 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCaP-X: A Framework for Benchmarking and Improving Coding Agents for Robot Manipulation
Mar 23, 2026"Code-as-Policy" considers how executable code can complement data-intensive Vision-Language-Action (VLA) methods, yet their effectiveness as autonomous controllers for embodied manipulation remains underexplored. We present CaP-X, an open-access framework for systematically studying Code-as-Policy agents in robot manipulation. At its core is CaP-Gym, an interactive environment in which agents control robots by synthesizing and executing programs that compose perception and control primitives. Building on this foundation, CaP-Bench evaluates frontier language and vision-language models across varying levels of abstraction, interaction, and perceptual grounding. Across 12 models, CaP-Bench reveals a consistent trend: performance improves with human-crafted abstractions but degrades as these priors are removed, exposing a dependence on designer scaffolding. At the same time, we observe that this gap can be mitigated through scaling agentic test-time computation--through multi-turn interaction, structured execution feedback, visual differencing, automatic skill synthesis, and ensembled reasoning--substantially improves robustness even when agents operate over low-level primitives. These findings allow us to derive CaP-Agent0, a training-free framework that recovers human-level reliability on several manipulation tasks in simulation and on real embodiments. We further introduce CaP-RL, showing reinforcement learning with verifiable rewards improves success rates and transfers from sim2real with minimal gap. Together, CaP-X provides a principled, open-access platform for advancing embodied coding agents.
Real2Render2Real: Scaling Robot Data Without Dynamics Simulation or Robot Hardware
May 14, 2025
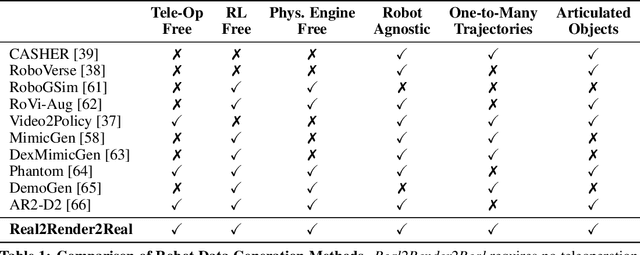
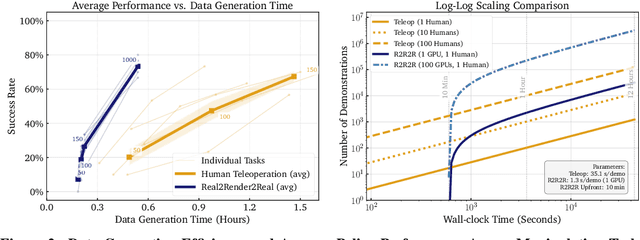
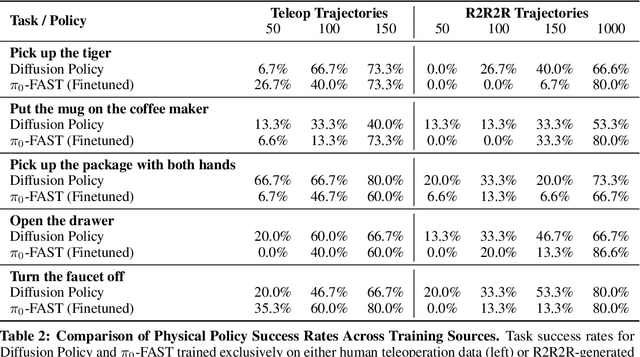
Scaling robot learning requires vast and diverse datasets. Yet the prevailing data collection paradigm-human teleoperation-remains costly and constrained by manual effort and physical robot access. We introduce Real2Render2Real (R2R2R), a novel approach for generating robot training data without relying on object dynamics simulation or teleoperation of robot hardware. The input is a smartphone-captured scan of one or more objects and a single video of a human demonstration. R2R2R renders thousands of high visual fidelity robot-agnostic demonstrations by reconstructing detailed 3D object geometry and appearance, and tracking 6-DoF object motion. R2R2R uses 3D Gaussian Splatting (3DGS) to enable flexible asset generation and trajectory synthesis for both rigid and articulated objects, converting these representations to meshes to maintain compatibility with scalable rendering engines like IsaacLab but with collision modeling off. Robot demonstration data generated by R2R2R integrates directly with models that operate on robot proprioceptive states and image observations, such as vision-language-action models (VLA) and imitation learning policies. Physical experiments suggest that models trained on R2R2R data from a single human demonstration can match the performance of models trained on 150 human teleoperation demonstrations. Project page: https://real2render2real.com
