 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMotionBricks: Scalable Real-Time Motions with Modular Latent Generative Model and Smart Primitives
Apr 27, 2026Despite transformative advances in generative motion synthesis, real-time interactive motion control remains dominated by traditional techniques. In this work, we identify two key challenges in bridging research and production: 1) Real-time scalability: Industry applications demand real-time generation of a vast repertoire of motion skills, while generative methods exhibit significant degradation in quality and scalability under real-time computation constraints, and 2) Integration: Industry applications demand fine-grained multi-modal control involving velocity commands, style selection, and precise keyframes, a need largely unmet by existing text- or tag-driven models. To overcome these limitations, we introduce MotionBricks: a large-scale, real-time generative framework with a two-fold solution. First, we propose a large-scale modular latent generative backbone tailored for robust real-time motion generation, effectively modeling a dataset of over 350,000 motion clips with a single model. Second, we introduce smart primitives that provide a unified, robust, and intuitive interface for authoring both navigation and object interaction. Applications can be designed in a plug-and-play manner like assembling bricks without expert animation knowledge. Quantitatively, we show that MotionBricks produces state-of-the-art motion quality on open-source and proprietary datasets of various scales, while also achieving a real-time throughput of 15,000 FPS with 2ms latency. We demonstrate the flexibility and robustness of MotionBricks in a complete production-level animation demo, covering navigation and object-scene interaction across various styles with a unified model. To showcase our framework's application beyond animation, we deploy MotionBricks on the Unitree G1 humanoid robot to demonstrate its flexibility and generalization for real-time robotic control.
Kimodo: Scaling Controllable Human Motion Generation
Mar 16, 2026High-quality human motion data is becoming increasingly important for applications in robotics, simulation, and entertainment. Recent generative models offer a potential data source, enabling human motion synthesis through intuitive inputs like text prompts or kinematic constraints on poses. However, the small scale of public mocap datasets has limited the motion quality, control accuracy, and generalization of these models. In this work, we introduce Kimodo, an expressive and controllable kinematic motion diffusion model trained on 700 hours of optical motion capture data. Our model generates high-quality motions while being easily controlled through text and a comprehensive suite of kinematic constraints including full-body keyframes, sparse joint positions/rotations, 2D waypoints, and dense 2D paths. This is enabled through a carefully designed motion representation and two-stage denoiser architecture that decomposes root and body prediction to minimize motion artifacts while allowing for flexible constraint conditioning. Experiments on the large-scale mocap dataset justify key design decisions and analyze how the scaling of dataset size and model size affect performance.
A Cross-Dataset Study for Text-based 3D Human Motion Retrieval
May 27, 2024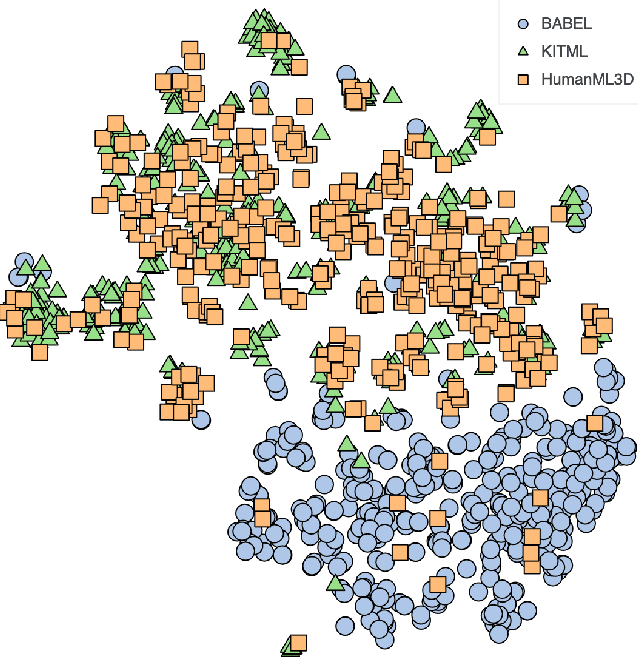


