 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLanguage-Embedded Gaussian Splats (LEGS): Incrementally Building Room-Scale Representations with a Mobile Robot
Sep 26, 2024
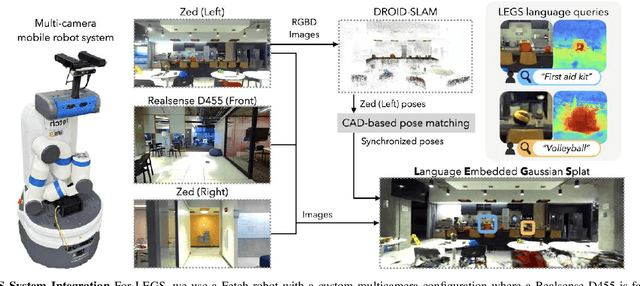


Building semantic 3D maps is valuable for searching for objects of interest in offices, warehouses, stores, and homes. We present a mapping system that incrementally builds a Language-Embedded Gaussian Splat (LEGS): a detailed 3D scene representation that encodes both appearance and semantics in a unified representation. LEGS is trained online as a robot traverses its environment to enable localization of open-vocabulary object queries. We evaluate LEGS on 4 room-scale scenes where we query for objects in the scene to assess how LEGS can capture semantic meaning. We compare LEGS to LERF and find that while both systems have comparable object query success rates, LEGS trains over 3.5x faster than LERF. Results suggest that a multi-camera setup and incremental bundle adjustment can boost visual reconstruction quality in constrained robot trajectories, and suggest LEGS can localize open-vocabulary and long-tail object queries with up to 66% accuracy.
Lifelong LERF: Local 3D Semantic Inventory Monitoring Using FogROS2
Mar 15, 2024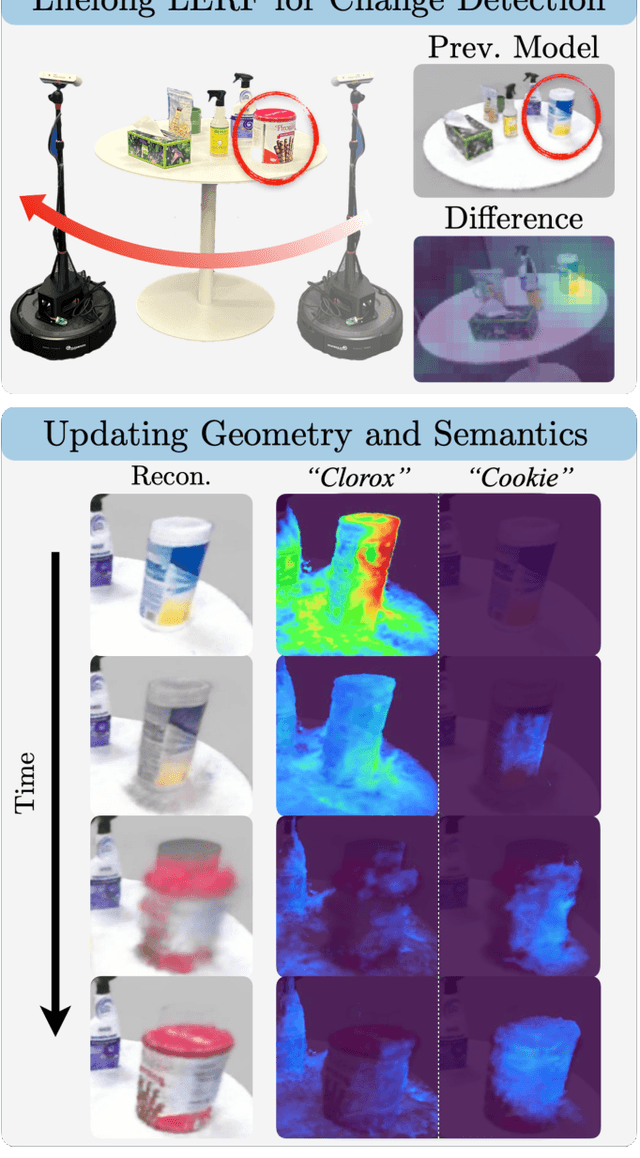
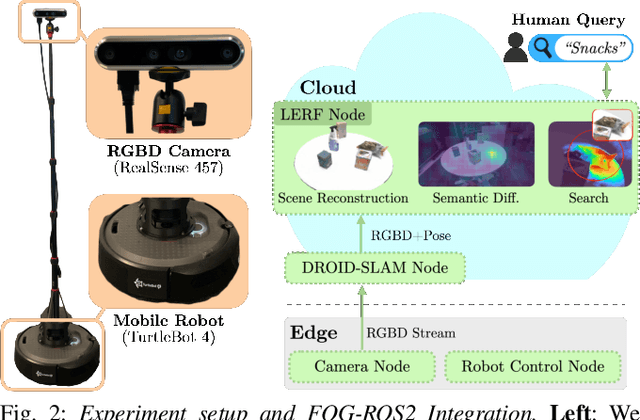
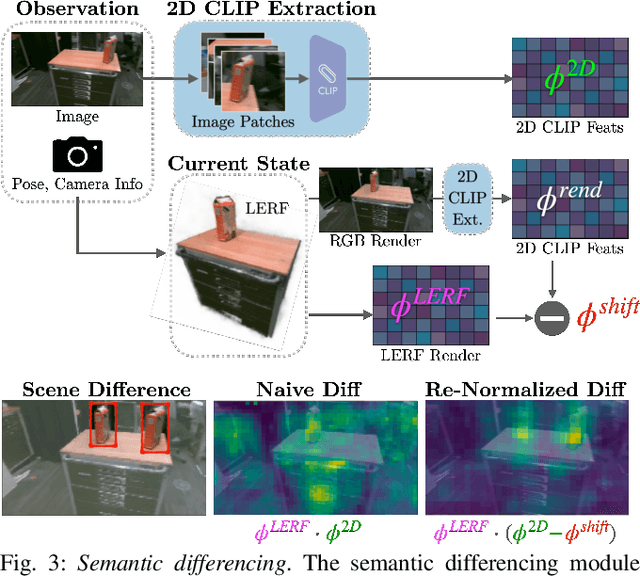

