 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCURVE: A Benchmark for Cultural and Multilingual Long Video Reasoning
Jan 15, 2026Recent advancements in video models have shown tremendous progress, particularly in long video understanding. However, current benchmarks predominantly feature western-centric data and English as the dominant language, introducing significant biases in evaluation. To address this, we introduce CURVE (Cultural Understanding and Reasoning in Video Evaluation), a challenging benchmark for multicultural and multilingual video reasoning. CURVE comprises high-quality, entirely human-generated annotations from diverse, region-specific cultural videos across 18 global locales. Unlike prior work that relies on automatic translations, CURVE provides complex questions, answers, and multi-step reasoning steps, all crafted in native languages. Making progress on CURVE requires a deeply situated understanding of visual cultural context. Furthermore, we leverage CURVE's reasoning traces to construct evidence-based graphs and propose a novel iterative strategy using these graphs to identify fine-grained errors in reasoning. Our evaluations reveal that SoTA Video-LLMs struggle significantly, performing substantially below human-level accuracy, with errors primarily stemming from the visual perception of cultural elements. CURVE will be publicly available under https://github.com/google-deepmind/neptune?tab=readme-ov-file\#minerva-cultural
CAViAR: Critic-Augmented Video Agentic Reasoning
Sep 09, 2025Video understanding has seen significant progress in recent years, with models' performance on perception from short clips continuing to rise. Yet, multiple recent benchmarks, such as LVBench, Neptune, and ActivityNet-RTL, show performance wanes for tasks requiring complex reasoning on videos as queries grow more complex and videos grow longer. In this work, we ask: can existing perception capabilities be leveraged to successfully perform more complex video reasoning? In particular, we develop a large language model agent given access to video modules as subagents or tools. Rather than following a fixed procedure to solve queries as in previous work such as Visual Programming, ViperGPT, and MoReVQA, the agent uses the results of each call to a module to determine subsequent steps. Inspired by work in the textual reasoning domain, we introduce a critic to distinguish between instances of successful and unsuccessful sequences from the agent. We show that the combination of our agent and critic achieve strong performance on the previously-mentioned datasets.
VoCap: Video Object Captioning and Segmentation from Any Prompt
Aug 29, 2025Understanding objects in videos in terms of fine-grained localization masks and detailed semantic properties is a fundamental task in video understanding. In this paper, we propose VoCap, a flexible video model that consumes a video and a prompt of various modalities (text, box or mask), and produces a spatio-temporal masklet with a corresponding object-centric caption. As such our model addresses simultaneously the tasks of promptable video object segmentation, referring expression segmentation, and object captioning. Since obtaining data for this task is tedious and expensive, we propose to annotate an existing large-scale segmentation dataset (SAV) with pseudo object captions. We do so by preprocessing videos with their ground-truth masks to highlight the object of interest and feed this to a large Vision Language Model (VLM). For an unbiased evaluation, we collect manual annotations on the validation set. We call the resulting dataset SAV-Caption. We train our VoCap model at scale on a SAV-Caption together with a mix of other image and video datasets. Our model yields state-of-the-art results on referring expression video object segmentation, is competitive on semi-supervised video object segmentation, and establishes a benchmark for video object captioning. Our dataset will be made available at https://github.com/google-deepmind/vocap.
MINERVA: Evaluating Complex Video Reasoning
May 01, 2025Multimodal LLMs are turning their focus to video benchmarks, however most video benchmarks only provide outcome supervision, with no intermediate or interpretable reasoning steps. This makes it challenging to assess if models are truly able to combine perceptual and temporal information to reason about videos, or simply get the correct answer by chance or by exploiting linguistic biases. To remedy this, we provide a new video reasoning dataset called MINERVA for modern multimodal models. Each question in the dataset comes with 5 answer choices, as well as detailed, hand-crafted reasoning traces. Our dataset is multimodal, diverse in terms of video domain and length, and consists of complex multi-step questions. Extensive benchmarking shows that our dataset provides a challenge for frontier open-source and proprietary models. We perform fine-grained error analysis to identify common failure modes across various models, and create a taxonomy of reasoning errors. We use this to explore both human and LLM-as-a-judge methods for scoring video reasoning traces, and find that failure modes are primarily related to temporal localization, followed by visual perception errors, as opposed to logical or completeness errors. The dataset, along with questions, answer candidates and reasoning traces will be publicly available under https://github.com/google-deepmind/neptune?tab=readme-ov-file\#minerva.