Persistent Object Gaussian Splat (POGS) for Tracking Human and Robot Manipulation of Irregularly Shaped Objects
Mar 07, 2025
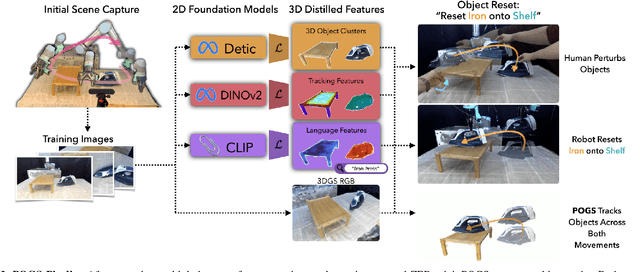


Tracking and manipulating irregularly-shaped, previously unseen objects in dynamic environments is important for robotic applications in manufacturing, assembly, and logistics. Recently introduced Gaussian Splats efficiently model object geometry, but lack persistent state estimation for task-oriented manipulation. We present Persistent Object Gaussian Splat (POGS), a system that embeds semantics, self-supervised visual features, and object grouping features into a compact representation that can be continuously updated to estimate the pose of scanned objects. POGS updates object states without requiring expensive rescanning or prior CAD models of objects. After an initial multi-view scene capture and training phase, POGS uses a single stereo camera to integrate depth estimates along with self-supervised vision encoder features for object pose estimation. POGS supports grasping, reorientation, and natural language-driven manipulation by refining object pose estimates, facilitating sequential object reset operations with human-induced object perturbations and tool servoing, where robots recover tool pose despite tool perturbations of up to 30{\deg}. POGS achieves up to 12 consecutive successful object resets and recovers from 80% of in-grasp tool perturbations.
Language-Embedded Gaussian Splats (LEGS): Incrementally Building Room-Scale Representations with a Mobile Robot
Sep 26, 2024
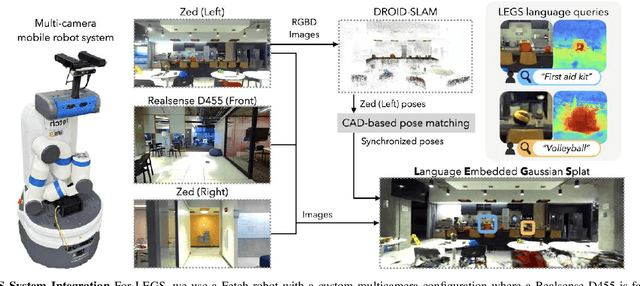


Building semantic 3D maps is valuable for searching for objects of interest in offices, warehouses, stores, and homes. We present a mapping system that incrementally builds a Language-Embedded Gaussian Splat (LEGS): a detailed 3D scene representation that encodes both appearance and semantics in a unified representation. LEGS is trained online as a robot traverses its environment to enable localization of open-vocabulary object queries. We evaluate LEGS on 4 room-scale scenes where we query for objects in the scene to assess how LEGS can capture semantic meaning. We compare LEGS to LERF and find that while both systems have comparable object query success rates, LEGS trains over 3.5x faster than LERF. Results suggest that a multi-camera setup and incremental bundle adjustment can boost visual reconstruction quality in constrained robot trajectories, and suggest LEGS can localize open-vocabulary and long-tail object queries with up to 66% accuracy.
