 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSegment, Embed, and Align: A Universal Recipe for Aligning Subtitles to Signing
Dec 08, 2025The goal of this work is to develop a universal approach for aligning subtitles (i.e., spoken language text with corresponding timestamps) to continuous sign language videos. Prior approaches typically rely on end-to-end training tied to a specific language or dataset, which limits their generality. In contrast, our method Segment, Embed, and Align (SEA) provides a single framework that works across multiple languages and domains. SEA leverages two pretrained models: the first to segment a video frame sequence into individual signs and the second to embed the video clip of each sign into a shared latent space with text. Alignment is subsequently performed with a lightweight dynamic programming procedure that runs efficiently on CPUs within a minute, even for hour-long episodes. SEA is flexible and can adapt to a wide range of scenarios, utilizing resources from small lexicons to large continuous corpora. Experiments on four sign language datasets demonstrate state-of-the-art alignment performance, highlighting the potential of SEA to generate high-quality parallel data for advancing sign language processing. SEA's code and models are openly available.
Lost in Translation, Found in Embeddings: Sign Language Translation and Alignment
Dec 08, 2025

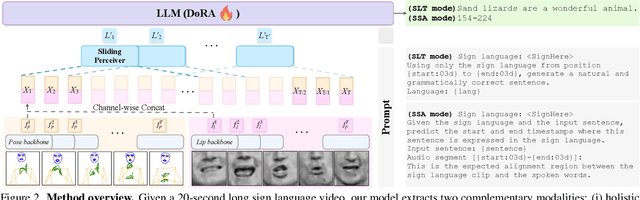
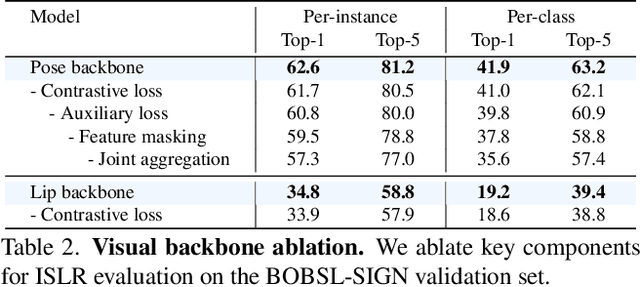
Our aim is to develop a unified model for sign language understanding, that performs sign language translation (SLT) and sign-subtitle alignment (SSA). Together, these two tasks enable the conversion of continuous signing videos into spoken language text and also the temporal alignment of signing with subtitles -- both essential for practical communication, large-scale corpus construction, and educational applications. To achieve this, our approach is built upon three components: (i) a lightweight visual backbone that captures manual and non-manual cues from human keypoints and lip-region images while preserving signer privacy; (ii) a Sliding Perceiver mapping network that aggregates consecutive visual features into word-level embeddings to bridge the vision-text gap; and (iii) a multi-task scalable training strategy that jointly optimises SLT and SSA, reinforcing both linguistic and temporal alignment. To promote cross-linguistic generalisation, we pretrain our model on large-scale sign-text corpora covering British Sign Language (BSL) and American Sign Language (ASL) from the BOBSL and YouTube-SL-25 datasets. With this multilingual pretraining and strong model design, we achieve state-of-the-art results on the challenging BOBSL (BSL) dataset for both SLT and SSA. Our model also demonstrates robust zero-shot generalisation and finetuned SLT performance on How2Sign (ASL), highlighting the potential of scalable translation across different sign languages.
Dense Motion Captioning
Nov 07, 2025Recent advances in 3D human motion and language integration have primarily focused on text-to-motion generation, leaving the task of motion understanding relatively unexplored. We introduce Dense Motion Captioning, a novel task that aims to temporally localize and caption actions within 3D human motion sequences. Current datasets fall short in providing detailed temporal annotations and predominantly consist of short sequences featuring few actions. To overcome these limitations, we present the Complex Motion Dataset (CompMo), the first large-scale dataset featuring richly annotated, complex motion sequences with precise temporal boundaries. Built through a carefully designed data generation pipeline, CompMo includes 60,000 motion sequences, each composed of multiple actions ranging from at least two to ten, accurately annotated with their temporal extents. We further present DEMO, a model that integrates a large language model with a simple motion adapter, trained to generate dense, temporally grounded captions. Our experiments show that DEMO substantially outperforms existing methods on CompMo as well as on adapted benchmarks, establishing a robust baseline for future research in 3D motion understanding and captioning.
Shot-by-Shot: Film-Grammar-Aware Training-Free Audio Description Generation
Apr 01, 2025Our objective is the automatic generation of Audio Descriptions (ADs) for edited video material, such as movies and TV series. To achieve this, we propose a two-stage framework that leverages "shots" as the fundamental units of video understanding. This includes extending temporal context to neighbouring shots and incorporating film grammar devices, such as shot scales and thread structures, to guide AD generation. Our method is compatible with both open-source and proprietary Visual-Language Models (VLMs), integrating expert knowledge from add-on modules without requiring additional training of the VLMs. We achieve state-of-the-art performance among all prior training-free approaches and even surpass fine-tuned methods on several benchmarks. To evaluate the quality of predicted ADs, we introduce a new evaluation measure -- an action score -- specifically targeted to assessing this important aspect of AD. Additionally, we propose a novel evaluation protocol that treats automatic frameworks as AD generation assistants and asks them to generate multiple candidate ADs for selection.
Chapter-Llama: Efficient Chaptering in Hour-Long Videos with LLMs
Mar 31, 2025We address the task of video chaptering, i.e., partitioning a long video timeline into semantic units and generating corresponding chapter titles. While relatively underexplored, automatic chaptering has the potential to enable efficient navigation and content retrieval in long-form videos. In this paper, we achieve strong chaptering performance on hour-long videos by efficiently addressing the problem in the text domain with our 'Chapter-Llama' framework. Specifically, we leverage a pretrained large language model (LLM) with large context window, and feed as input (i) speech transcripts and (ii) captions describing video frames, along with their respective timestamps. Given the inefficiency of exhaustively captioning all frames, we propose a lightweight speech-guided frame selection strategy based on speech transcript content, and experimentally demonstrate remarkable advantages. We train the LLM to output timestamps for the chapter boundaries, as well as free-form chapter titles. This simple yet powerful approach scales to processing one-hour long videos in a single forward pass. Our results demonstrate substantial improvements (e.g., 45.3 vs 26.7 F1 score) over the state of the art on the recent VidChapters-7M benchmark. To promote further research, we release our code and models at our project page.
Lost in Translation, Found in Context: Sign Language Translation with Contextual Cues
Jan 16, 2025