We provide results of our study on text-based 3D human motion retrieval and particularly focus on cross-dataset generalization. Due to practical reasons such as dataset-specific human body representations, existing works typically benchmarkby training and testing on partitions from the same dataset. Here, we employ a unified SMPL body format for all datasets, which allows us to perform training on one dataset, testing on the other, as well as training on a combination of datasets. Our results suggest that there exist dataset biases in standard text-motion benchmarks such as HumanML3D, KIT Motion-Language, and BABEL. We show that text augmentations help close the domain gap to some extent, but the gap remains. We further provide the first zero-shot action recognition results on BABEL, without using categorical action labels during training, opening up a new avenue for future research.
Multi-Track Timeline Control for Text-Driven 3D Human Motion Generation
Jan 16, 2024



Recent advances in generative modeling have led to promising progress on synthesizing 3D human motion from text, with methods that can generate character animations from short prompts and specified durations. However, using a single text prompt as input lacks the fine-grained control needed by animators, such as composing multiple actions and defining precise durations for parts of the motion. To address this, we introduce the new problem of timeline control for text-driven motion synthesis, which provides an intuitive, yet fine-grained, input interface for users. Instead of a single prompt, users can specify a multi-track timeline of multiple prompts organized in temporal intervals that may overlap. This enables specifying the exact timings of each action and composing multiple actions in sequence or at overlapping intervals. To generate composite animations from a multi-track timeline, we propose a new test-time denoising method. This method can be integrated with any pre-trained motion diffusion model to synthesize realistic motions that accurately reflect the timeline. At every step of denoising, our method processes each timeline interval (text prompt) individually, subsequently aggregating the predictions with consideration for the specific body parts engaged in each action. Experimental comparisons and ablations validate that our method produces realistic motions that respect the semantics and timing of given text prompts. Our code and models are publicly available at https://mathis.petrovich.fr/stmc.
TMR: Text-to-Motion Retrieval Using Contrastive 3D Human Motion Synthesis
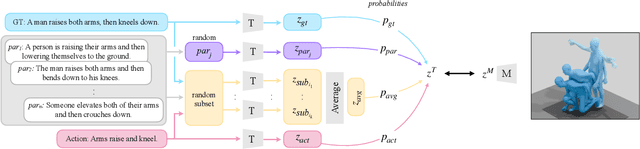
May 02, 2023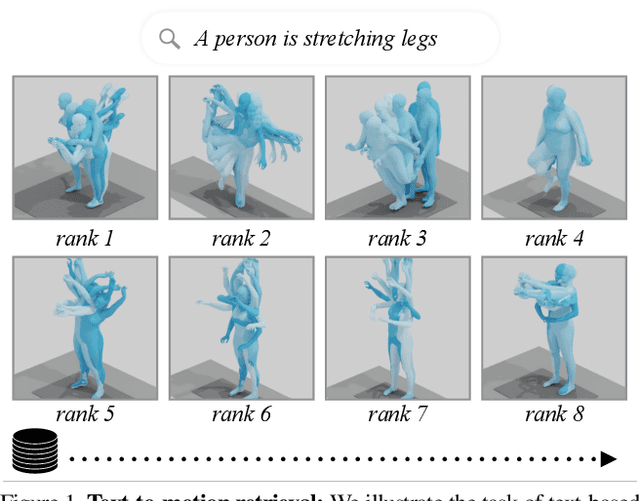
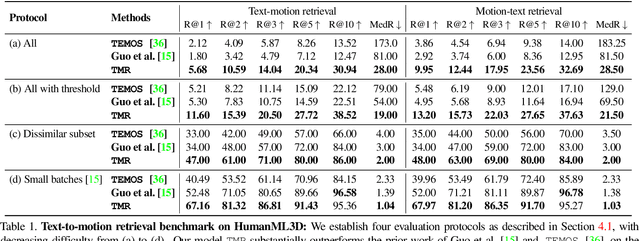
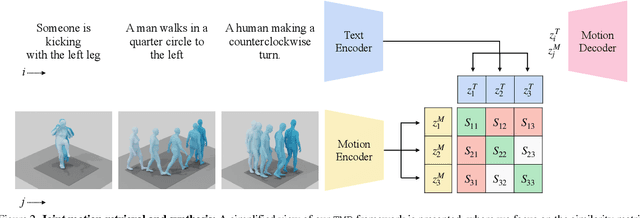
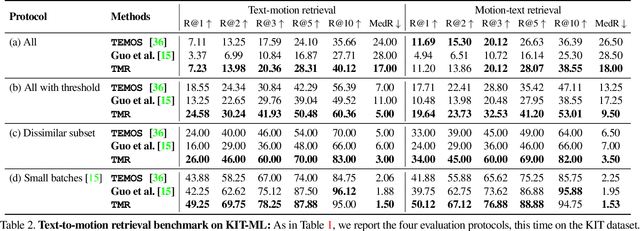
In this paper, we present TMR, a simple yet effective approach for text to 3D human motion retrieval. While previous work has only treated retrieval as a proxy evaluation metric, we tackle it as a standalone task. Our method extends the state-of-the-art text-to-motion synthesis model TEMOS, and incorporates a contrastive loss to better structure the cross-modal latent space. We show that maintaining the motion generation loss, along with the contrastive training, is crucial to obtain good performance. We introduce a benchmark for evaluation and provide an in-depth analysis by reporting results on several protocols. Our extensive experiments on the KIT-ML and HumanML3D datasets show that TMR outperforms the prior work by a significant margin, for example reducing the median rank from 54 to 19. Finally, we showcase the potential of our approach on moment retrieval. Our code and models are publicly available.
SINC: Spatial Composition of 3D Human Motions for Simultaneous Action Generation
Apr 20, 2023