Mitigating Outlier Activations in Low-Precision Fine-Tuning of Language Models
Dec 15, 2023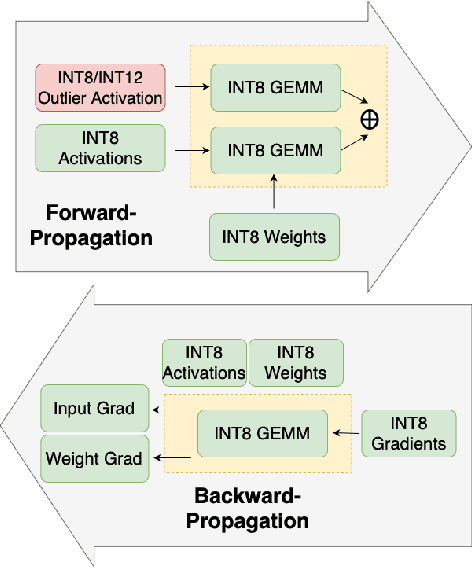

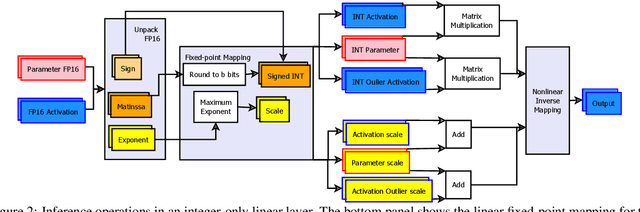
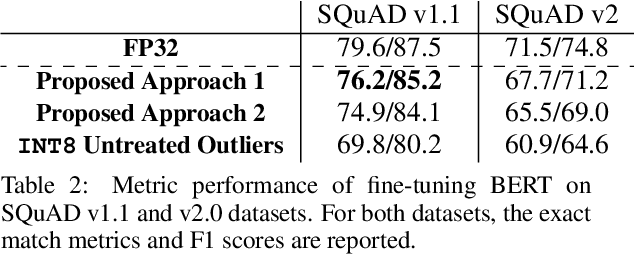
Low-precision fine-tuning of language models has gained prominence as a cost-effective and energy-efficient approach to deploying large-scale models in various applications. However, this approach is susceptible to the existence of outlier values in activation. The outlier values in the activation can negatively affect the performance of fine-tuning language models in the low-precision regime since they affect the scaling factor and thus make representing smaller values harder. This paper investigates techniques for mitigating outlier activation in low-precision integer fine-tuning of the language models. Our proposed novel approach enables us to represent the outlier activation values in 8-bit integers instead of floating-point (FP16) values. The benefit of using integers for outlier values is that it enables us to use operator tiling to avoid performing 16-bit integer matrix multiplication to address this problem effectively. We provide theoretical analysis and supporting experiments to demonstrate the effectiveness of our approach in improving the robustness and performance of low-precision fine-tuned language models.
Effectively Rearranging Heterogeneous Objects on Cluttered Tabletops
Jun 30, 2023



Effectively rearranging heterogeneous objects constitutes a high-utility skill that an intelligent robot should master. Whereas significant work has been devoted to the grasp synthesis of heterogeneous objects, little attention has been given to the planning for sequentially manipulating such objects. In this work, we examine the long-horizon sequential rearrangement of heterogeneous objects in a tabletop setting, addressing not just generating feasible plans but near-optimal ones. Toward that end, and building on previous methods, including combinatorial algorithms and Monte Carlo tree search-based solutions, we develop state-of-the-art solvers for optimizing two practical objective functions considering key object properties such as size and weight. Thorough simulation studies show that our methods provide significant advantages in handling challenging heterogeneous object rearrangement problems, especially in cluttered settings. Real robot experiments further demonstrate and confirm these advantages. Source code and evaluation data associated with this research will be available at https://github.com/arc-l/TRLB upon the publication of this manuscript.