Our objective is to translate continuous sign language into spoken language text. Inspired by the way human interpreters rely on context for accurate translation, we incorporate additional contextual cues together with the signing video, into a new translation framework. Specifically, besides visual sign recognition features that encode the input video, we integrate complementary textual information from (i) captions describing the background show, (ii) translation of previous sentences, as well as (iii) pseudo-glosses transcribing the signing. These are automatically extracted and inputted along with the visual features to a pre-trained large language model (LLM), which we fine-tune to generate spoken language translations in text form. Through extensive ablation studies, we show the positive contribution of each input cue to the translation performance. We train and evaluate our approach on BOBSL -- the largest British Sign Language dataset currently available. We show that our contextual approach significantly enhances the quality of the translations compared to previously reported results on BOBSL, and also to state-of-the-art methods that we implement as baselines. Furthermore, we demonstrate the generality of our approach by applying it also to How2Sign, an American Sign Language dataset, and achieve competitive results.
MotionFix: Text-Driven 3D Human Motion Editing
Aug 01, 2024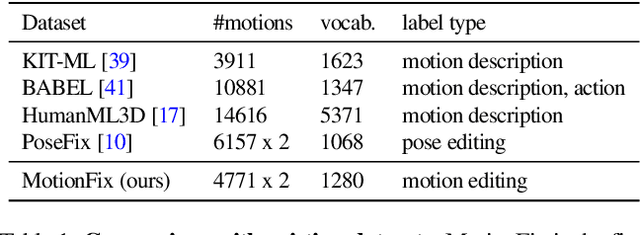

