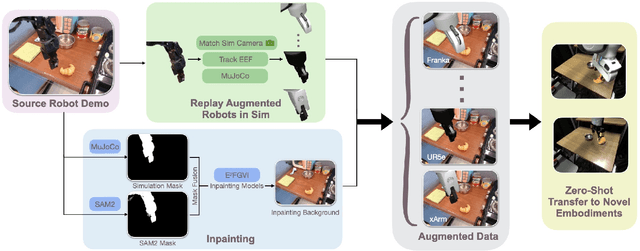
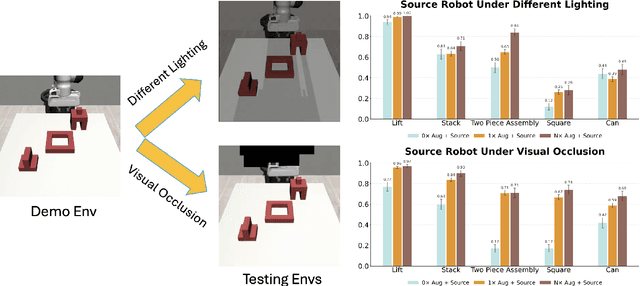
Large and diverse datasets are needed for training generalist robot policies that have potential to control a variety of robot embodiments -- robot arm and gripper combinations -- across diverse tasks and environments. As re-collecting demonstrations and retraining for each new hardware platform are prohibitively costly, we show that existing robot data can be augmented for transfer and generalization. The Open X-Embodiment (OXE) dataset, which aggregates demonstrations from over 60 robot datasets, has been widely used as the foundation for training generalist policies. However, it is highly imbalanced: the top four robot types account for over 85\% of its real data, which risks overfitting to robot-scene combinations. We present AugE-Toolkit, a scalable robot augmentation pipeline, and OXE-AugE, a high-quality open-source dataset that augments OXE with 9 different robot embodiments. OXE-AugE provides over 4.4 million trajectories, more than triple the size of the original OXE. We conduct a systematic study of how scaling robot augmentation impacts cross-embodiment learning. Results suggest that augmenting datasets with diverse arms and grippers improves policy performance not only on the augmented robots, but also on unseen robots and even the original robots under distribution shifts. In physical experiments, we demonstrate that state-of-the-art generalist policies such as OpenVLA and $π_0$ benefit from fine-tuning on OXE-AugE, improving success rates by 24-45% on previously unseen robot-gripper combinations across four real-world manipulation tasks. Project website: https://OXE-AugE.github.io/.
LAVQA: A Latency-Aware Visual Question Answering Framework for Shared Autonomy in Self-Driving Vehicles
Nov 14, 2025When uncertainty is high, self-driving vehicles may halt for safety and benefit from the access to remote human operators who can provide high-level guidance. This paradigm, known as {shared autonomy}, enables autonomous vehicle and remote human operators to jointly formulate appropriate responses. To address critical decision timing with variable latency due to wireless network delays and human response time, we present LAVQA, a latency-aware shared autonomy framework that integrates Visual Question Answering (VQA) and spatiotemporal risk visualization. LAVQA augments visual queries with Latency-Induced COllision Map (LICOM), a dynamically evolving map that represents both temporal latency and spatial uncertainty. It enables remote operator to observe as the vehicle safety regions vary over time in the presence of dynamic obstacles and delayed responses. Closed-loop simulations in CARLA, the de-facto standard for autonomous vehicle simulator, suggest that that LAVQA can reduce collision rates by over 8x compared to latency-agnostic baselines.
