 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOmni-Scan: Creating Visually-Accurate Digital Twin Object Models Using a Bimanual Robot with Handover and Gaussian Splat Merging
Aug 01, 20253D Gaussian Splats (3DGSs) are 3D object models derived from multi-view images. Such "digital twins" are useful for simulations, virtual reality, marketing, robot policy fine-tuning, and part inspection. 3D object scanning usually requires multi-camera arrays, precise laser scanners, or robot wrist-mounted cameras, which have restricted workspaces. We propose Omni-Scan, a pipeline for producing high-quality 3D Gaussian Splat models using a bi-manual robot that grasps an object with one gripper and rotates the object with respect to a stationary camera. The object is then re-grasped by a second gripper to expose surfaces that were occluded by the first gripper. We present the Omni-Scan robot pipeline using DepthAny-thing, Segment Anything, as well as RAFT optical flow models to identify and isolate objects held by a robot gripper while removing the gripper and the background. We then modify the 3DGS training pipeline to support concatenated datasets with gripper occlusion, producing an omni-directional (360 degree view) model of the object. We apply Omni-Scan to part defect inspection, finding that it can identify visual or geometric defects in 12 different industrial and household objects with an average accuracy of 83%. Interactive videos of Omni-Scan 3DGS models can be found at https://berkeleyautomation.github.io/omni-scan/
Real2Render2Real: Scaling Robot Data Without Dynamics Simulation or Robot Hardware
May 14, 2025
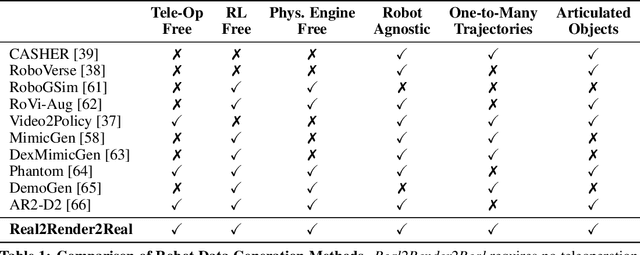
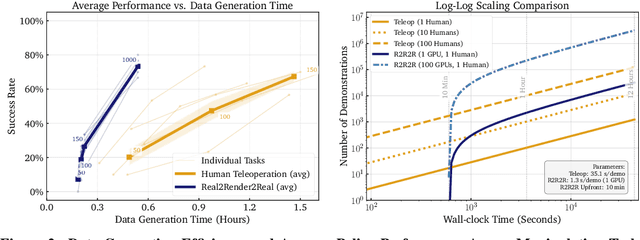
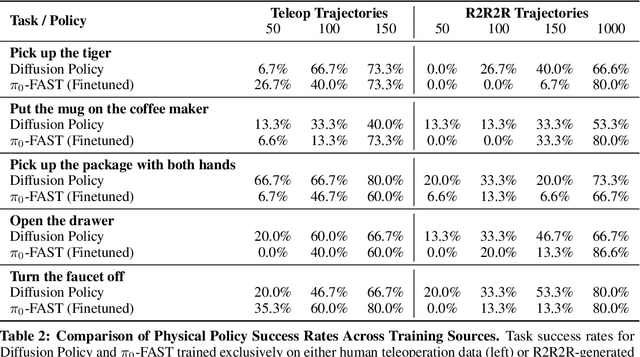
Scaling robot learning requires vast and diverse datasets. Yet the prevailing data collection paradigm-human teleoperation-remains costly and constrained by manual effort and physical robot access. We introduce Real2Render2Real (R2R2R), a novel approach for generating robot training data without relying on object dynamics simulation or teleoperation of robot hardware. The input is a smartphone-captured scan of one or more objects and a single video of a human demonstration. R2R2R renders thousands of high visual fidelity robot-agnostic demonstrations by reconstructing detailed 3D object geometry and appearance, and tracking 6-DoF object motion. R2R2R uses 3D Gaussian Splatting (3DGS) to enable flexible asset generation and trajectory synthesis for both rigid and articulated objects, converting these representations to meshes to maintain compatibility with scalable rendering engines like IsaacLab but with collision modeling off. Robot demonstration data generated by R2R2R integrates directly with models that operate on robot proprioceptive states and image observations, such as vision-language-action models (VLA) and imitation learning policies. Physical experiments suggest that models trained on R2R2R data from a single human demonstration can match the performance of models trained on 150 human teleoperation demonstrations. Project page: https://real2render2real.com
Persistent Object Gaussian Splat (POGS) for Tracking Human and Robot Manipulation of Irregularly Shaped Objects
Mar 07, 2025
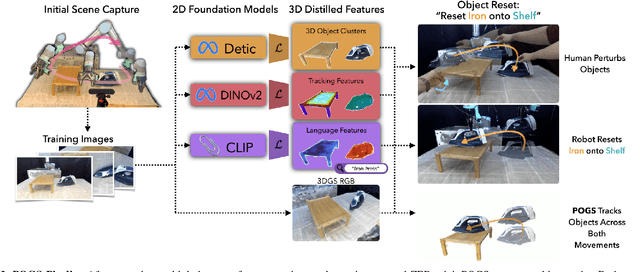


