 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEmpowerment Gain and Causal Model Construction: Children and adults are sensitive to controllability and variability in their causal interventions
Dec 09, 2025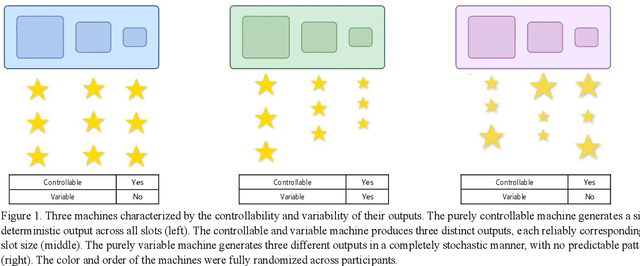

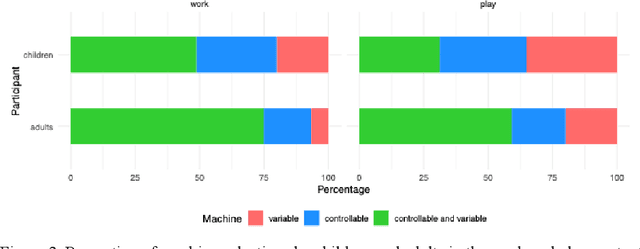

Learning about the causal structure of the world is a fundamental problem for human cognition. Causal models and especially causal learning have proved to be difficult for large pretrained models using standard techniques of deep learning. In contrast, cognitive scientists have applied advances in our formal understanding of causation in computer science, particularly within the Causal Bayes Net formalism, to understand human causal learning. In the very different tradition of reinforcement learning, researchers have described an intrinsic reward signal called "empowerment" which maximizes mutual information between actions and their outcomes. "Empowerment" may be an important bridge between classical Bayesian causal learning and reinforcement learning and may help to characterize causal learning in humans and enable it in machines. If an agent learns an accurate causal world model, they will necessarily increase their empowerment, and increasing empowerment will lead to a more accurate causal world model. Empowerment may also explain distinctive features of childrens causal learning, as well as providing a more tractable computational account of how that learning is possible. In an empirical study, we systematically test how children and adults use cues to empowerment to infer causal relations, and design effective causal interventions.
Intrinsically-Motivated Humans and Agents in Open-World Exploration
Mar 31, 2025What drives exploration? Understanding intrinsic motivation is a long-standing challenge in both cognitive science and artificial intelligence; numerous objectives have been proposed and used to train agents, yet there remains a gap between human and agent exploration. We directly compare adults, children, and AI agents in a complex open-ended environment, Crafter, and study how common intrinsic objectives: Entropy, Information Gain, and Empowerment, relate to their behavior. We find that only Entropy and Empowerment are consistently positively correlated with human exploration progress, indicating that these objectives may better inform intrinsic reward design for agents. Furthermore, across agents and humans we observe that Entropy initially increases rapidly, then plateaus, while Empowerment increases continuously, suggesting that state diversity may provide more signal in early exploration, while advanced exploration should prioritize control. Finally, we find preliminary evidence that private speech utterances, and particularly goal verbalizations, may aid exploration in children.
KiVA: Kid-inspired Visual Analogies for Testing Large Multimodal Models
Jul 25, 2024



This paper investigates visual analogical reasoning in large multimodal models (LMMs) compared to human adults and children. A "visual analogy" is an abstract rule inferred from one image and applied to another. While benchmarks exist for testing visual reasoning in LMMs, they require advanced skills and omit basic visual analogies that even young children can make. Inspired by developmental psychology, we propose a new benchmark of 1,400 visual transformations of everyday objects to test LMMs on visual analogical reasoning and compare them to children and adults. We structure the evaluation into three stages: identifying what changed (e.g., color, number, etc.), how it changed (e.g., added one object), and applying the rule to new scenarios. Our findings show that while models like GPT-4V, LLaVA-1.5, and MANTIS identify the "what" effectively, they struggle with quantifying the "how" and extrapolating this rule to new objects. In contrast, children and adults exhibit much stronger analogical reasoning at all three stages. Additionally, the strongest tested model, GPT-4V, performs better in tasks involving simple visual attributes like color and size, correlating with quicker human adult response times. Conversely, more complex tasks such as number, rotation, and reflection, which necessitate extensive cognitive processing and understanding of the 3D physical world, present more significant challenges. Altogether, these findings highlight the limitations of training models on data that primarily consists of 2D images and text.
Children's Mental Models of Generative Visual and Text Based AI Models
May 21, 2024In this work we investigate how children ages 5-12 perceive, understand, and use generative AI models such as a text-based LLMs ChatGPT and a visual-based model DALL-E. Generative AI is newly being used widely since chatGPT. Children are also building mental models of generative AI. Those haven't been studied before and it is also the case that the children's models are dynamic as they use the tools, even with just very short usage. Upon surveying and experimentally observing over 40 children ages 5-12, we found that children generally have a very positive outlook towards AI and are excited about the ways AI may benefit and aid them in their everyday lives. In a forced choice, children robustly associated AI with positive adjectives versus negative ones. We also categorize what children are querying AI models for and find that children search for more imaginative things that don't exist when using a visual-based AI and not when using a text-based one. Our follow-up study monitored children's responses and feelings towards AI before and after interacting with GenAI models. We even find that children find AI to be less scary after interacting with it. We hope that these findings will shine a light on children's mental models of AI and provide insight for how to design the best possible tools for children who will inevitably be using AI in their lifetimes. The motivation of this work is to bridge the gap between Human-Computer Interaction (HCI) and Psychology in an effort to study the effects of AI on society. We aim to identify the gaps in humans' mental models of what AI is and how it works. Previous work has investigated how both adults and children perceive various kinds of robots, computers, and other technological concepts. However, there is very little work investigating these concepts for generative AI models and not simply embodied robots or physical technology.
Comparing Machines and Children: Using Developmental Psychology Experiments to Assess the Strengths and Weaknesses of LaMDA Responses
May 18, 2023



