 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBack into Plato's Cave: Examining Cross-modal Representational Convergence at Scale
Apr 20, 2026The Platonic Representation Hypothesis suggests that neural networks trained on different modalities (e.g., text and images) align and eventually converge toward the same representation of reality. If true, this has significant implications for whether modality choice matters at all. We show that the experimental evidence for this hypothesis is fragile and depends critically on the evaluation regime. Alignment is measured using mutual nearest neighbors on small datasets ($\approx$1K samples) and degrades substantially as the dataset is scaled to millions of samples. The alignment that remains between model representations reflects coarse semantic overlap rather than consistent fine-grained structure. Moreover, the evaluations in Huh et al. are done in a one-to-one image-caption setting, a constraint that breaks down in realistic many-to-many settings and further reduces alignment. We also find that the reported trend of stronger language models increasingly aligning with vision does not appear to hold for newer models. Overall, our findings suggest that the current evidence for cross-modal representational convergence is considerably weaker than subsequent works have taken it to be. Models trained on different modalities may learn equally rich representations of the world, just not the same one.
Forecasting Motion in the Wild
Apr 01, 2026Visual intelligence requires anticipating the future behavior of agents, yet vision systems lack a general representation for motion and behavior. We propose dense point trajectories as visual tokens for behavior, a structured mid-level representation that disentangles motion from appearance and generalizes across diverse non-rigid agents, such as animals in-the-wild. Building on this abstraction, we design a diffusion transformer that models unordered sets of trajectories and explicitly reasons about occlusion, enabling coherent forecasts of complex motion patterns. To evaluate at scale, we curate 300 hours of unconstrained animal video with robust shot detection and camera-motion compensation. Experiments show that forecasting trajectory tokens achieves category-agnostic, data-efficient prediction, outperforms state-of-the-art baselines, and generalizes to rare species and morphologies, providing a foundation for predictive visual intelligence in the wild.
Empowerment Gain and Causal Model Construction: Children and adults are sensitive to controllability and variability in their causal interventions
Dec 09, 2025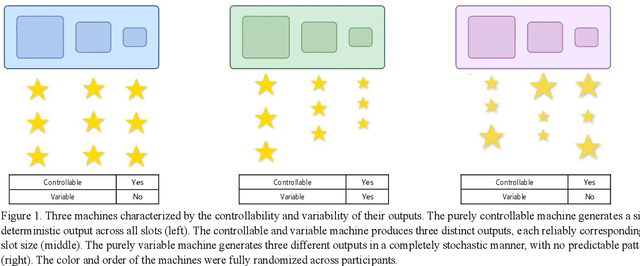

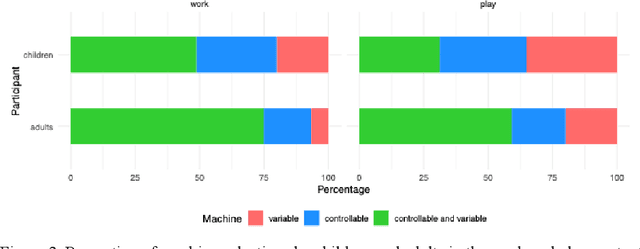

Learning about the causal structure of the world is a fundamental problem for human cognition. Causal models and especially causal learning have proved to be difficult for large pretrained models using standard techniques of deep learning. In contrast, cognitive scientists have applied advances in our formal understanding of causation in computer science, particularly within the Causal Bayes Net formalism, to understand human causal learning. In the very different tradition of reinforcement learning, researchers have described an intrinsic reward signal called "empowerment" which maximizes mutual information between actions and their outcomes. "Empowerment" may be an important bridge between classical Bayesian causal learning and reinforcement learning and may help to characterize causal learning in humans and enable it in machines. If an agent learns an accurate causal world model, they will necessarily increase their empowerment, and increasing empowerment will lead to a more accurate causal world model. Empowerment may also explain distinctive features of childrens causal learning, as well as providing a more tractable computational account of how that learning is possible. In an empirical study, we systematically test how children and adults use cues to empowerment to infer causal relations, and design effective causal interventions.
Poly-Autoregressive Prediction for Modeling Interactions
Feb 12, 2025We introduce a simple framework for predicting the behavior of an agent in multi-agent settings. In contrast to autoregressive (AR) tasks, such as language processing, our focus is on scenarios with multiple agents whose interactions are shaped by physical constraints and internal motivations. To this end, we propose Poly-Autoregressive (PAR) modeling, which forecasts an ego agent's future behavior by reasoning about the ego agent's state history and the past and current states of other interacting agents. At its core, PAR represents the behavior of all agents as a sequence of tokens, each representing an agent's state at a specific timestep. With minimal data pre-processing changes, we show that PAR can be applied to three different problems: human action forecasting in social situations, trajectory prediction for autonomous vehicles, and object pose forecasting during hand-object interaction. Using a small proof-of-concept transformer backbone, PAR outperforms AR across these three scenarios. The project website can be found at https://neerja.me/PAR/.
Gaussian Masked Autoencoders
Jan 06, 2025