Tracking and manipulating irregularly-shaped, previously unseen objects in dynamic environments is important for robotic applications in manufacturing, assembly, and logistics. Recently introduced Gaussian Splats efficiently model object geometry, but lack persistent state estimation for task-oriented manipulation. We present Persistent Object Gaussian Splat (POGS), a system that embeds semantics, self-supervised visual features, and object grouping features into a compact representation that can be continuously updated to estimate the pose of scanned objects. POGS updates object states without requiring expensive rescanning or prior CAD models of objects. After an initial multi-view scene capture and training phase, POGS uses a single stereo camera to integrate depth estimates along with self-supervised vision encoder features for object pose estimation. POGS supports grasping, reorientation, and natural language-driven manipulation by refining object pose estimates, facilitating sequential object reset operations with human-induced object perturbations and tool servoing, where robots recover tool pose despite tool perturbations of up to 30{\deg}. POGS achieves up to 12 consecutive successful object resets and recovers from 80% of in-grasp tool perturbations.
Language-Embedded Gaussian Splats (LEGS): Incrementally Building Room-Scale Representations with a Mobile Robot
Sep 26, 2024
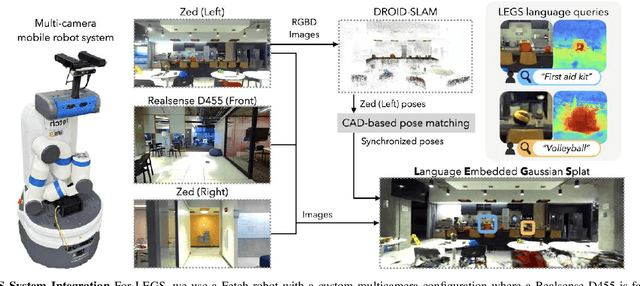


Building semantic 3D maps is valuable for searching for objects of interest in offices, warehouses, stores, and homes. We present a mapping system that incrementally builds a Language-Embedded Gaussian Splat (LEGS): a detailed 3D scene representation that encodes both appearance and semantics in a unified representation. LEGS is trained online as a robot traverses its environment to enable localization of open-vocabulary object queries. We evaluate LEGS on 4 room-scale scenes where we query for objects in the scene to assess how LEGS can capture semantic meaning. We compare LEGS to LERF and find that while both systems have comparable object query success rates, LEGS trains over 3.5x faster than LERF. Results suggest that a multi-camera setup and incremental bundle adjustment can boost visual reconstruction quality in constrained robot trajectories, and suggest LEGS can localize open-vocabulary and long-tail object queries with up to 66% accuracy.
Automating Deformable Gasket Assembly
Aug 22, 2024
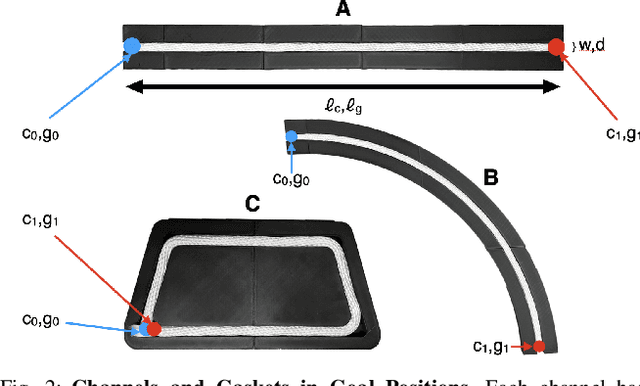
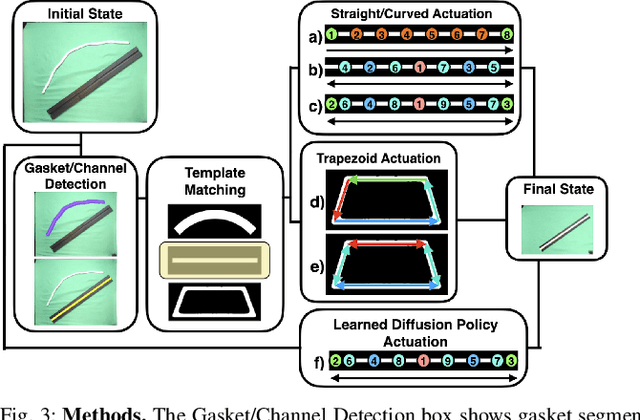

In Gasket Assembly, a deformable gasket must be aligned and pressed into a narrow channel. This task is common for sealing surfaces in the manufacturing of automobiles, appliances, electronics, and other products. Gasket Assembly is a long-horizon, high-precision task and the gasket must align with the channel and be fully pressed in to achieve a secure fit. To compare approaches, we present 4 methods for Gasket Assembly: one policy from deep imitation learning and three procedural algorithms. We evaluate these methods with 100 physical trials. Results suggest that the Binary+ algorithm succeeds in 10/10 on the straight channel whereas the learned policy based on 250 human teleoperated demonstrations succeeds in 8/10 trials and is significantly slower. Code, CAD models, videos, and data can be found at https://berkeleyautomation.github.io/robot-gasket/
SWAG: Storytelling With Action Guidance
Feb 05, 2024



Automated long-form story generation typically employs long-context large language models (LLMs) for one-shot creation, which can produce cohesive but not necessarily engaging content. We introduce Storytelling With Action Guidance (SWAG), a novel approach to storytelling with LLMs. Our approach reduces story writing to a search problem through a two-model feedback loop: one LLM generates story content, and another auxiliary LLM is used to choose the next best "action" to steer the story's future direction. Our results show that SWAG can substantially outperform previous end-to-end story generation techniques when evaluated by GPT-4 and through human evaluation, and our SWAG pipeline using only open-source models surpasses GPT-3.5-Turbo.