 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIdeological Isolation in Online Social Networks: A Survey of Computational Definitions, Metrics, and Mitigation Strategies
Jan 12, 2026The proliferation of online social networks has significantly reshaped the way individuals access and engage with information. While these platforms offer unprecedented connectivity, they may foster environments where users are increasingly exposed to homogeneous content and like-minded interactions. Such dynamics are associated with selective exposure and the emergence of filter bubbles, echo chambers, tunnel vision, and polarization, which together can contribute to ideological isolation and raise concerns about information diversity and public discourse. This survey provides a comprehensive computational review of existing studies that define, analyze, quantify, and mitigate ideological isolation in online social networks. We examine the mechanisms underlying content personalization, user behavior patterns, and network structures that reinforce content-exposure concentration and narrowing dynamics. This paper also systematically reviews methodological approaches for detecting and measuring these isolation-related phenomena, covering network-, content-, and behavior-based metrics. We further organize computational mitigation strategies, including network-topological interventions and recommendation-level controls, and discuss their trade-offs and deployment considerations. By integrating definitions, metrics, and interventions across structural/topological, content-based, interactional, and cognitive isolation, this survey provides a unified computational framework. It serves as a reference for understanding and addressing the key challenges and opportunities in promoting information diversity and reducing ideological fragmentation in the digital age.
Towards Superior Quantization Accuracy: A Layer-sensitive Approach
Mar 09, 2025Large Vision and Language Models have exhibited remarkable human-like intelligence in tasks such as natural language comprehension, problem-solving, logical reasoning, and knowledge retrieval. However, training and serving these models require substantial computational resources, posing a significant barrier to their widespread application and further research. To mitigate this challenge, various model compression techniques have been developed to reduce computational requirements. Nevertheless, existing methods often employ uniform quantization configurations, failing to account for the varying difficulties across different layers in quantizing large neural network models. This paper tackles this issue by leveraging layer-sensitivity features, such as activation sensitivity and weight distribution Kurtosis, to identify layers that are challenging to quantize accurately and allocate additional memory budget. The proposed methods, named SensiBoost and KurtBoost, respectively, demonstrate notable improvement in quantization accuracy, achieving up to 9% lower perplexity with only a 2% increase in memory budget on LLama models compared to the baseline.
Trust-Aware Diversion for Data-Effective Distillation
Feb 07, 2025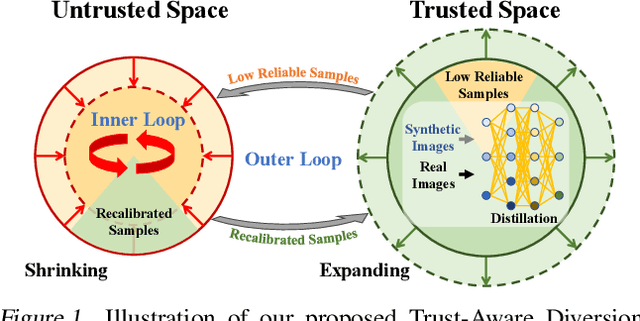
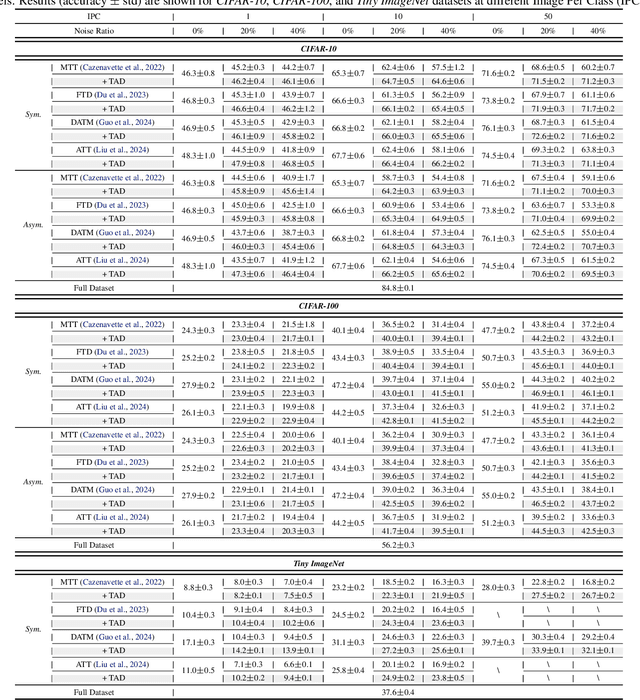
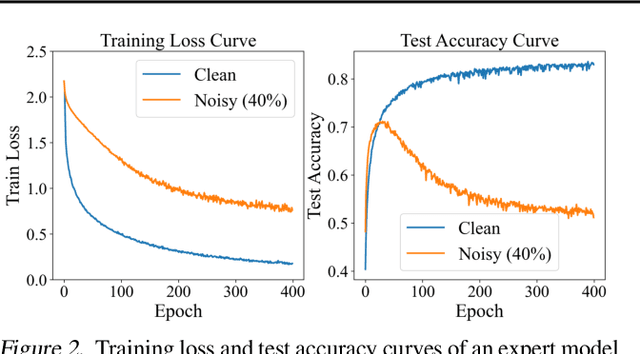
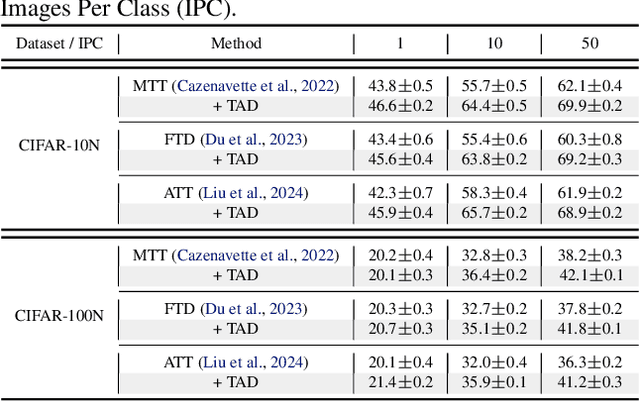