Shot-by-Shot: Film-Grammar-Aware Training-Free Audio Description Generation
Apr 01, 2025Our objective is the automatic generation of Audio Descriptions (ADs) for edited video material, such as movies and TV series. To achieve this, we propose a two-stage framework that leverages "shots" as the fundamental units of video understanding. This includes extending temporal context to neighbouring shots and incorporating film grammar devices, such as shot scales and thread structures, to guide AD generation. Our method is compatible with both open-source and proprietary Visual-Language Models (VLMs), integrating expert knowledge from add-on modules without requiring additional training of the VLMs. We achieve state-of-the-art performance among all prior training-free approaches and even surpass fine-tuned methods on several benchmarks. To evaluate the quality of predicted ADs, we introduce a new evaluation measure -- an action score -- specifically targeted to assessing this important aspect of AD. Additionally, we propose a novel evaluation protocol that treats automatic frameworks as AD generation assistants and asks them to generate multiple candidate ADs for selection.
Unbiasing through Textual Descriptions: Mitigating Representation Bias in Video Benchmarks
Mar 24, 2025We propose a new "Unbiased through Textual Description (UTD)" video benchmark based on unbiased subsets of existing video classification and retrieval datasets to enable a more robust assessment of video understanding capabilities. Namely, we tackle the problem that current video benchmarks may suffer from different representation biases, e.g., object bias or single-frame bias, where mere recognition of objects or utilization of only a single frame is sufficient for correct prediction. We leverage VLMs and LLMs to analyze and debias benchmarks from such representation biases. Specifically, we generate frame-wise textual descriptions of videos, filter them for specific information (e.g. only objects) and leverage them to examine representation biases across three dimensions: 1) concept bias - determining if a specific concept (e.g., objects) alone suffice for prediction; 2) temporal bias - assessing if temporal information contributes to prediction; and 3) common sense vs. dataset bias - evaluating whether zero-shot reasoning or dataset correlations contribute to prediction. We conduct a systematic analysis of 12 popular video classification and retrieval datasets and create new object-debiased test splits for these datasets. Moreover, we benchmark 30 state-of-the-art video models on original and debiased splits and analyze biases in the models. To facilitate the future development of more robust video understanding benchmarks and models, we release: "UTD-descriptions", a dataset with our rich structured descriptions for each dataset, and "UTD-splits", a dataset of object-debiased test splits.
