 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePoly-Autoregressive Prediction for Modeling Interactions
Feb 12, 2025We introduce a simple framework for predicting the behavior of an agent in multi-agent settings. In contrast to autoregressive (AR) tasks, such as language processing, our focus is on scenarios with multiple agents whose interactions are shaped by physical constraints and internal motivations. To this end, we propose Poly-Autoregressive (PAR) modeling, which forecasts an ego agent's future behavior by reasoning about the ego agent's state history and the past and current states of other interacting agents. At its core, PAR represents the behavior of all agents as a sequence of tokens, each representing an agent's state at a specific timestep. With minimal data pre-processing changes, we show that PAR can be applied to three different problems: human action forecasting in social situations, trajectory prediction for autonomous vehicles, and object pose forecasting during hand-object interaction. Using a small proof-of-concept transformer backbone, PAR outperforms AR across these three scenarios. The project website can be found at https://neerja.me/PAR/.
Automating Deformable Gasket Assembly
Aug 22, 2024
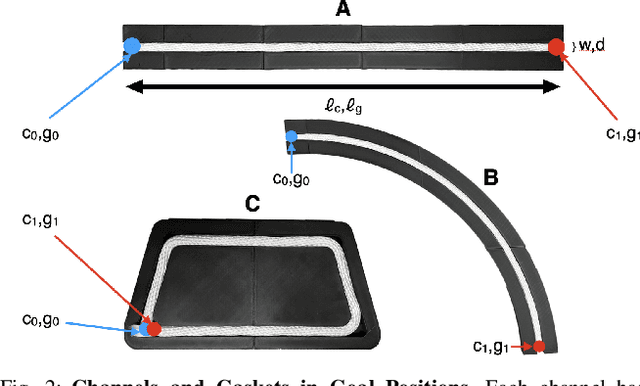
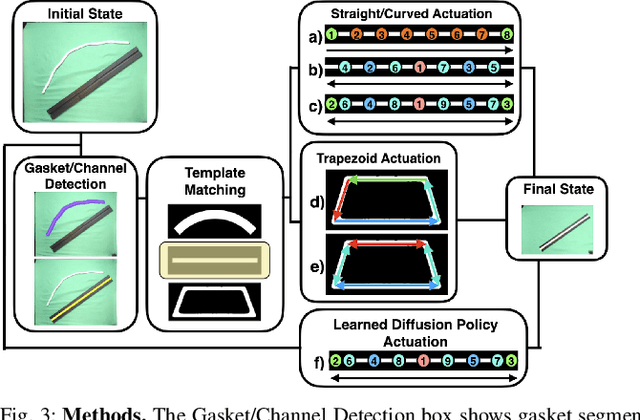

In Gasket Assembly, a deformable gasket must be aligned and pressed into a narrow channel. This task is common for sealing surfaces in the manufacturing of automobiles, appliances, electronics, and other products. Gasket Assembly is a long-horizon, high-precision task and the gasket