Dataset distillation compresses a large dataset into a small synthetic subset that retains essential information. Existing methods assume that all samples are perfectly labeled, limiting their real-world applications where incorrect labels are ubiquitous. These mislabeled samples introduce untrustworthy information into the dataset, which misleads model optimization in dataset distillation. To tackle this issue, we propose a Trust-Aware Diversion (TAD) dataset distillation method. Our proposed TAD introduces an iterative dual-loop optimization framework for data-effective distillation. Specifically, the outer loop divides data into trusted and untrusted spaces, redirecting distillation toward trusted samples to guarantee trust in the distillation process. This step minimizes the impact of mislabeled samples on dataset distillation. The inner loop maximizes the distillation objective by recalibrating untrusted samples, thus transforming them into valuable ones for distillation. This dual-loop iteratively refines and compensates for each other, gradually expanding the trusted space and shrinking the untrusted space. Experiments demonstrate that our method can significantly improve the performance of existing dataset distillation methods on three widely used benchmarks (CIFAR10, CIFAR100, and Tiny ImageNet) in three challenging mislabeled settings (symmetric, asymmetric, and real-world).
Multitask Deep Learning for Accurate Risk Stratification and Prediction of Next Steps for Coronary CT Angiography Patients
Sep 01, 2023Diagnostic investigation has an important role in risk stratification and clinical decision making of patients with suspected and documented Coronary Artery Disease (CAD). However, the majority of existing tools are primarily focused on the selection of gatekeeper tests, whereas only a handful of systems contain information regarding the downstream testing or treatment. We propose a multi-task deep learning model to support risk stratification and down-stream test selection for patients undergoing Coronary Computed Tomography Angiography (CCTA). The analysis included 14,021 patients who underwent CCTA between 2006 and 2017. Our novel multitask deep learning framework extends the state-of-the art Perceiver model to deal with real-world CCTA report data. Our model achieved an Area Under the receiver operating characteristic Curve (AUC) of 0.76 in CAD risk stratification, and 0.72 AUC in predicting downstream tests. Our proposed deep learning model can accurately estimate the likelihood of CAD and provide recommended downstream tests based on prior CCTA data. In clinical practice, the utilization of such an approach could bring a paradigm shift in risk stratification and downstream management. Despite significant progress using deep learning models for tabular data, they do not outperform gradient boosting decision trees, and further research is required in this area. However, neural networks appear to benefit more readily from multi-task learning than tree-based models. This could offset the shortcomings of using single task learning approach when working with tabular data.
PMaF: Deep Declarative Layers for Principal Matrix Features
Jul 01, 2023



We explore two differentiable deep declarative layers, namely least squares on sphere (LESS) and implicit eigen decomposition (IED), for learning the principal matrix features (PMaF). It can be used to represent data features with a low-dimensional vector containing dominant information from a high-dimensional matrix. We first solve the problems with iterative optimization in the forward pass and then backpropagate the solution for implicit gradients under a bi-level optimization framework. Particularly, adaptive descent steps with the backtracking line search method and descent decay in the tangent space are studied to improve the forward pass efficiency of LESS. Meanwhile, exploited data structures are used to greatly reduce the computational complexity in the backward pass of LESS and IED. Empirically, we demonstrate the superiority of our layers over the off-the-shelf baselines by comparing the solution optimality and computational requirements.
