 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNeptune: The Long Orbit to Benchmarking Long Video Understanding
Dec 12, 2024



This paper describes a semi-automatic pipeline to generate challenging question-answer-decoy sets for understanding long videos. Many existing video datasets and models are focused on short clips (10s-30s). While some long video datasets do exist, they can often be solved by powerful image models applied per frame (and often to very few frames) in a video, and are usually manually annotated at high cost. In order to mitigate both these problems, we propose a scalable dataset creation pipeline which leverages large models (VLMs and LLMs), to automatically generate dense, time-aligned video captions, as well as tough question answer decoy sets for video segments (up to 15 minutes in length). Our dataset Neptune covers a broad range of long video reasoning abilities and consists of a subset that emphasizes multimodal reasoning. Since existing metrics for open-ended question answering are either rule-based or may rely on proprietary models, we provide a new open source model-based metric GEM to score open-ended responses on Neptune. Benchmark evaluations reveal that most current open-source long video models perform poorly on Neptune, particularly on questions testing temporal ordering, counting and state changes. Through Neptune, we aim to spur the development of more advanced models capable of understanding long videos. The dataset is available at https://github.com/google-deepmind/neptune
Streaming Dense Video Captioning
Apr 01, 2024



An ideal model for dense video captioning -- predicting captions localized temporally in a video -- should be able to handle long input videos, predict rich, detailed textual descriptions, and be able to produce outputs before processing the entire video. Current state-of-the-art models, however, process a fixed number of downsampled frames, and make a single full prediction after seeing the whole video. We propose a streaming dense video captioning model that consists of two novel components: First, we propose a new memory module, based on clustering incoming tokens, which can handle arbitrarily long videos as the memory is of a fixed size. Second, we develop a streaming decoding algorithm that enables our model to make predictions before the entire video has been processed. Our model achieves this streaming ability, and significantly improves the state-of-the-art on three dense video captioning benchmarks: ActivityNet, YouCook2 and ViTT. Our code is released at https://github.com/google-research/scenic.
$IC^3$: Image Captioning by Committee Consensus
Feb 16, 2023

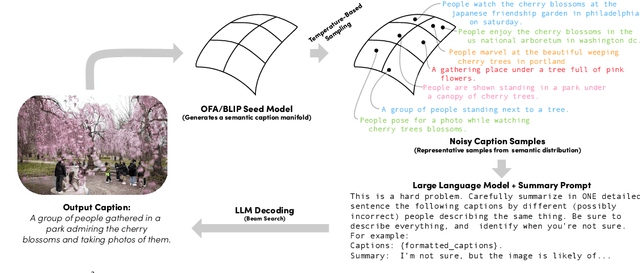

If you ask a human to describe an image, they might do so in a thousand different ways. Traditionally, image captioning models are trained to approximate the reference distribution of image captions, however, doing so encourages captions that are viewpoint-impoverished. Such captions often focus on only a subset of the possible details, while ignoring potentially useful information in the scene. In this work, we introduce a simple, yet novel, method: "Image Captioning by Committee Consensus" ($IC^3$), designed to generate a single caption that captures high-level details from several viewpoints. Notably, humans rate captions produced by $IC^3$ at least as helpful as baseline SOTA models more than two thirds of the time, and $IC^3$ captions can improve the performance of SOTA automated recall systems by up to 84%, indicating significant material improvements over existing SOTA approaches for visual description. Our code is publicly available at https://github.com/DavidMChan/caption-by-committee
Open-Vocabulary Temporal Action Detection with Off-the-Shelf Image-Text Features
Dec 20, 2022
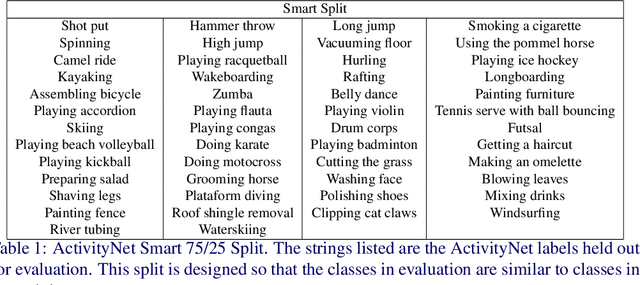


Detecting actions in untrimmed videos should not be limited to a small, closed set of classes. We present a simple, yet effective strategy for open-vocabulary temporal action detection utilizing pretrained image-text co-embeddings. Despite being trained on static images rather than videos, we show that image-text co-embeddings enable openvocabulary performance competitive with fully-supervised models. We show that the performance can be further improved by ensembling the image-text features with features encoding local motion, like optical flow based features, or other modalities, like audio. In addition, we propose a more reasonable open-vocabulary evaluation setting for the ActivityNet data set, where the category splits are based on similarity rather than random assignment.
Distribution Aware Metrics for Conditional Natural Language Generation
Sep 29, 2022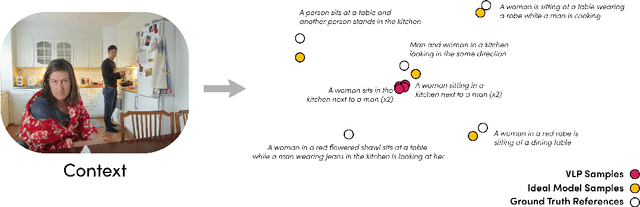
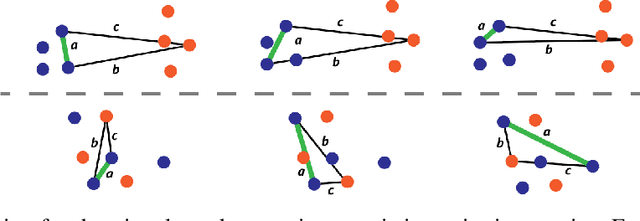

