 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDistribution Aware Metrics for Conditional Natural Language Generation
Sep 29, 2022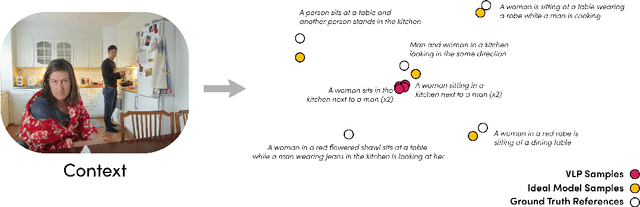
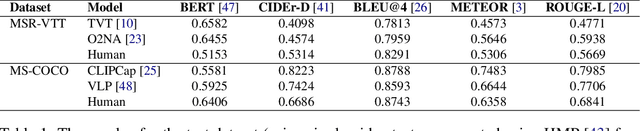

Traditional automated metrics for evaluating conditional natural language generation use pairwise comparisons between a single generated text and the best-matching gold-standard ground truth text. When multiple ground truths are available, scores are aggregated using an average or max operation across references. While this approach works well when diversity in the ground truth data (i.e. dispersion of the distribution of conditional texts) can be ascribed to noise, such as in automated speech recognition, it does not allow for robust evaluation in the case where diversity in the ground truths represents signal for the model. In this work we argue that existing metrics are not appropriate for domains such as visual description or summarization where ground truths are semantically diverse, and where the diversity in those captions captures useful additional information about the context. We propose a novel paradigm for multi-candidate evaluation of conditional language generation models, and a new family of metrics that compare the distributions of reference and model-generated caption sets using small sample sets of each. We demonstrate the utility of our approach with a case study in visual description: where we show that existing models optimize for single-description quality over diversity, and gain some insights into how sampling methods and temperature impact description quality and diversity.
Learning Causal Overhypotheses through Exploration in Children and Computational Models
Feb 21, 2022

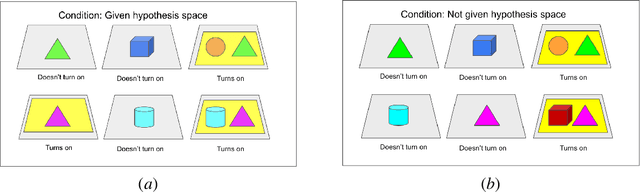
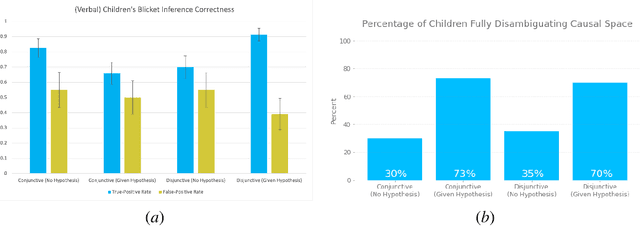
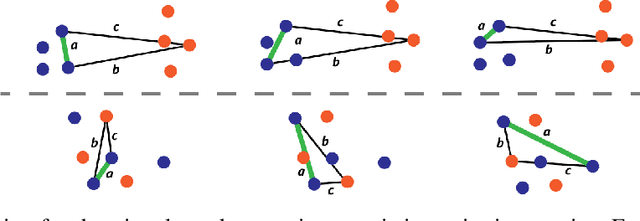
Despite recent progress in reinforcement learning (RL), RL algorithms for exploration still remain an active area of research. Existing methods often focus on state-based metrics, which do not consider the underlying causal structures of the environment, and while recent research has begun to explore RL environments for causal learning, these environments primarily leverage causal information through causal inference or induction rather than exploration. In contrast, human children - some of the most proficient explorers - have been shown to use causal information to great benefit. In this work, we introduce a novel RL environment designed with a controllable causal structure, which allows us to evaluate exploration strategies used by both agents and children in a unified environment. In addition, through experimentation on both computation models and children, we demonstrate that there are significant differences between information-gain optimal RL exploration in causal environments and the exploration of children in the same environments. We conclude with a discussion of how these findings may inspire new directions of research into efficient exploration and disambiguation of causal structures for RL algorithms.