Developmental psychologists have spent decades devising experiments to test the intelligence and knowledge of infants and children, tracing the origin of crucial concepts and capacities. Moreover, experimental techniques in developmental psychology have been carefully designed to discriminate the cognitive capacities that underlie particular behaviors. We propose that using classical experiments from child development is a particularly effective way to probe the computational abilities of AI models, in general, and LLMs in particular. First, the methodological techniques of developmental psychology, such as the use of novel stimuli to control for past experience or control conditions to determine whether children are using simple associations, can be equally helpful for assessing the capacities of LLMs. In parallel, testing LLMs in this way can tell us whether the information that is encoded in text is sufficient to enable particular responses, or whether those responses depend on other kinds of information, such as information from exploration of the physical world. In this work we adapt classical developmental experiments to evaluate the capabilities of LaMDA, a large language model from Google. We propose a novel LLM Response Score (LRS) metric which can be used to evaluate other language models, such as GPT. We find that LaMDA generates appropriate responses that are similar to those of children in experiments involving social understanding, perhaps providing evidence that knowledge of these domains is discovered through language. On the other hand, LaMDA's responses in early object and action understanding, theory of mind, and especially causal reasoning tasks are very different from those of young children, perhaps showing that these domains require more real-world, self-initiated exploration and cannot simply be learned from patterns in language input.
Imitation versus Innovation: What children can do that large language and language-and-vision models cannot (yet)?
May 08, 2023

Much discussion about large language models and language-and-vision models has focused on whether these models are intelligent agents. We present an alternative perspective. We argue that these artificial intelligence models are cultural technologies that enhance cultural transmission in the modern world, and are efficient imitation engines. We explore what AI models can tell us about imitation and innovation by evaluating their capacity to design new tools and discover novel causal structures, and contrast their responses with those of human children. Our work serves as a first step in determining which particular representations and competences, as well as which kinds of knowledge or skill, can be derived from particular learning techniques and data. Critically, our findings suggest that machines may need more than large scale language and images to achieve what a child can do.
Towards Understanding How Machines Can Learn Causal Overhypotheses
Jun 16, 2022
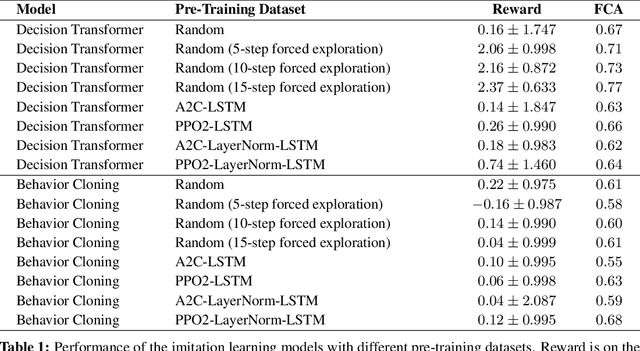

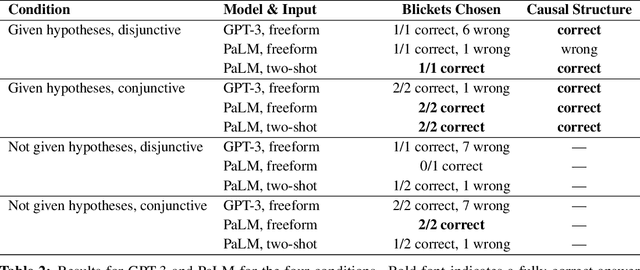
Recent work in machine learning and cognitive science has suggested that understanding causal information is essential to the development of intelligence. The extensive literature in cognitive science using the ``blicket detector'' environment shows that children are adept at many kinds of causal inference and learning. We propose to adapt that environment for machine learning agents. One of the key challenges for current machine learning algorithms is modeling and understanding causal overhypotheses: transferable abstract hypotheses about sets of causal relationships. In contrast, even young children spontaneously learn and use causal overhypotheses. In this work, we present a new benchmark -- a flexible environment which allows for the evaluation of existing techniques under variable causal overhypotheses -- and demonstrate that many existing state-of-the-art methods have trouble generalizing in this environment. The code and resources for this benchmark are available at https://github.com/CannyLab/casual_overhypotheses.
Learning Causal Overhypotheses through Exploration in Children and Computational Models
Feb 21, 2022