Traditional automated metrics for evaluating conditional natural language generation use pairwise comparisons between a single generated text and the best-matching gold-standard ground truth text. When multiple ground truths are available, scores are aggregated using an average or max operation across references. While this approach works well when diversity in the ground truth data (i.e. dispersion of the distribution of conditional texts) can be ascribed to noise, such as in automated speech recognition, it does not allow for robust evaluation in the case where diversity in the ground truths represents signal for the model. In this work we argue that existing metrics are not appropriate for domains such as visual description or summarization where ground truths are semantically diverse, and where the diversity in those captions captures useful additional information about the context. We propose a novel paradigm for multi-candidate evaluation of conditional language generation models, and a new family of metrics that compare the distributions of reference and model-generated caption sets using small sample sets of each. We demonstrate the utility of our approach with a case study in visual description: where we show that existing models optimize for single-description quality over diversity, and gain some insights into how sampling methods and temperature impact description quality and diversity.
What's in a Caption? Dataset-Specific Linguistic Diversity and Its Effect on Visual Description Models and Metrics
May 12, 2022
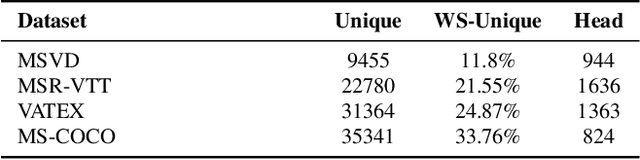
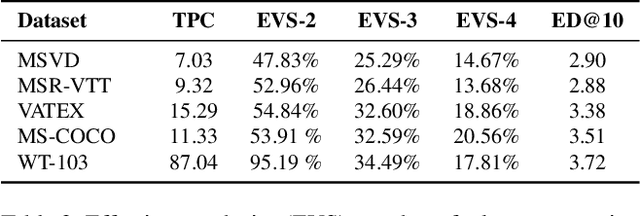
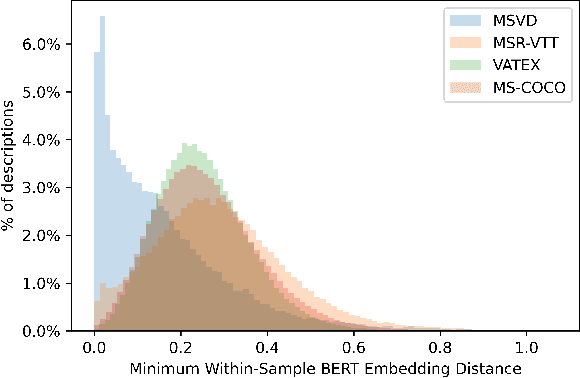
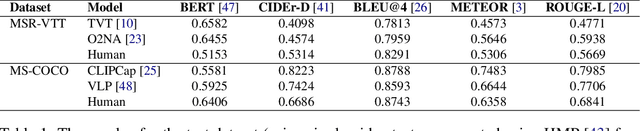
While there have been significant gains in the field of automated video description, the generalization performance of automated description models to novel domains remains a major barrier to using these systems in the real world. Most visual description methods are known to capture and exploit patterns in the training data leading to evaluation metric increases, but what are those patterns? In this work, we examine several popular visual description datasets, and capture, analyze, and understand the dataset-specific linguistic patterns that models exploit but do not generalize to new domains. At the token level, sample level, and dataset level, we find that caption diversity is a major driving factor behind the generation of generic and uninformative captions. We further show that state-of-the-art models even outperform held-out ground truth captions on modern metrics, and that this effect is an artifact of linguistic diversity in datasets. Understanding this linguistic diversity is key to building strong captioning models, we recommend several methods and approaches for maintaining diversity in the collection of new data, and dealing with the consequences of limited diversity when using current models and metrics.
VideoBERT: A Joint Model for Video and Language Representation Learning
Apr 03, 2019
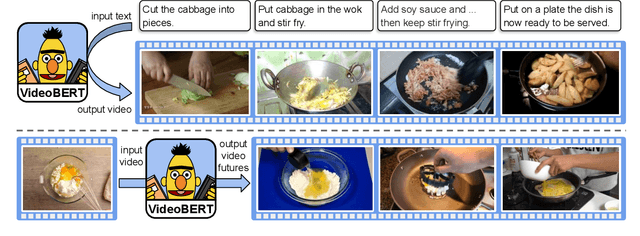

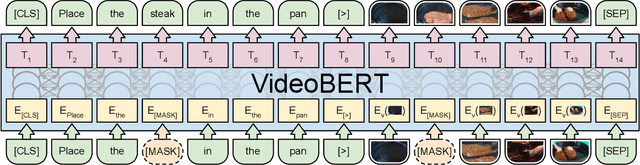
Self-supervised learning has become increasingly important to leverage the abundance of unlabeled data available on platforms like YouTube. Whereas most existing approaches learn low-level representations, we propose a joint visual-linguistic model to learn high-level features without any explicit supervision. In particular, inspired by its recent success in language modeling, we build upon the BERT model to learn bidirectional joint distributions over sequences of visual and linguistic tokens, derived from vector quantization of video data and off-the-shelf speech recognition outputs, respectively. We use this model in a number of tasks, including action classification and video captioning. We show that it can be applied directly to open-vocabulary classification, and confirm that large amounts of training data and cross-modal information are critical to performance. Furthermore, we outperform the state-of-the-art on video captioning, and quantitative results verify that the model learns high-level semantic features.