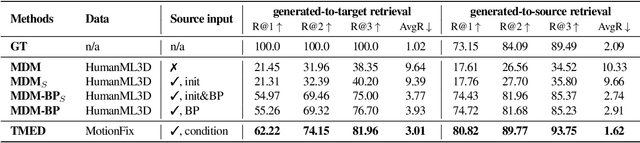
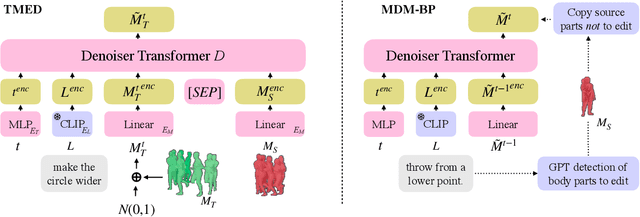
The focus of this paper is 3D motion editing. Given a 3D human motion and a textual description of the desired modification, our goal is to generate an edited motion as described by the text. The challenges include the lack of training data and the design of a model that faithfully edits the source motion. In this paper, we address both these challenges. We build a methodology to semi-automatically collect a dataset of triplets in the form of (i) a source motion, (ii) a target motion, and (iii) an edit text, and create the new MotionFix dataset. Having access to such data allows us to train a conditional diffusion model, TMED, that takes both the source motion and the edit text as input. We further build various baselines trained only on text-motion pairs datasets, and show superior performance of our model trained on triplets. We introduce new retrieval-based metrics for motion editing and establish a new benchmark on the evaluation set of MotionFix. Our results are encouraging, paving the way for further research on finegrained motion generation. Code and models will be made publicly available.
AutoAD-Zero: A Training-Free Framework for Zero-Shot Audio Description
Jul 22, 2024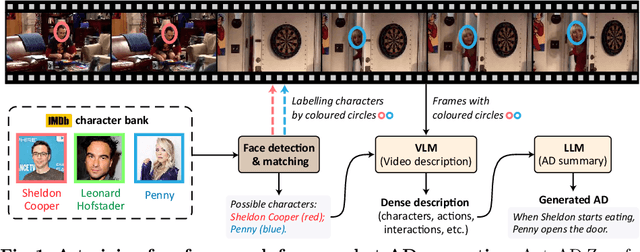