Our goal is to synthesize 3D human motions given textual inputs describing simultaneous actions, for example 'waving hand' while 'walking' at the same time. We refer to generating such simultaneous movements as performing 'spatial compositions'. In contrast to temporal compositions that seek to transition from one action to another, spatial compositing requires understanding which body parts are involved in which action, to be able to move them simultaneously. Motivated by the observation that the correspondence between actions and body parts is encoded in powerful language models, we extract this knowledge by prompting GPT-3 with text such as "what are the body parts involved in the action <action name>?", while also providing the parts list and few-shot examples. Given this action-part mapping, we combine body parts from two motions together and establish the first automated method to spatially compose two actions. However, training data with compositional actions is always limited by the combinatorics. Hence, we further create synthetic data with this approach, and use it to train a new state-of-the-art text-to-motion generation model, called SINC ("SImultaneous actioN Compositions for 3D human motions"). In our experiments, we find training on additional synthetic GPT-guided compositional motions improves text-to-motion generation.
TEACH: Temporal Action Composition for 3D Humans
Sep 12, 2022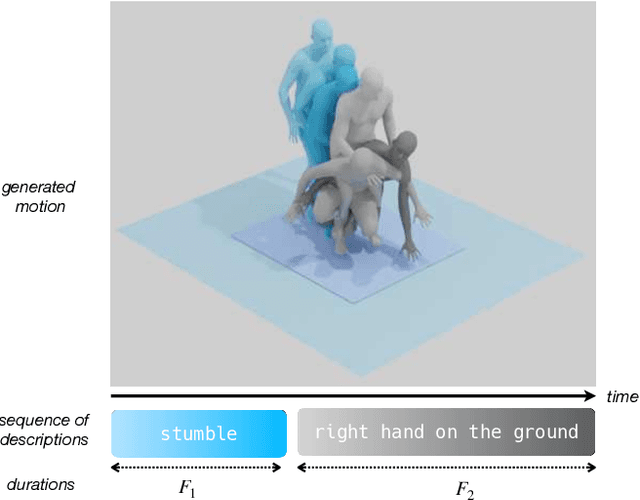

