 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDual-Arm Whole-Body Motion Planning: Leveraging Overlapping Kinematic Chains
Nov 11, 2025High degree-of-freedom dual-arm robots are becoming increasingly common due to their morphology enabling them to operate effectively in human environments. However, motion planning in real-time within unknown, changing environments remains a challenge for such robots due to the high dimensionality of the configuration space and the complex collision-avoidance constraints that must be obeyed. In this work, we propose a novel way to alleviate the curse of dimensionality by leveraging the structure imposed by shared joints (e.g. torso joints) in a dual-arm robot. First, we build two dynamic roadmaps (DRM) for each kinematic chain (i.e. left arm + torso, right arm + torso) with specific structure induced by the shared joints. Then, we show that we can leverage this structure to efficiently search through the composition of the two roadmaps and largely sidestep the curse of dimensionality. Finally, we run several experiments in a real-world grocery store with this motion planner on a 19 DoF mobile manipulation robot executing a grocery fulfillment task, achieving 0.4s average planning times with 99.9% success rate across more than 2000 motion plans.
Real2Render2Real: Scaling Robot Data Without Dynamics Simulation or Robot Hardware
May 14, 2025
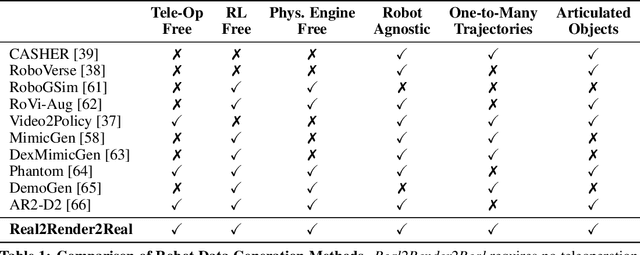
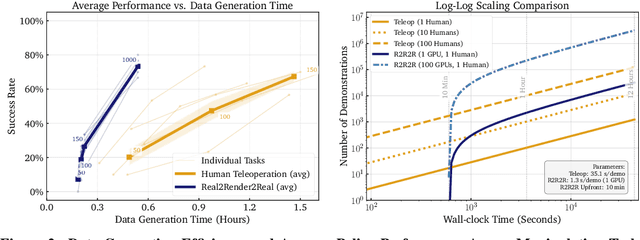
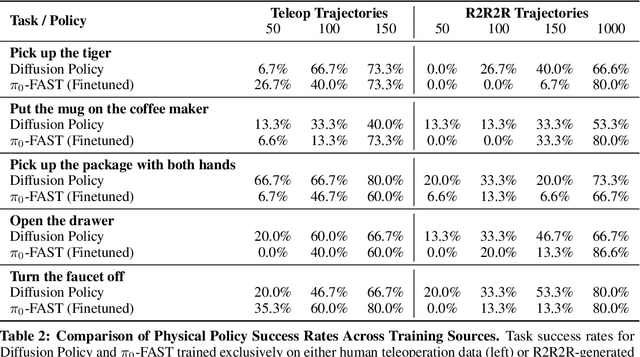
Scaling robot learning requires vast and diverse datasets. Yet the prevailing data collection paradigm-human teleoperation-remains costly and constrained by manual effort and physical robot access. We introduce Real2Render2Real (R2R2R), a novel approach for generating robot training data without relying on object dynamics simulation or teleoperation of robot hardware. The input is a smartphone-captured scan of one or more objects and a single video of a human demonstration. R2R2R renders thousands of high visual fidelity robot-agnostic demonstrations by reconstructing detailed 3D object geometry and appearance, and tracking 6-DoF object motion. R2R2R uses 3D Gaussian Splatting (3DGS) to enable flexible asset generation and trajectory synthesis for both rigid and articulated objects, converting these representations to meshes to maintain compatibility with scalable rendering engines like IsaacLab but with collision modeling off. Robot demonstration data generated by R2R2R integrates directly with models that operate on robot proprioceptive states and image observations, such as vision-language-action models (VLA) and imitation learning policies. Physical experiments suggest that models trained on R2R2R data from a single human demonstration can match the performance of models trained on 150 human teleoperation demonstrations. Project page: https://real2render2real.com
Practical Insights on Grasp Strategies for Mobile Manipulation in the Wild
Apr 16, 2025Mobile manipulation robots are continuously advancing, with their grasping capabilities rapidly progressing. However, there are still significant gaps preventing state-of-the-art mobile manipulators from widespread real-world deployments, including their ability to reliably grasp items in unstructured environments. To help bridge this gap, we developed SHOPPER, a mobile manipulation robot platform designed to push the boundaries of reliable and generalizable grasp strategies. We develop these grasp strategies and deploy them in a real-world grocery store -- an exceptionally challenging setting chosen for its vast diversity of manipulable items, fixtures, and layouts. In this work, we present our detailed approach to designing general grasp strategies towards picking any item in a real grocery store. Additionally, we provide an in-depth analysis of our latest real-world field test, discussing key findings related to fundamental failure modes over hundreds of distinct pick attempts. Through our detailed analysis, we aim to offer valuable practical insights and identify key grasping challenges, which can guide the robotics community towards pressing open problems in the field.
Superfast Configuration-Space Convex Set Computation on GPUs for Online Motion Planning
Apr 15, 2025In this work, we leverage GPUs to construct probabilistically collision-free convex sets in robot configuration space on the fly. This extends the use of modern motion planning algorithms that leverage such representations to changing environments. These planners rapidly and reliably optimize high-quality trajectories, without the burden of challenging nonconvex collision-avoidance constraints. We present an algorithm that inflates collision-free piecewise linear paths into sequences of convex sets (SCS) that are probabilistically collision-free using massive parallelism. We then integrate this algorithm into a motion planning pipeline, which leverages dynamic roadmaps to rapidly find one or multiple collision-free paths, and inflates them. We then optimize the trajectory through the probabilistically collision-free sets, simultaneously using the candidate trajectory to detect and remove collisions from the sets. We demonstrate the efficacy of our approach on a simulation benchmark and a KUKA iiwa 7 robot manipulator with perception in the loop. On our benchmark, our approach runs 17.1 times faster and yields a 27.9% increase in reliability over the nonlinear trajectory optimization baseline, while still producing high-quality motion plans.
Persistent Object Gaussian Splat (POGS) for Tracking Human and Robot Manipulation of Irregularly Shaped Objects
Mar 07, 2025
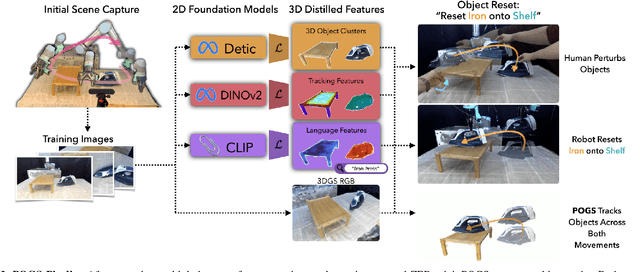