must align with the channel and be fully pressed in to achieve a secure fit. To compare approaches, we present 4 methods for Gasket Assembly: one policy from deep imitation learning and three procedural algorithms. We evaluate these methods with 100 physical trials. Results suggest that the Binary+ algorithm succeeds in 10/10 on the straight channel whereas the learned policy based on 250 human teleoperated demonstrations succeeds in 8/10 trials and is significantly slower. Code, CAD models, videos, and data can be found at https://berkeleyautomation.github.io/robot-gasket/
STITCH: Augmented Dexterity for Suture Throws Including Thread Coordination and Handoffs
Apr 08, 2024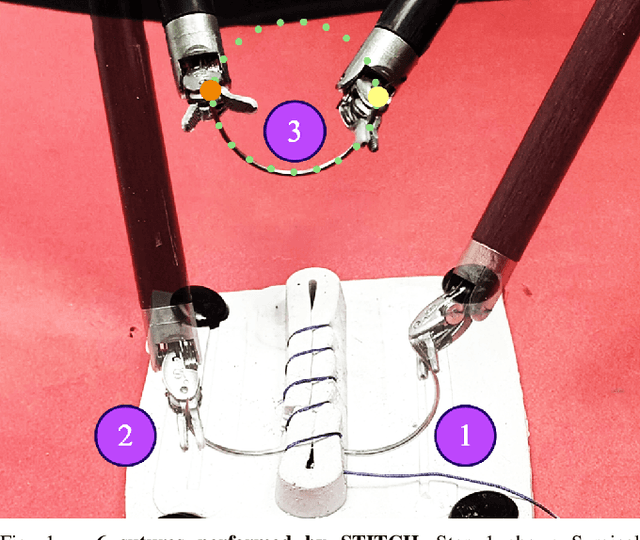
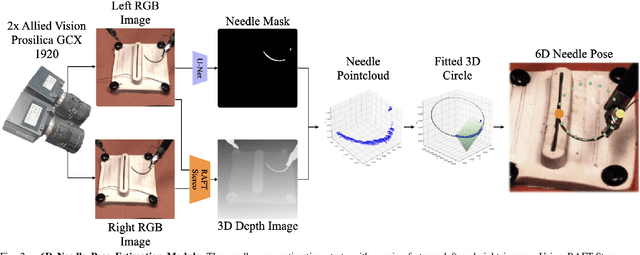
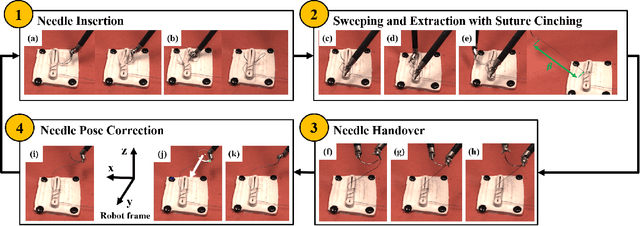
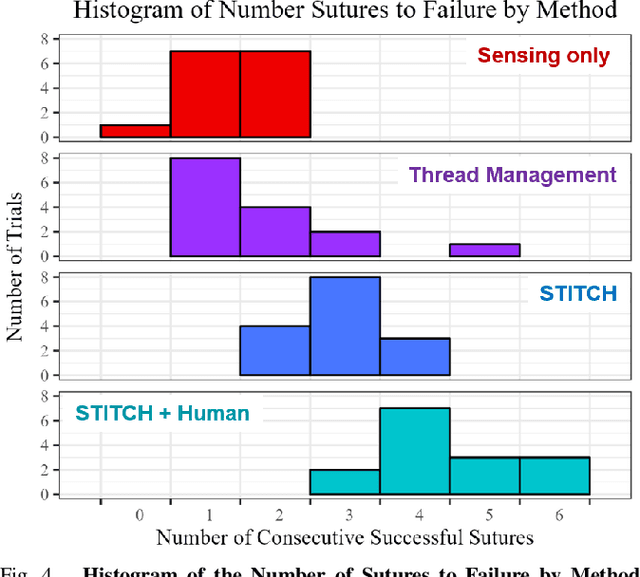
We present STITCH: an augmented dexterity pipeline that performs Suture Throws Including Thread Coordination and Handoffs. STITCH iteratively performs needle insertion, thread sweeping, needle extraction, suture cinching, needle handover, and needle pose correction with failure recovery policies. We introduce a novel visual 6D needle pose estimation framework using a stereo camera pair and new suturing motion primitives. We compare STITCH to baselines, including a proprioception-only and a policy without visual servoing. In physical experiments across 15 trials, STITCH achieves an average of 2.93 sutures without human intervention and 4.47 sutures with human intervention. See https://sites.google.com/berkeley.edu/stitch for code and supplemental materials.