This paper explores Masked Autoencoders (MAE) with Gaussian Splatting. While reconstructive self-supervised learning frameworks such as MAE learns good semantic abstractions, it is not trained for explicit spatial awareness. Our approach, named Gaussian Masked Autoencoder, or GMAE, aims to learn semantic abstractions and spatial understanding jointly. Like MAE, it reconstructs the image end-to-end in the pixel space, but beyond MAE, it also introduces an intermediate, 3D Gaussian-based representation and renders images via splatting. We show that GMAE can enable various zero-shot learning capabilities of spatial understanding (e.g., figure-ground segmentation, image layering, edge detection, etc.) while preserving the high-level semantics of self-supervised representation quality from MAE. To our knowledge, we are the first to employ Gaussian primitives in an image representation learning framework beyond optimization-based single-scene reconstructions. We believe GMAE will inspire further research in this direction and contribute to developing next-generation techniques for modeling high-fidelity visual data. More details at https://brjathu.github.io/gmae
Synergy and Synchrony in Couple Dances
Sep 06, 2024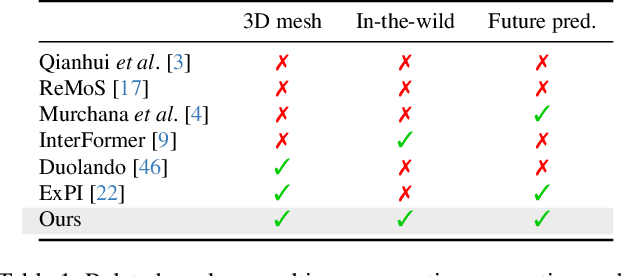
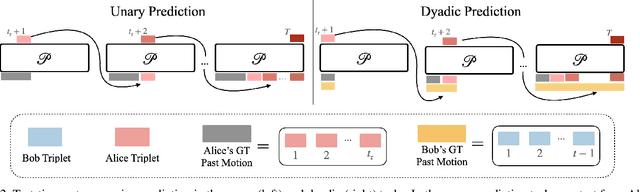
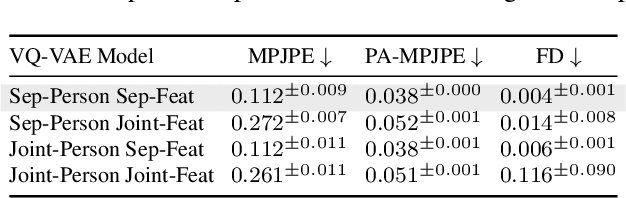
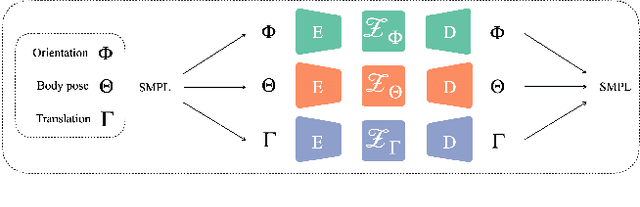
This paper asks to what extent social interaction influences one's behavior. We study this in the setting of two dancers dancing as a couple. We first consider a baseline in which we predict a dancer's future moves conditioned only on their past motion without regard to their partner. We then investigate the advantage of taking social information into account by conditioning also on the motion of their dancing partner. We focus our analysis on Swing, a dance genre with tight physical coupling for which we present an in-the-wild video dataset. We demonstrate that single-person future motion prediction in this context is challenging. Instead, we observe that prediction greatly benefits from considering the interaction partners' behavior, resulting in surprisingly compelling couple dance synthesis results (see supp. video). Our contributions are a demonstration of the advantages of socially conditioned future motion prediction and an in-the-wild, couple dance video dataset to enable future research in this direction. Video results are available on the project website: https://von31.github.io/synNsync
KiVA: Kid-inspired Visual Analogies for Testing Large Multimodal Models
Jul 25, 2024