MURAL: Meta-Learning Uncertainty-Aware Rewards for Outcome-Driven Reinforcement Learning
Jul 18, 2021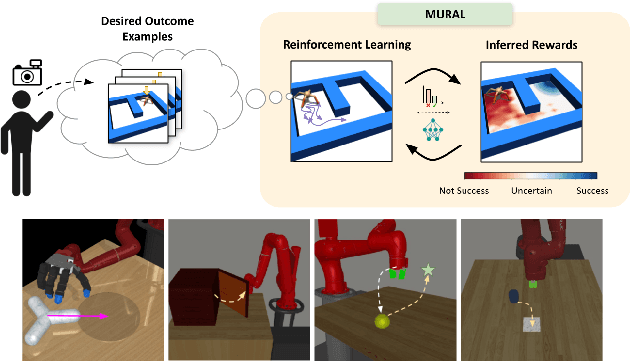
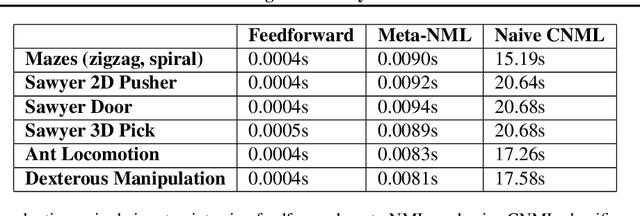

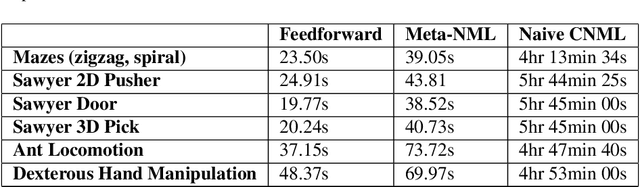
Exploration in reinforcement learning is a challenging problem: in the worst case, the agent must search for high-reward states that could be hidden anywhere in the state space. Can we define a more tractable class of RL problems, where the agent is provided with examples of successful outcomes? In this problem setting, the reward function can be obtained automatically by training a classifier to categorize states as successful or not. If trained properly, such a classifier can provide a well-shaped objective landscape that both promotes progress toward good states and provides a calibrated exploration bonus. In this work, we show that an uncertainty aware classifier can solve challenging reinforcement learning problems by both encouraging exploration and provided directed guidance towards positive outcomes. We propose a novel mechanism for obtaining these calibrated, uncertainty-aware classifiers based on an amortized technique for computing the normalized maximum likelihood (NML) distribution. To make this tractable, we propose a novel method for computing the NML distribution by using meta-learning. We show that the resulting algorithm has a number of intriguing connections to both count-based exploration methods and prior algorithms for learning reward functions, while also providing more effective guidance towards the goal. We demonstrate that our algorithm solves a number of challenging navigation and robotic manipulation tasks which prove difficult or impossible for prior methods.
Deep Multi-Modal Contact Estimation for Invariant Observer Design on Quadruped Robots
Jul 07, 2021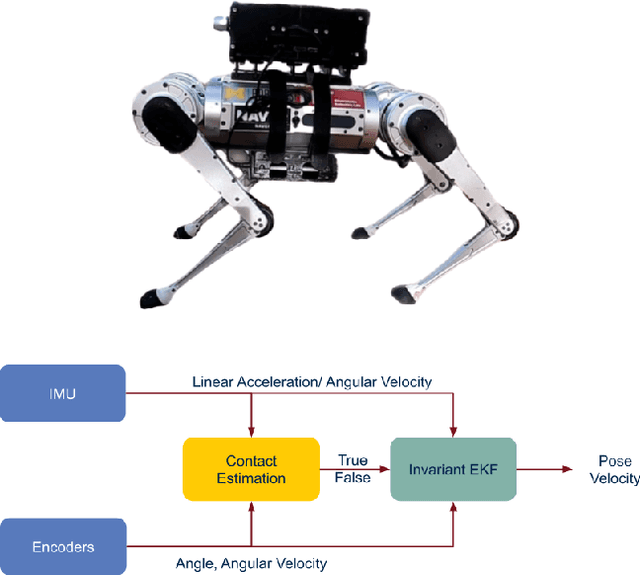
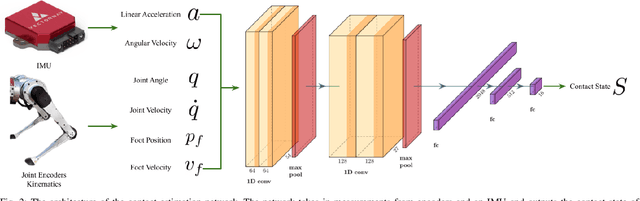
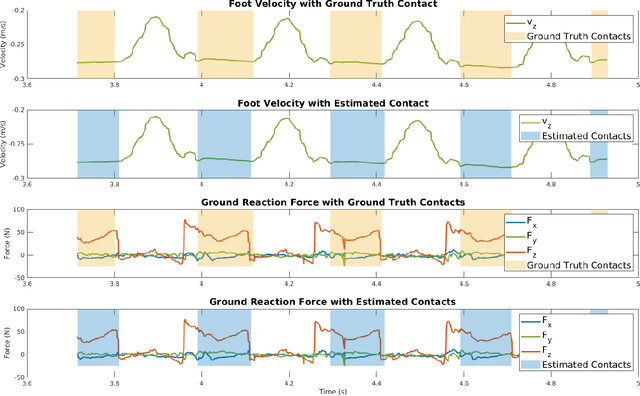
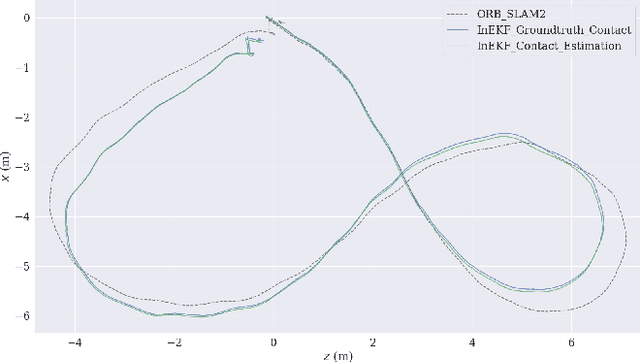