Towards Understanding Gradient Approximation in Equality Constrained Deep Declarative Networks
Jun 24, 2023



We explore conditions for when the gradient of a deep declarative node can be approximated by ignoring constraint terms and still result in a descent direction for the global loss function. This has important practical application when training deep learning models since the approximation is often computationally much more efficient than the true gradient calculation. We provide theoretical analysis for problems with linear equality constraints and normalization constraints, and show examples where the approximation works well in practice as well as some cautionary tales for when it fails.
Aligning Step-by-Step Instructional Diagrams to Video Demonstrations
Mar 27, 2023Multimodal alignment facilitates the retrieval of instances from one modality when queried using another. In this paper, we consider a novel setting where such an alignment is between (i) instruction steps that are depicted as assembly diagrams (commonly seen in Ikea assembly manuals) and (ii) video segments from in-the-wild videos; these videos comprising an enactment of the assembly actions in the real world. To learn this alignment, we introduce a novel supervised contrastive learning method that learns to align videos with the subtle details in the assembly diagrams, guided by a set of novel losses. To study this problem and demonstrate the effectiveness of our method, we introduce a novel dataset: IAW for Ikea assembly in the wild consisting of 183 hours of videos from diverse furniture assembly collections and nearly 8,300 illustrations from their associated instruction manuals and annotated for their ground truth alignments. We define two tasks on this dataset: First, nearest neighbor retrieval between video segments and illustrations, and, second, alignment of instruction steps and the segments for each video. Extensive experiments on IAW demonstrate superior performances of our approach against alternatives.
NeRFEditor: Differentiable Style Decomposition for Full 3D Scene Editing
Dec 08, 2022



We present NeRFEditor, an efficient learning framework for 3D scene editing, which takes a video captured over 360{\deg} as input and outputs a high-quality, identity-preserving stylized 3D scene. Our method supports diverse types of editing such as guided by reference images, text prompts, and user interactions. We achieve this by encouraging a pre-trained StyleGAN model and a NeRF model to learn from each other mutually. Specifically, we use a NeRF model to generate numerous image-angle pairs to train an adjustor, which can adjust the StyleGAN latent code to generate high-fidelity stylized images for any given angle. To extrapolate editing to GAN out-of-domain views, we devise another module that is trained in a self-supervised learning manner. This module maps novel-view images to the hidden space of StyleGAN that allows StyleGAN to generate stylized images on novel views. These two modules together produce guided images in 360{\deg}views to finetune a NeRF to make stylization effects, where a stable fine-tuning strategy is proposed to achieve this. Experiments show that NeRFEditor outperforms prior work on benchmark and real-world scenes with better editability, fidelity, and identity preservation.
3D Brain and Heart Volume Generative Models: A Survey
Oct 12, 2022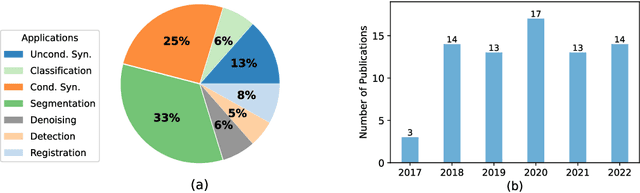
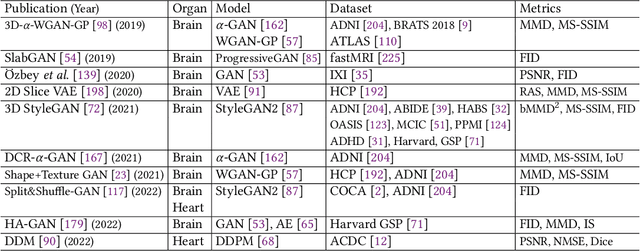
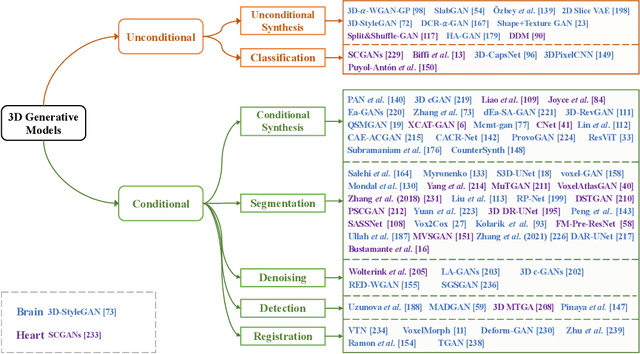

Generative models such as generative adversarial networks and autoencoders have gained a great deal of attention in the medical field due to their excellent data generation capability. This paper provides a comprehensive survey of generative models for three-dimensional (3D) volumes, focusing on the brain and heart. A new and elaborate taxonomy of unconditional and conditional generative models is proposed to cover diverse medical tasks for the brain and heart: unconditional synthesis, classification, conditional synthesis, segmentation, denoising, detection, and registration. We provide relevant background, examine each task and also suggest potential future directions. A list of the latest publications will be updated on Github to keep up with the rapid influx of papers at \url{https://github.com/csyanbin/3D-Medical-Generative-Survey}.