Tracking and manipulating irregularly-shaped, previously unseen objects in dynamic environments is important for robotic applications in manufacturing, assembly, and logistics. Recently introduced Gaussian Splats efficiently model object geometry, but lack persistent state estimation for task-oriented manipulation. We present Persistent Object Gaussian Splat (POGS), a system that embeds semantics, self-supervised visual features, and object grouping features into a compact representation that can be continuously updated to estimate the pose of scanned objects. POGS updates object states without requiring expensive rescanning or prior CAD models of objects. After an initial multi-view scene capture and training phase, POGS uses a single stereo camera to integrate depth estimates along with self-supervised vision encoder features for object pose estimation. POGS supports grasping, reorientation, and natural language-driven manipulation by refining object pose estimates, facilitating sequential object reset operations with human-induced object perturbations and tool servoing, where robots recover tool pose despite tool perturbations of up to 30{\deg}. POGS achieves up to 12 consecutive successful object resets and recovers from 80% of in-grasp tool perturbations.
Language-Embedded Gaussian Splats (LEGS): Incrementally Building Room-Scale Representations with a Mobile Robot
Sep 26, 2024
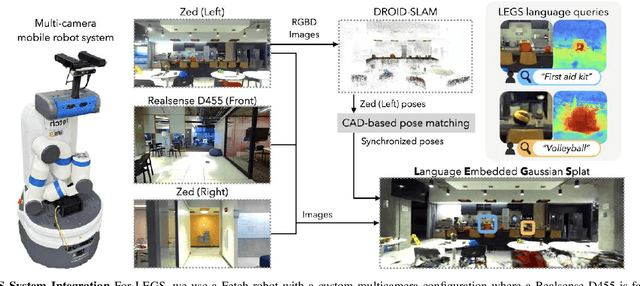