This paper investigates visual analogical reasoning in large multimodal models (LMMs) compared to human adults and children. A "visual analogy" is an abstract rule inferred from one image and applied to another. While benchmarks exist for testing visual reasoning in LMMs, they require advanced skills and omit basic visual analogies that even young children can make. Inspired by developmental psychology, we propose a new benchmark of 1,400 visual transformations of everyday objects to test LMMs on visual analogical reasoning and compare them to children and adults. We structure the evaluation into three stages: identifying what changed (e.g., color, number, etc.), how it changed (e.g., added one object), and applying the rule to new scenarios. Our findings show that while models like GPT-4V, LLaVA-1.5, and MANTIS identify the "what" effectively, they struggle with quantifying the "how" and extrapolating this rule to new objects. In contrast, children and adults exhibit much stronger analogical reasoning at all three stages. Additionally, the strongest tested model, GPT-4V, performs better in tasks involving simple visual attributes like color and size, correlating with quicker human adult response times. Conversely, more complex tasks such as number, rotation, and reflection, which necessitate extensive cognitive processing and understanding of the 3D physical world, present more significant challenges. Altogether, these findings highlight the limitations of training models on data that primarily consists of 2D images and text.
Diffusion Models as Data Mining Tools
Jul 20, 2024This paper demonstrates how to use generative models trained for image synthesis as tools for visual data mining. Our insight is that since contemporary generative models learn an accurate representation of their training data, we can use them to summarize the data by mining for visual patterns. Concretely, we show that after finetuning conditional diffusion models to synthesize images from a specific dataset, we can use these models to define a typicality measure on that dataset. This measure assesses how typical visual elements are for different data labels, such as geographic location, time stamps, semantic labels, or even the presence of a disease. This analysis-by-synthesis approach to data mining has two key advantages. First, it scales much better than traditional correspondence-based approaches since it does not require explicitly comparing all pairs of visual elements. Second, while most previous works on visual data mining focus on a single dataset, our approach works on diverse datasets in terms of content and scale, including a historical car dataset, a historical face dataset, a large worldwide street-view dataset, and an even larger scene dataset. Furthermore, our approach allows for translating visual elements across class labels and analyzing consistent changes.
Pose Priors from Language Models
May 06, 2024We present a zero-shot pose optimization method that enforces accurate physical contact constraints when estimating the 3D pose of humans. Our central insight is that since language is often used to describe physical interaction, large pretrained text-based models can act as priors on pose estimation. We can thus leverage this insight to improve pose estimation by converting natural language descriptors, generated by a large multimodal model (LMM), into tractable losses to constrain the 3D pose optimization. Despite its simplicity, our method produces surprisingly compelling pose reconstructions of people in close contact, correctly capturing the semantics of the social and physical interactions. We demonstrate that our method rivals more complex state-of-the-art approaches that require expensive human annotation of contact points and training specialized models. Moreover, unlike previous approaches, our method provides a unified framework for resolving self-contact and person-to-person contact.
Can Language Models Learn to Listen?
Aug 21, 2023



We present a framework for generating appropriate facial responses from a listener in dyadic social interactions based on the speaker's words. Given an input transcription of the speaker's words with their timestamps, our approach autoregressively predicts a response of a listener: a sequence of listener facial gestures, quantized using a VQ-VAE. Since gesture is a language component, we propose treating the quantized atomic motion elements as additional language token inputs to a transformer-based large language model. Initializing our transformer with the weights of a language model pre-trained only on text results in significantly higher quality listener responses than training a transformer from scratch. We show that our generated listener motion is fluent and reflective of language semantics through quantitative metrics and a qualitative user study. In our evaluation, we analyze the model's ability to utilize temporal and semantic aspects of spoken text. Project page: https://people.eecs.berkeley.edu/~evonne_ng/projects/text2listen/