Inflating 2D Convolution Weights for Efficient Generation of 3D Medical Images
Aug 08, 2022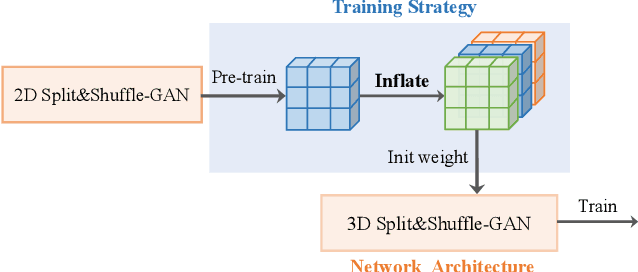
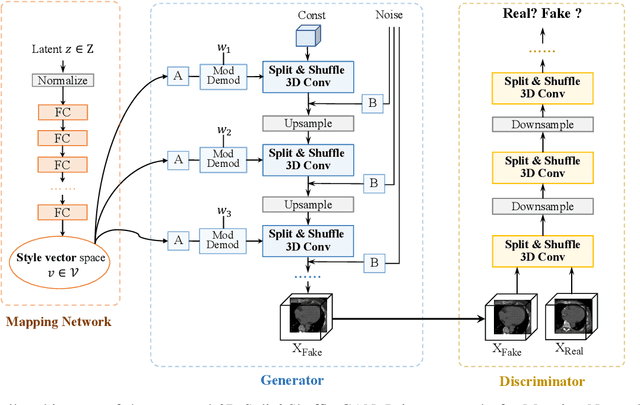
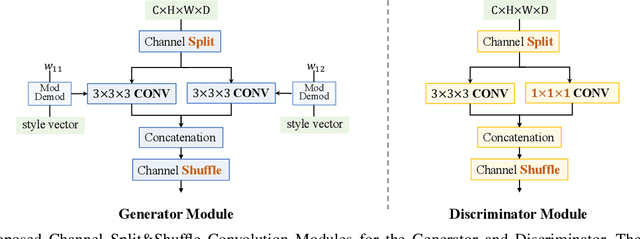
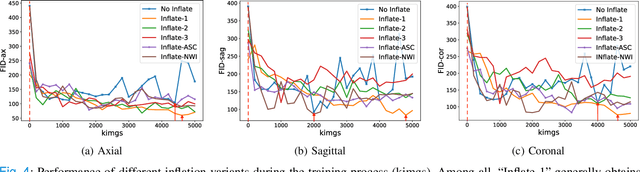
The generation of three-dimensional (3D) medical images can have great application potential since it takes into account the 3D anatomical structure. There are two problems, however, that prevent effective training of a 3D medical generative model: (1) 3D medical images are very expensive to acquire and annotate, resulting in an insufficient number of training images, (2) a large number of parameters are involved in 3D convolution. To address both problems, we propose a novel GAN model called 3D Split&Shuffle-GAN. In order to address the 3D data scarcity issue, we first pre-train a two-dimensional (2D) GAN model using abundant image slices and inflate the 2D convolution weights to improve initialization of the 3D GAN. Novel 3D network architectures are proposed for both the generator and discriminator of the GAN model to significantly reduce the number of parameters while maintaining the quality of image generation. A number of weight inflation strategies and parameter-efficient 3D architectures are investigated. Experiments on both heart (Stanford AIMI Coronary Calcium) and brain (Alzheimer's Disease Neuroimaging Initiative) datasets demonstrate that the proposed approach leads to improved 3D images generation quality with significantly fewer parameters.