Neptune: The Long Orbit to Benchmarking Long Video Understanding
Dec 12, 2024



This paper describes a semi-automatic pipeline to generate challenging question-answer-decoy sets for understanding long videos. Many existing video datasets and models are focused on short clips (10s-30s). While some long video datasets do exist, they can often be solved by powerful image models applied per frame (and often to very few frames) in a video, and are usually manually annotated at high cost. In order to mitigate both these problems, we propose a scalable dataset creation pipeline which leverages large models (VLMs and LLMs), to automatically generate dense, time-aligned video captions, as well as tough question answer decoy sets for video segments (up to 15 minutes in length). Our dataset Neptune covers a broad range of long video reasoning abilities and consists of a subset that emphasizes multimodal reasoning. Since existing metrics for open-ended question answering are either rule-based or may rely on proprietary models, we provide a new open source model-based metric GEM to score open-ended responses on Neptune. Benchmark evaluations reveal that most current open-source long video models perform poorly on Neptune, particularly on questions testing temporal ordering, counting and state changes. Through Neptune, we aim to spur the development of more advanced models capable of understanding long videos. The dataset is available at https://github.com/google-deepmind/neptune
The VoxCeleb Speaker Recognition Challenge: A Retrospective
Aug 27, 2024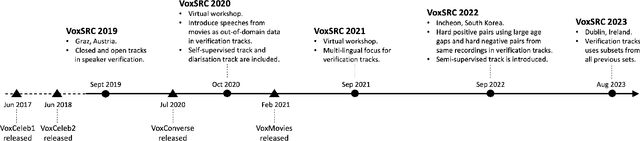
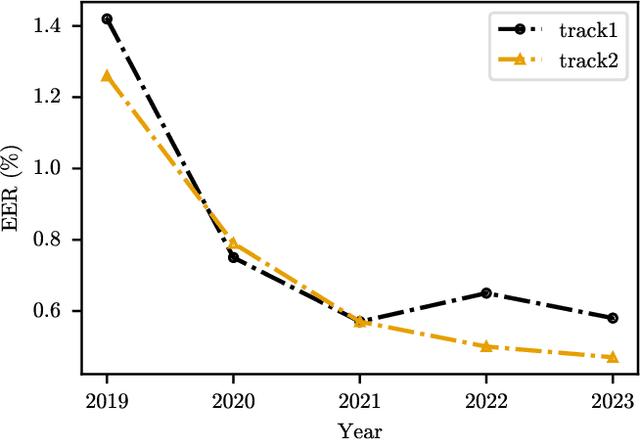
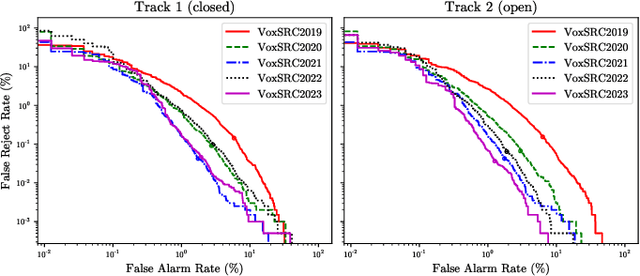
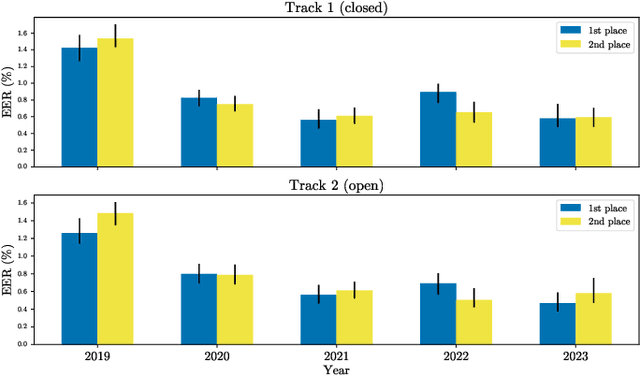
The VoxCeleb Speaker Recognition Challenges (VoxSRC) were a series of challenges and workshops that ran annually from 2019 to 2023. The challenges primarily evaluated the tasks of speaker recognition and diarisation under various settings including: closed and open training data; as well as supervised, self-supervised, and semi-supervised training for domain adaptation. The challenges also provided publicly available training and evaluation datasets for each task and setting, with new test sets released each year. In this paper, we provide a review of these challenges that covers: what they explored; the methods developed by the challenge participants and how these evolved; and also the current state of the field for speaker verification and diarisation. We chart the progress in performance over the five installments of the challenge on a common evaluation dataset and provide a detailed analysis of how each year's special focus affected participants' performance. This paper is aimed both at researchers who want an overview of the speaker recognition and diarisation field, and also at challenge organisers who want to benefit from the successes and avoid the mistakes of the VoxSRC challenges. We end with a discussion of the current strengths of the field and open challenges. Project page : https://mm.kaist.ac.kr/datasets/voxceleb/voxsrc/workshop.html