This work reports on developing a deep learning-based contact estimator for legged robots that bypasses the need for physical contact sensors and takes multi-modal proprioceptive sensory data from joint encoders, kinematics, and an inertial measurement unit as input. Unlike vision-based state estimators, proprioceptive state estimators are agnostic to perceptually degraded situations such as dark or foggy scenes. For legged robots, reliable kinematics and contact data are necessary to develop a proprioceptive state estimator. While some robots are equipped with dedicated contact sensors or springs to detect contact, some robots do not have dedicated contact sensors, and the addition of such sensors is non-trivial without redesigning the hardware. The trained deep network can accurately estimate contacts on different terrains and robot gaits and is deployed along a contact-aided invariant extended Kalman filter to generate odometry trajectories. The filter performs comparably to a state-of-the-art visual SLAM system.
Reset-Free Reinforcement Learning via Multi-Task Learning: Learning Dexterous Manipulation Behaviors without Human Intervention
Apr 22, 2021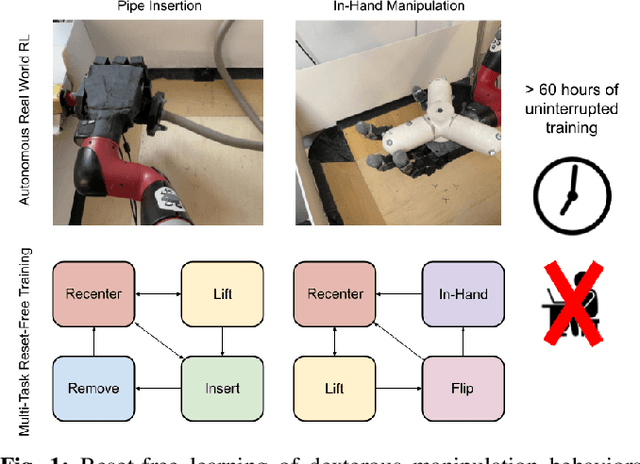


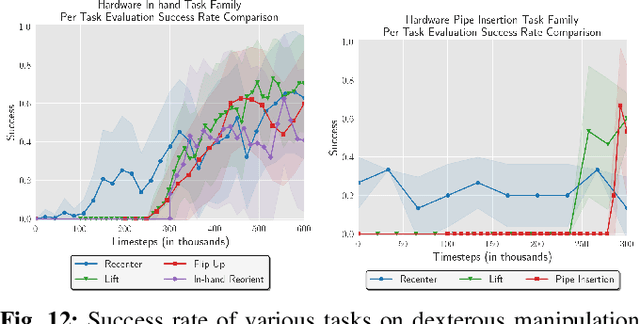
Reinforcement Learning (RL) algorithms can in principle acquire complex robotic skills by learning from large amounts of data in the real world, collected via trial and error. However, most RL algorithms use a carefully engineered setup in order to collect data, requiring human supervision and intervention to provide episodic resets. This is particularly evident in challenging robotics problems, such as dexterous manipulation. To make data collection scalable, such applications require reset-free algorithms that are able to learn autonomously, without explicit instrumentation or human intervention. Most prior work in this area handles single-task learning. However, we might also want robots that can perform large repertoires of skills. At first, this would appear to only make the problem harder. However, the key observation we make in this work is that an appropriately chosen multi-task RL setting actually alleviates the reset-free learning challenge, with minimal additional machinery required. In effect, solving a multi-task problem can directly solve the reset-free problem since