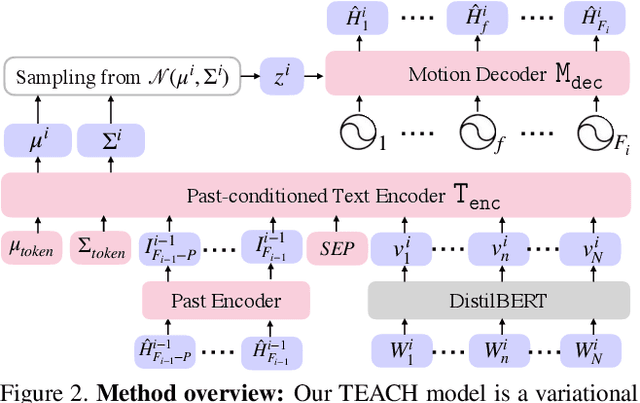

Given a series of natural language descriptions, our task is to generate 3D human motions that correspond semantically to the text, and follow the temporal order of the instructions. In particular, our goal is to enable the synthesis of a series of actions, which we refer to as temporal action composition. The current state of the art in text-conditioned motion synthesis only takes a single action or a single sentence as input. This is partially due to lack of suitable training data containing action sequences, but also due to the computational complexity of their non-autoregressive model formulation, which does not scale well to long sequences. In this work, we address both issues. First, we exploit the recent BABEL motion-text collection, which has a wide range of labeled actions, many of which occur in a sequence with transitions between them. Next, we design a Transformer-based approach that operates non-autoregressively within an action, but autoregressively within the sequence of actions. This hierarchical formulation proves effective in our experiments when compared with multiple baselines. Our approach, called TEACH for "TEmporal Action Compositions for Human motions", produces realistic human motions for a wide variety of actions and temporal compositions from language descriptions. To encourage work on this new task, we make our code available for research purposes at our $\href{teach.is.tue.mpg.de}{\text{website}}$.
TEMOS: Generating diverse human motions from textual descriptions
Apr 25, 2022
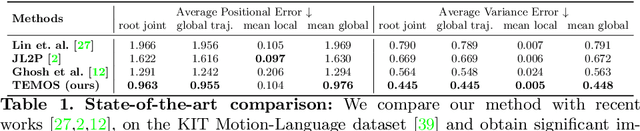

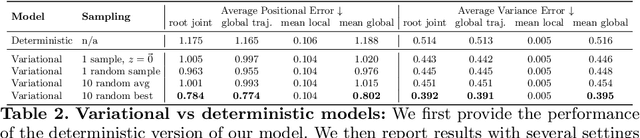
We address the problem of generating diverse 3D human motions from textual descriptions. This challenging task requires joint modeling of both modalities: understanding and extracting useful human-centric information from the text, and then generating plausible and realistic sequences of human poses. In contrast to most previous work which focuses on generating a single, deterministic, motion from a textual description, we design a variational approach that can produce multiple diverse human motions. We propose TEMOS, a text-conditioned generative model leveraging variational autoencoder (VAE) training with human motion data, in combination with a text encoder that produces distribution parameters compatible with the VAE latent space. We show that TEMOS framework can produce both skeleton-based animations as in prior work, as well more expressive SMPL body motions. We evaluate our approach on the KIT Motion-Language benchmark and, despite being relatively straightforward, demonstrate significant improvements over the state of the art. Code and models are available on our project page.
Action-Conditioned 3D Human Motion Synthesis with Transformer VAE
Apr 12, 2021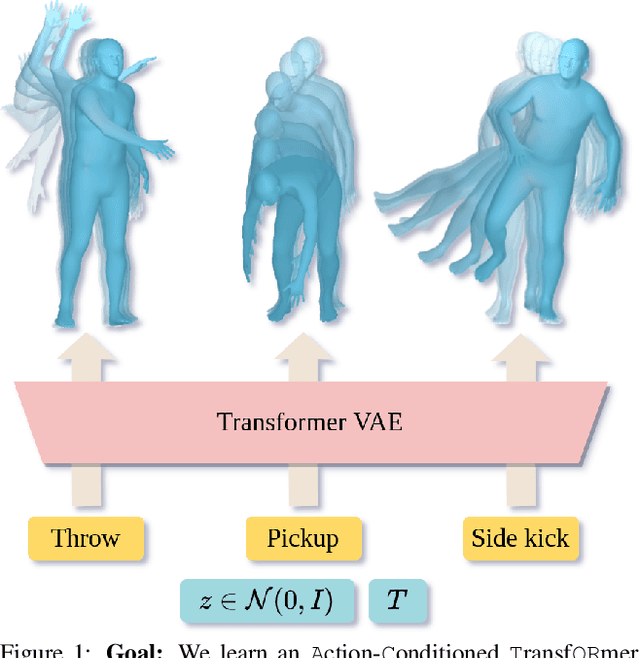