STITCH 2.0: Extending Augmented Suturing with EKF Needle Estimation and Thread Management
Oct 29, 2025Surgical suturing is a high-precision task that impacts patient healing and scarring. Suturing skill varies widely between surgeons, highlighting the need for robot assistance. Previous robot suturing works, such as STITCH 1.0 [1], struggle to fully close wounds due to inaccurate needle tracking and poor thread management. To address these challenges, we present STITCH 2.0, an elevated augmented dexterity pipeline with seven improvements including: improved EKF needle pose estimation, new thread untangling methods, and an automated 3D suture alignment algorithm. Experimental results over 15 trials find that STITCH 2.0 on average achieves 74.4% wound closure with 4.87 sutures per trial, representing 66% more sutures in 38% less time compared to the previous baseline. When two human interventions are allowed, STITCH 2.0 averages six sutures with 100% wound closure rate. Project website: https://stitch-2.github.io/
Omni-Scan: Creating Visually-Accurate Digital Twin Object Models Using a Bimanual Robot with Handover and Gaussian Splat Merging
Aug 01, 20253D Gaussian Splats (3DGSs) are 3D object models derived from multi-view images. Such "digital twins" are useful for simulations, virtual reality, marketing, robot policy fine-tuning, and part inspection. 3D object scanning usually requires multi-camera arrays, precise laser scanners, or robot wrist-mounted cameras, which have restricted workspaces. We propose Omni-Scan, a pipeline for producing high-quality 3D Gaussian Splat models using a bi-manual robot that grasps an object with one gripper and rotates the object with respect to a stationary camera. The object is then re-grasped by a second gripper to expose surfaces that were occluded by the first gripper. We present the Omni-Scan robot pipeline using DepthAny-thing, Segment Anything, as well as RAFT optical flow models to identify and isolate objects held by a robot gripper while removing the gripper and the background. We then modify the 3DGS training pipeline to support concatenated datasets with gripper occlusion, producing an omni-directional (360 degree view) model of the object. We apply Omni-Scan to part defect inspection, finding that it can identify visual or geometric defects in 12 different industrial and household objects with an average accuracy of 83%. Interactive videos of Omni-Scan 3DGS models can be found at https://berkeleyautomation.github.io/omni-scan/
Eye, Robot: Learning to Look to Act with a BC-RL Perception-Action Loop
Jun 12, 2025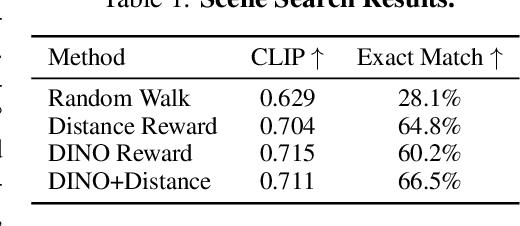
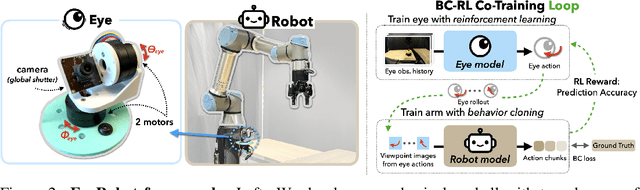


Humans do not passively observe the visual world -- we actively look in order to act. Motivated by this principle, we introduce EyeRobot, a robotic system with gaze behavior that emerges from the need to complete real-world tasks. We develop a mechanical eyeball that can freely rotate to observe its surroundings and train a gaze policy to control it using reinforcement learning. We accomplish this by first collecting teleoperated demonstrations paired with a 360 camera. This data is imported into a simulation environment that supports rendering arbitrary eyeball viewpoints, allowing episode rollouts of eye gaze on top of robot demonstrations. We then introduce a BC-RL loop to train the hand and eye jointly: the hand (BC) agent is trained from rendered eye observations, and the eye (RL) agent is rewarded when the hand produces correct action predictions. In this way, hand-eye coordination emerges as the eye looks towards regions which allow the hand to complete the task. EyeRobot implements a foveal-inspired policy architecture allowing high resolution with a small compute budget, which we find also leads to the emergence of more stable fixation as well as improved ability to track objects and ignore distractors. We evaluate EyeRobot on five panoramic workspace manipulation tasks requiring manipulation in an arc surrounding the robot arm. Our experiments suggest EyeRobot exhibits hand-eye coordination behaviors which effectively facilitate manipulation over large workspaces with a single camera. See project site for videos: https://www.eyerobot.net/