 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHuman Adults and LLMs as Scientists: Who Benefits from Active Exploration?
Jun 04, 2026A long-standing finding in the causal learning literature is that adults struggle to identify conjunctive causal rules, where an effect requires the simultaneous presence of multiple causes, while performing better in disjunctive settings. However, most demonstrations of this ``conjunctive handicap'' rely on passive observation paradigms with limited evidence, where learners have no control over evidence generation. This paper asks whether this bias persists when adults are granted agency through active exploration. Using a modified ``blicket detector'' task, adult participants freely intervened to identify causal objects under conjunctive or disjunctive rule structures. We show that active exploration substantially improves adults' conjunctive causal reasoning, although conjunctive rules still require more tests to infer than disjunctive rules. We further compare human performance to a range of large language models in the same setting. While some state-of-the-art models approach human-level performance on hypothesis inference accuracy, they often exhibit less efficient exploration strategies and similar conjunctive-disjunctive performance gaps.
Empowerment Gain and Causal Model Construction: Children and adults are sensitive to controllability and variability in their causal interventions
Dec 09, 2025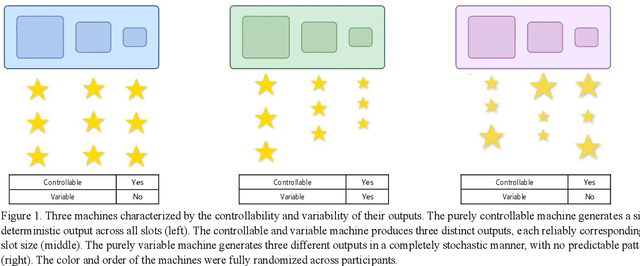

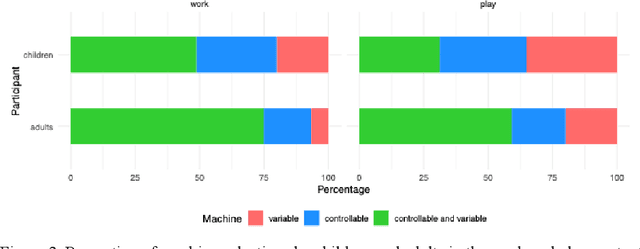

Learning about the causal structure of the world is a fundamental problem for human cognition. Causal models and especially causal learning have proved to be difficult for large pretrained models using standard techniques of deep learning. In contrast, cognitive scientists have applied advances in our formal understanding of causation in computer science, particularly within the Causal Bayes Net formalism, to understand human causal learning. In the very different tradition of reinforcement learning, researchers have described an intrinsic reward signal called "empowerment" which maximizes mutual information between actions and their outcomes. "Empowerment" may be an important bridge between classical Bayesian causal learning and reinforcement learning and may help to characterize causal learning in humans and enable it in machines. If an agent learns an accurate causal world model, they will necessarily increase their empowerment, and increasing empowerment will lead to a more accurate causal world model. Empowerment may also explain distinctive features of childrens causal learning, as well as providing a more tractable computational account of how that learning is possible. In an empirical study, we systematically test how children and adults use cues to empowerment to infer causal relations, and design effective causal interventions.
KiVA: Kid-inspired Visual Analogies for Testing Large Multimodal Models
Jul 25, 2024



This paper investigates visual analogical reasoning in large multimodal models (LMMs) compared to human adults and children. A "visual analogy" is an abstract rule inferred from one image and applied to another. While benchmarks exist for testing visual reasoning in LMMs, they require advanced skills and omit basic visual analogies that even young children can make. Inspired by developmental psychology, we propose a new benchmark of 1,400 visual transformations of everyday objects to test LMMs on visual analogical reasoning and compare them to children and adults. We structure the evaluation into three stages: identifying what changed (e.g., color, number, etc.), how it changed (e.g., added one object), and applying the rule to new scenarios. Our findings show that while models like GPT-4V, LLaVA-1.5, and MANTIS identify the "what" effectively, they struggle with quantifying the "how" and extrapolating this rule to new objects. In contrast, children and adults exhibit much stronger analogical reasoning at all three stages. Additionally, the strongest tested model, GPT-4V, performs better in tasks involving simple visual attributes like color and size, correlating with quicker human adult response times. Conversely, more complex tasks such as number, rotation, and reflection, which necessitate extensive cognitive processing and understanding of the 3D physical world, present more significant challenges. Altogether, these findings highlight the limitations of training models on data that primarily consists of 2D images and text.
Imitation versus Innovation: What children can do that large language and language-and-vision models cannot (yet)?
May 08, 2023

Much discussion about large language models and language-and-vision models has focused on whether these models are intelligent agents. We present an alternative perspective. We argue that these artificial intelligence models are cultural technologies that enhance cultural transmission in the modern world, and are efficient imitation engines. We explore what AI models can tell us about imitation and innovation by evaluating their capacity to design new tools and discover novel causal structures, and contrast their responses with those of human children. Our work serves as a first step in determining which particular representations and competences, as well as which kinds of knowledge or skill, can be derived from particular learning techniques and data. Critically, our findings suggest that machines may need more than large scale language and images to achieve what a child can do.