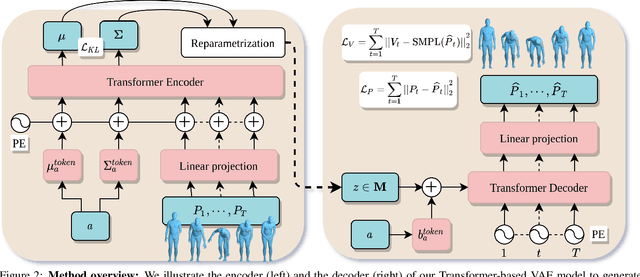

We tackle the problem of action-conditioned generation of realistic and diverse human motion sequences. In contrast to methods that complete, or extend, motion sequences, this task does not require an initial pose or sequence. Here we learn an action-aware latent representation for human motions by training a generative variational autoencoder (VAE). By sampling from this latent space and querying a certain duration through a series of positional encodings, we synthesize variable-length motion sequences conditioned on a categorical action. Specifically, we design a Transformer-based architecture, ACTOR, for encoding and decoding a sequence of parametric SMPL human body models estimated from action recognition datasets. We evaluate our approach on the NTU RGB+D, HumanAct12 and UESTC datasets and show improvements over the state of the art. Furthermore, we present two use cases: improving action recognition through adding our synthesized data to training, and motion denoising. Our code and models will be made available.
Feature Robust Optimal Transport for High-dimensional Data
Jun 16, 2020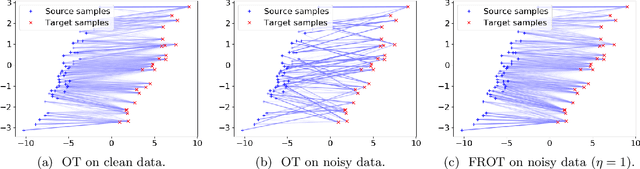

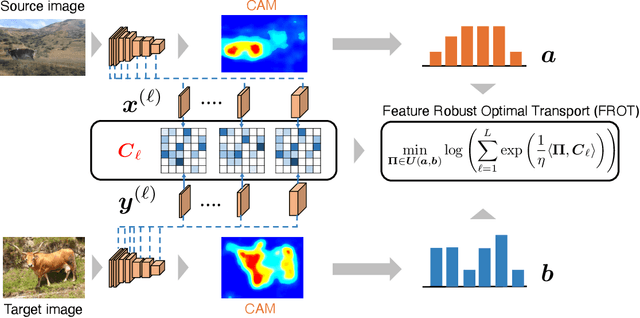
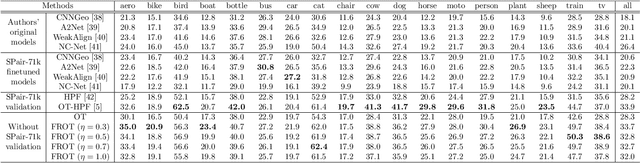
Optimal transport is a machine learning problem with applications including distribution comparison, feature selection, and generative adversarial networks. In this paper, we propose feature robust optimal transport (FROT) for high-dimensional data, which jointly solves feature selection and OT problems. Specifically, we formulate the FROT problem as a min--max optimization problem. Then, we propose a convex formulation of FROT and solve it with the Frank--Wolfe-based optimization algorithm, where the sub-problem can be efficiently solved using the Sinkhorn algorithm. A key advantage of FROT is that important features can be analytically determined by simply solving the convex optimization problem. Furthermore, we propose using the FROT algorithm for the layer selection problem in deep neural networks for semantic correspondence. By conducting synthetic and benchmark experiments, we demonstrate that the proposed method can determine important features. Additionally, we show that the FROT algorithm achieves a state-of-the-art performance in real-world semantic correspondence datasets.