Building semantic 3D maps is valuable for searching for objects of interest in offices, warehouses, stores, and homes. We present a mapping system that incrementally builds a Language-Embedded Gaussian Splat (LEGS): a detailed 3D scene representation that encodes both appearance and semantics in a unified representation. LEGS is trained online as a robot traverses its environment to enable localization of open-vocabulary object queries. We evaluate LEGS on 4 room-scale scenes where we query for objects in the scene to assess how LEGS can capture semantic meaning. We compare LEGS to LERF and find that while both systems have comparable object query success rates, LEGS trains over 3.5x faster than LERF. Results suggest that a multi-camera setup and incremental bundle adjustment can boost visual reconstruction quality in constrained robot trajectories, and suggest LEGS can localize open-vocabulary and long-tail object queries with up to 66% accuracy.
RoVi-Aug: Robot and Viewpoint Augmentation for Cross-Embodiment Robot Learning
Sep 05, 2024



Scaling up robot learning requires large and diverse datasets, and how to efficiently reuse collected data and transfer policies to new embodiments remains an open question. Emerging research such as the Open-X Embodiment (OXE) project has shown promise in leveraging skills by combining datasets including different robots. However, imbalances in the distribution of robot types and camera angles in many datasets make policies prone to overfit. To mitigate this issue, we propose RoVi-Aug, which leverages state-of-the-art image-to-image generative models to augment robot data by synthesizing demonstrations with different robots and camera views. Through extensive physical experiments, we show that, by training on robot- and viewpoint-augmented data, RoVi-Aug can zero-shot deploy on an unseen robot with significantly different camera angles. Compared to test-time adaptation algorithms such as Mirage, RoVi-Aug requires no extra processing at test time, does not assume known camera angles, and allows policy fine-tuning. Moreover, by co-training on both the original and augmented robot datasets, RoVi-Aug can learn multi-robot and multi-task policies, enabling more efficient transfer between robots and skills and improving success rates by up to 30%.
Demonstrating Mobile Manipulation in the Wild: A Metrics-Driven Approach
Jan 03, 2024



We present our general-purpose mobile manipulation system consisting of a custom robot platform and key algorithms spanning perception and planning. To extensively test the system in the wild and benchmark its performance, we choose a grocery shopping scenario in an actual, unmodified grocery store. We derive key performance metrics from detailed robot log data collected during six week-long field tests, spread across 18 months. These objective metrics, gained from complex yet repeatable tests, drive the direction of our research efforts and let us continuously improve our system's performance. We find that thorough end-to-end system-level testing of a complex mobile manipulation system can serve as a reality-check for state-of-the-art methods in robotics. This effectively grounds robotics research efforts in real world needs and challenges, which we deem highly useful for the advancement of the field. To this end, we share our key insights and takeaways to inspire and accelerate similar system-level research projects.
The Teenager's Problem: Efficient Garment Decluttering With Grasp Optimization
Oct 25, 2023



This paper addresses the ''Teenager's Problem'': efficiently removing scattered garments from a planar surface. As grasping and transporting individual garments is highly inefficient, we propose analytical policies to select grasp locations for multiple garments using an overhead camera. Two classes of methods are considered: depth-based, which use overhead depth data to find efficient grasps, and segment-based, which use segmentation on the RGB overhead image (without requiring any depth data); grasp efficiency is measured by Objects per Transport, which denotes the average number of objects removed per trip to the laundry basket. Experiments suggest that both depth- and segment-based methods easily reduce Objects per Transport (OpT) by $20\%$; furthermore, these approaches complement each other, with combined hybrid methods yielding improvements of $34\%$. Finally, a method employing consolidation (with segmentation) is considered, which manipulates the garments on the work surface to increase OpT; this yields an improvement of $67\%$ over the baseline, though at a cost of additional physical actions.
Bagging by Learning to Singulate Layers Using Interactive Perception
Mar 29, 2023Many fabric handling and 2D deformable material tasks in homes and industry require singulating layers of material such as opening a bag or arranging garments for sewing. In contrast to methods requiring specialized sensing or end effectors, we use only visual observations with ordinary parallel jaw grippers. We propose SLIP: Singulating Layers using Interactive Perception, and apply SLIP to the task of autonomous bagging. We develop SLIP-Bagging, a bagging algorithm that manipulates a plastic or fabric bag from an unstructured state, and uses SLIP to grasp the top layer of the bag to open it for object insertion. In physical experiments, a YuMi robot achieves a success rate of 67% to 81% across bags of a variety of materials, shapes, and sizes, significantly improving in success rate and generality over prior work. Experiments also suggest that SLIP can be applied to tasks such as singulating layers of folded cloth and garments. Supplementary material is available at https://sites.google.com/view/slip-bagging/.