Inventory monitoring in homes, factories, and retail stores relies on maintaining data despite objects being swapped, added, removed, or moved. We introduce Lifelong LERF, a method that allows a mobile robot with minimal compute to jointly optimize a dense language and geometric representation of its surroundings. Lifelong LERF maintains this representation over time by detecting semantic changes and selectively updating these regions of the environment, avoiding the need to exhaustively remap. Human users can query inventory by providing natural language queries and receiving a 3D heatmap of potential object locations. To manage the computational load, we use Fog-ROS2, a cloud robotics platform, to offload resource-intensive tasks. Lifelong LERF obtains poses from a monocular RGBD SLAM backend, and uses these poses to progressively optimize a Language Embedded Radiance Field (LERF) for semantic monitoring. Experiments with 3-5 objects arranged on a tabletop and a Turtlebot with a RealSense camera suggest that Lifelong LERF can persistently adapt to changes in objects with up to 91% accuracy.
Language Embedded Radiance Fields for Zero-Shot Task-Oriented Grasping
Sep 18, 2023



Grasping objects by a specific part is often crucial for safety and for executing downstream tasks. Yet, learning-based grasp planners lack this behavior unless they are trained on specific object part data, making it a significant challenge to scale object diversity. Instead, we propose LERF-TOGO, Language Embedded Radiance Fields for Task-Oriented Grasping of Objects, which uses vision-language models zero-shot to output a grasp distribution over an object given a natural language query. To accomplish this, we first reconstruct a LERF of the scene, which distills CLIP embeddings into a multi-scale 3D language field queryable with text. However, LERF has no sense of objectness, meaning its relevancy outputs often return incomplete activations over an object which are insufficient for subsequent part queries. LERF-TOGO mitigates this lack of spatial grouping by extracting a 3D object mask via DINO features and then conditionally querying LERF on this mask to obtain a semantic distribution over the object with which to rank grasps from an off-the-shelf grasp planner. We evaluate LERF-TOGO's ability to grasp task-oriented object parts on 31 different physical objects, and find it selects grasps on the correct part in 81% of all trials and grasps successfully in 69%. See the project website at: lerftogo.github.io