ShaSTA-Fuse: Camera-LiDAR Sensor Fusion to Model Shape and Spatio-Temporal Affinities for 3D Multi-Object Tracking
Oct 04, 2023


3D multi-object tracking (MOT) is essential for an autonomous mobile agent to safely navigate a scene. In order to maximize the perception capabilities of the autonomous agent, we aim to develop a 3D MOT framework that fuses camera and LiDAR sensor information. Building on our prior LiDAR-only work, ShaSTA, which models shape and spatio-temporal affinities for 3D MOT, we propose a novel camera-LiDAR fusion approach for learning affinities. At its core, this work proposes a fusion technique that generates a rich sensory signal incorporating information about depth and distant objects to enhance affinity estimation for improved data association, track lifecycle management, false-positive elimination, false-negative propagation, and track confidence score refinement. Our main contributions include a novel fusion approach for combining camera and LiDAR sensory signals to learn affinities, and a first-of-its-kind multimodal sequential track confidence refinement technique that fuses 2D and 3D detections. Additionally, we perform an ablative analysis on each fusion step to demonstrate the added benefits of incorporating the camera sensor, particular for small, distant objects that tend to suffer from the depth-sensing limits and sparsity of LiDAR sensors. In sum, our technique achieves state-of-the-art performance on the nuScenes benchmark amongst multimodal 3D MOT algorithms using CenterPoint detections.
ShaSTA: Modeling Shape and Spatio-Temporal Affinities for 3D Multi-Object Tracking
Nov 08, 2022



Multi-object tracking is a cornerstone capability of any robotic system. Most approaches follow a tracking-by-detection paradigm. However, within this framework, detectors function in a low precision-high recall regime, ensuring a low number of false-negatives while producing a high rate of false-positives. This can negatively affect the tracking component by making data association and track lifecycle management more challenging. Additionally, false-negative detections due to difficult scenarios like occlusions can negatively affect tracking performance. Thus, we propose a method that learns shape and spatio-temporal affinities between consecutive frames to better distinguish between true-positive and false-positive detections and tracks, while compensating for false-negative detections. Our method provides a probabilistic matching of detections that leads to robust data association and track lifecycle management. We quantitatively evaluate our method through ablative experiments and on the nuScenes tracking benchmark where we achieve state-of-the-art results. Our method not only estimates accurate, high-quality tracks but also decreases the overall number of false-positive and false-negative tracks. Please see our project website for source code and demo videos: sites.google.com/view/shasta-3d-mot/home.
On Distributed Quantization for Classification
Nov 01, 2019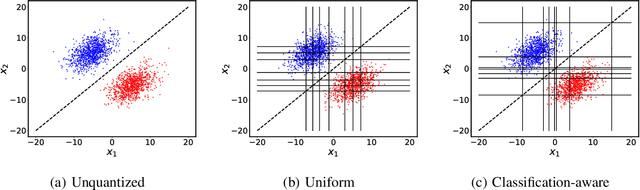
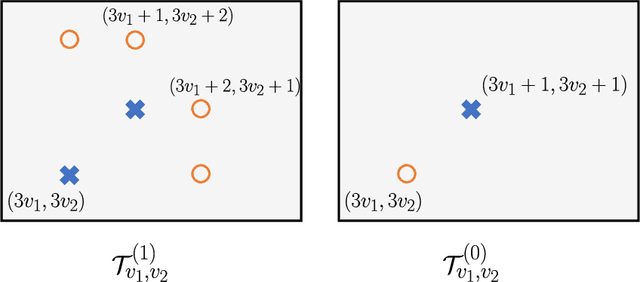
We consider the problem of distributed feature quantization, where the goal is to enable a pretrained classifier at a central node to carry out its classification on features that are gathered from distributed nodes through communication constrained channels. We propose the design of distributed quantization schemes specifically tailored to the classification task: unlike quantization schemes that help the central node reconstruct the original signal as accurately as possible, our focus is not reconstruction accuracy, but instead correct classification. Our work does not make any apriori distributional assumptions on the data, but instead uses training data for the quantizer design. Our main contributions include: we prove NP-hardness of finding optimal quantizers in the general case; we design an optimal scheme for a special case; we propose quantization algorithms, that leverage discrete neural representations and training data, and can be designed in polynomial-time for any number of features, any number of classes, and arbitrary division of features across the distributed nodes. We find that tailoring the quantizers to the classification task can offer significant savings: as compared to alternatives, we can achieve more than a factor of two reduction in terms of the number of bits communicated, for the same classification accuracy.