different combinations of tasks can serve to perform resets for other tasks. By learning multiple tasks together and appropriately sequencing them, we can effectively learn all of the tasks together reset-free. This type of multi-task learning can effectively scale reset-free learning schemes to much more complex problems, as we demonstrate in our experiments. We propose a simple scheme for multi-task learning that tackles the reset-free learning problem, and show its effectiveness at learning to solve complex dexterous manipulation tasks in both hardware and simulation without any explicit resets. This work shows the ability to learn dexterous manipulation behaviors in the real world with RL without any human intervention.
The Ingredients of Real-World Robotic Reinforcement Learning
Apr 27, 2020
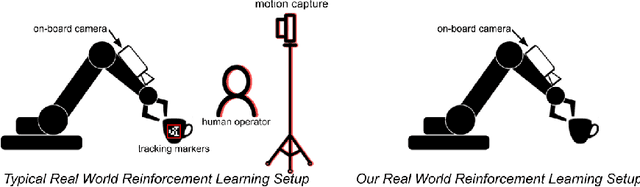
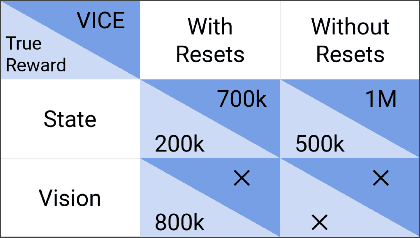
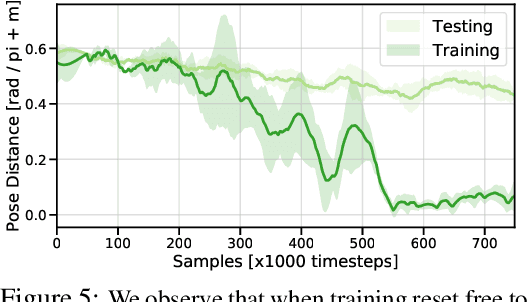
The success of reinforcement learning for real world robotics has been, in many cases limited to instrumented laboratory scenarios, often requiring arduous human effort and oversight to enable continuous learning. In this work, we discuss the elements that are needed for a robotic learning system that can continually and autonomously improve with data collected in the real world. We propose a particular instantiation of such a system, using dexterous manipulation as our case study. Subsequently, we investigate a number of challenges that come up when learning without instrumentation. In such settings, learning must be feasible without manually designed resets, using only on-board perception, and without hand-engineered reward functions. We propose simple and scalable solutions to these challenges, and then demonstrate the efficacy of our proposed system on a set of dexterous robotic manipulation tasks, providing an in-depth analysis of the challenges associated with this learning paradigm. We demonstrate that our complete system can learn without any human intervention, acquiring a variety of vision-based skills with a real-world three-fingered hand. Results and videos can be found at https://sites.google.com/view/realworld-rl/