Mixture of Nested Experts: Adaptive Processing of Visual Tokens
Jul 29, 2024

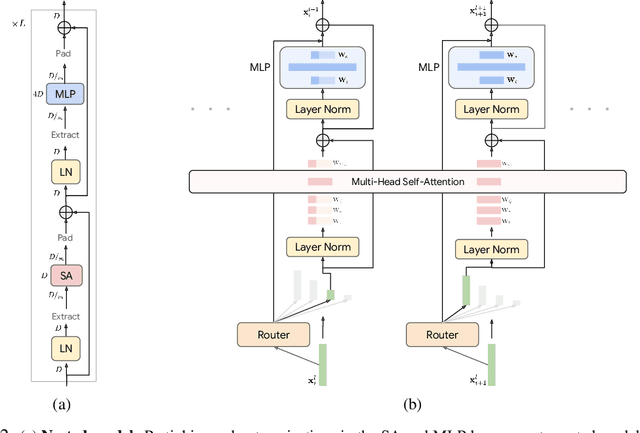
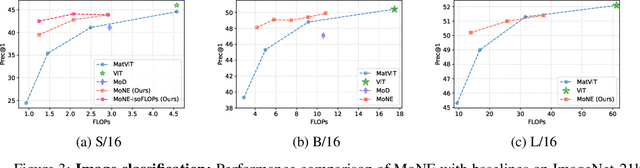
The visual medium (images and videos) naturally contains a large amount of information redundancy, thereby providing a great opportunity for leveraging efficiency in processing. While Vision Transformer (ViT) based models scale effectively to large data regimes, they fail to capitalize on this inherent redundancy, leading to higher computational costs. Mixture of Experts (MoE) networks demonstrate scalability while maintaining same inference-time costs, but they come with a larger parameter footprint. We present Mixture of Nested Experts (MoNE), which utilizes a nested structure for experts, wherein individual experts fall on an increasing compute-accuracy curve. Given a compute budget, MoNE learns to dynamically choose tokens in a priority order, and thus redundant tokens are processed through cheaper nested experts. Using this framework, we achieve equivalent performance as the baseline models, while reducing inference time compute by over two-fold. We validate our approach on standard image and video datasets - ImageNet-21K, Kinetics400, and Something-Something-v2. We further highlight MoNE$'$s adaptability by showcasing its ability to maintain strong performance across different inference-time compute budgets on videos, using only a single trained model.
AutoAD-Zero: A Training-Free Framework for Zero-Shot Audio Description
Jul 22, 2024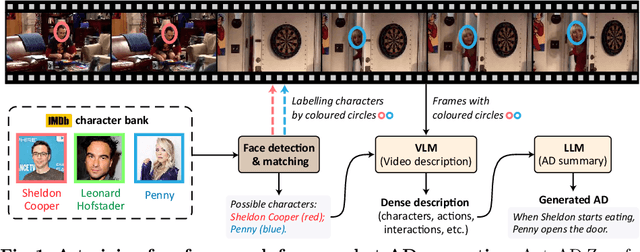

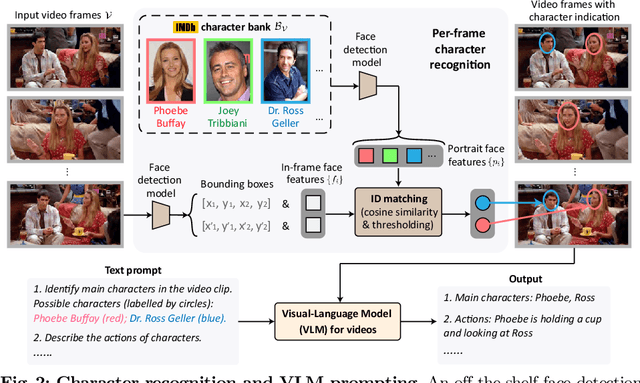

Our objective is to generate Audio Descriptions (ADs) for both movies and TV series in a training-free manner. We use the power of off-the-shelf Visual-Language Models (VLMs) and Large Language Models (LLMs), and develop visual and text prompting strategies for this task. Our contributions are three-fold: (i) We demonstrate that a VLM can successfully name and refer to characters if directly prompted with character information through visual indications without requiring any fine-tuning; (ii) A two-stage process is developed to generate ADs, with the first stage asking the VLM to comprehensively describe the video, followed by a second stage utilising a LLM to summarise dense textual information into one succinct AD sentence; (iii) A new dataset for TV audio description is formulated. Our approach, named AutoAD-Zero, demonstrates outstanding performance (even competitive with some models fine-tuned on ground truth ADs) in AD generation for both movies and TV series, achieving state-of-the-art CRITIC scores.