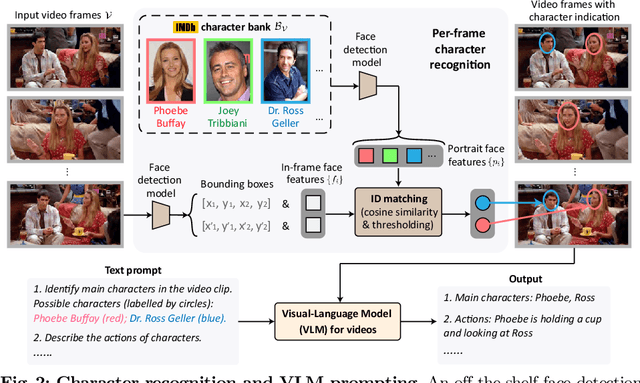

Our objective is to generate Audio Descriptions (ADs) for both movies and TV series in a training-free manner. We use the power of off-the-shelf Visual-Language Models (VLMs) and Large Language Models (LLMs), and develop visual and text prompting strategies for this task. Our contributions are three-fold: (i) We demonstrate that a VLM can successfully name and refer to characters if directly prompted with character information through visual indications without requiring any fine-tuning; (ii) A two-stage process is developed to generate ADs, with the first stage asking the VLM to comprehensively describe the video, followed by a second stage utilising a LLM to summarise dense textual information into one succinct AD sentence; (iii) A new dataset for TV audio description is formulated. Our approach, named AutoAD-Zero, demonstrates outstanding performance (even competitive with some models fine-tuned on ground truth ADs) in AD generation for both movies and TV series, achieving state-of-the-art CRITIC scores.
A Cross-Dataset Study for Text-based 3D Human Motion Retrieval
May 27, 2024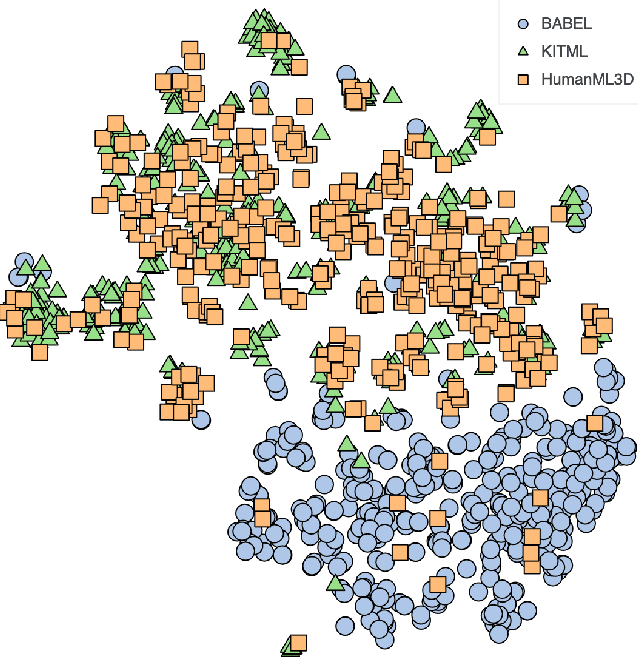

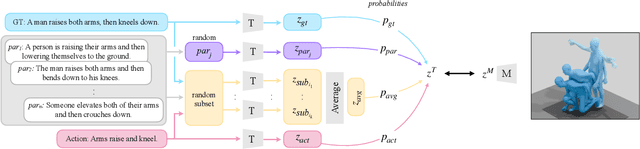

We provide results of our study on text-based 3D human motion retrieval and particularly focus on cross-dataset generalization. Due to practical reasons such as dataset-specific human body representations, existing works typically benchmarkby training and testing on partitions from the same dataset. Here, we employ a unified SMPL body format for all datasets, which allows us to perform training on one dataset, testing on the other, as well as training on a combination of datasets. Our results suggest that there exist dataset biases in standard text-motion benchmarks such as HumanML3D, KIT Motion-Language, and BABEL. We show that text augmentations help close the domain gap to some extent, but the gap remains. We further provide the first zero-shot action recognition results on BABEL, without using categorical action labels during training, opening up a new avenue for future research.
A Tale of Two Languages: Large-Vocabulary Continuous Sign Language Recognition from Spoken Language Supervision
May 16, 2024
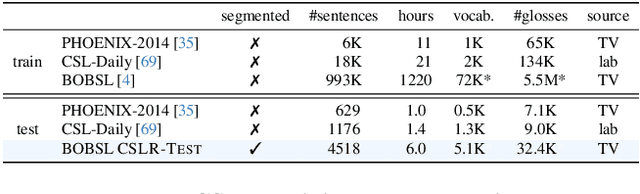
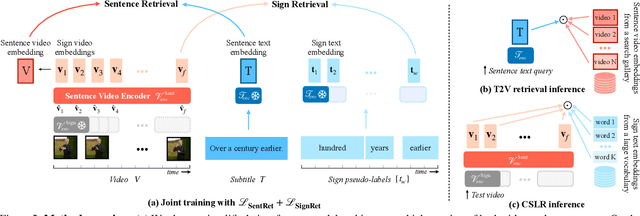

In this work, our goals are two fold: large-vocabulary continuous sign language recognition (CSLR), and sign language retrieval. To this end, we introduce a multi-task Transformer model, CSLR2, that is able to ingest a signing sequence and output in a joint embedding space between signed language and spoken language text. To enable CSLR evaluation in the large-vocabulary setting, we introduce new dataset annotations that have been manually collected. These provide continuous sign-level annotations for six hours of test videos, and will be made publicly available. We demonstrate that by a careful choice of loss functions, training the model for both the CSLR and retrieval tasks is mutually beneficial in terms of performance -- retrieval improves CSLR performance by providing context, while CSLR improves retrieval with more fine-grained supervision. We further show the benefits of leveraging weak and noisy supervision from large-vocabulary datasets such as BOBSL, namely sign-level pseudo-labels, and English subtitles. Our model significantly outperforms the previous state of the art on both tasks.