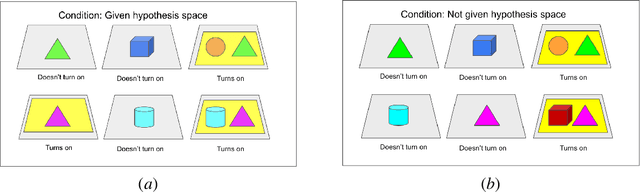
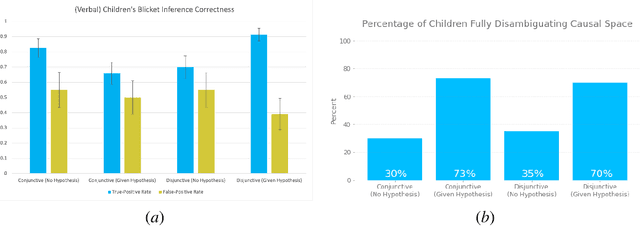
Despite recent progress in reinforcement learning (RL), RL algorithms for exploration still remain an active area of research. Existing methods often focus on state-based metrics, which do not consider the underlying causal structures of the environment, and while recent research has begun to explore RL environments for causal learning, these environments primarily leverage causal information through causal inference or induction rather than exploration. In contrast, human children - some of the most proficient explorers - have been shown to use causal information to great benefit. In this work, we introduce a novel RL environment designed with a controllable causal structure, which allows us to evaluate exploration strategies used by both agents and children in a unified environment. In addition, through experimentation on both computation models and children, we demonstrate that there are significant differences between information-gain optimal RL exploration in causal environments and the exploration of children in the same environments. We conclude with a discussion of how these findings may inspire new directions of research into efficient exploration and disambiguation of causal structures for RL algorithms.
Exploring Exploration: Comparing Children with RL Agents in Unified Environments
May 06, 2020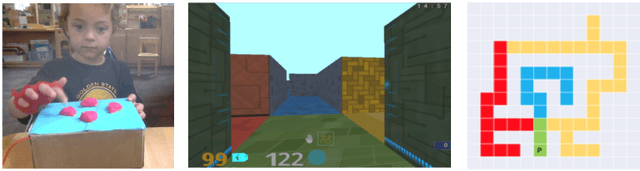
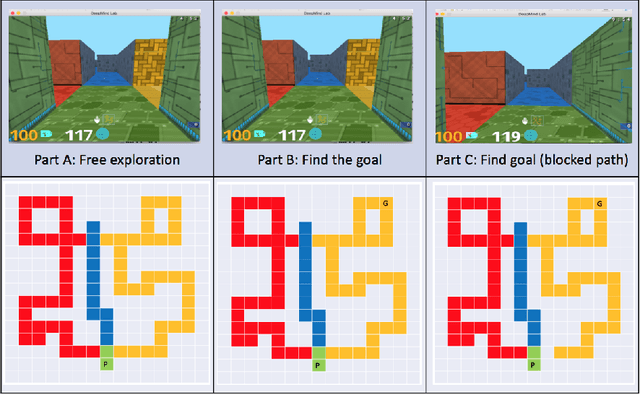
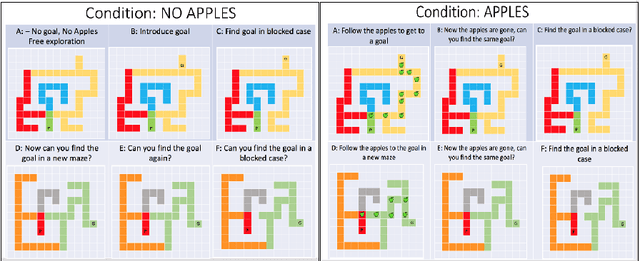
Research in developmental psychology consistently shows that children explore the world thoroughly and efficiently and that this exploration allows them to learn. In turn, this early learning supports more robust generalization and intelligent behavior later in life. While much work has gone into developing methods for exploration in machine learning, artificial agents have not yet reached the high standard set by their human counterparts. In this work we propose using DeepMind Lab (Beattie et al., 2016) as a platform to directly compare child and agent behaviors and to develop new exploration techniques. We outline two ongoing experiments to demonstrate the effectiveness of a direct comparison, and outline a number of open research questions that we believe can be tested using this methodology.
Evaluating Theory of Mind in Question Answering
Aug 28, 2018



We propose a new dataset for evaluating question answering models with respect to their capacity to reason about beliefs. Our tasks are inspired by theory-of-mind experiments that examine whether children are able to reason about the beliefs of others, in particular when those beliefs differ from reality. We evaluate a number of recent neural models with memory augmentation. We find that all fail on our tasks, which require keeping track of inconsistent states of the world; moreover, the models' accuracy decreases notably when random sentences are introduced to the tasks at test.