 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTrust-Aware Diversion for Data-Effective Distillation
Paper and Code
Feb 07, 2025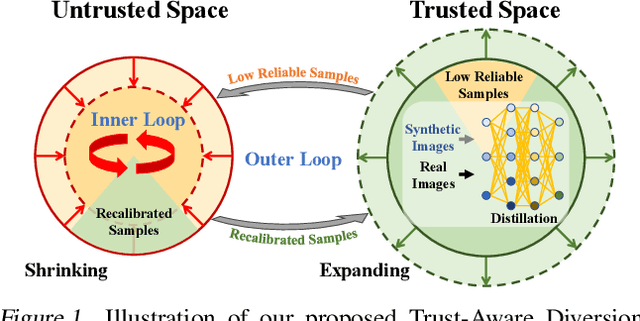
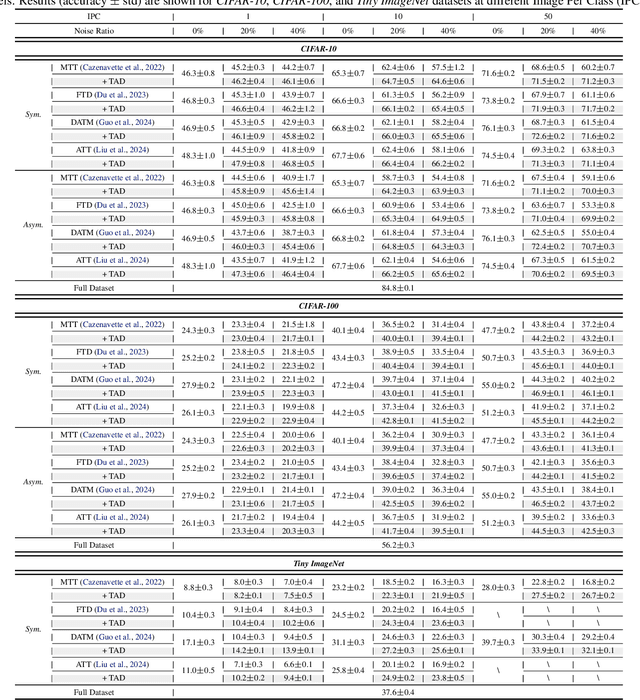
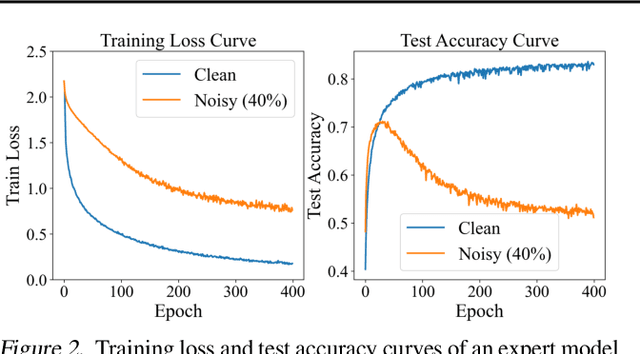
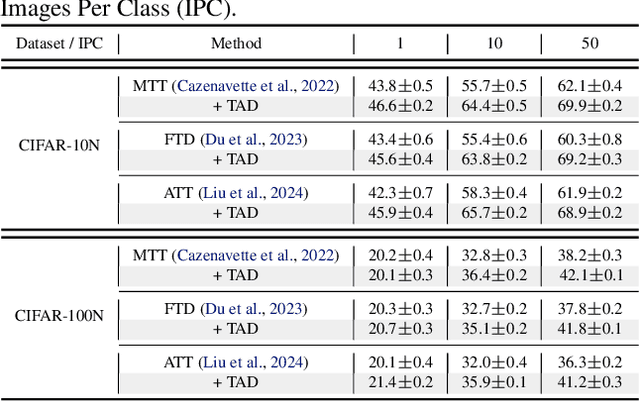
Dataset distillation compresses a large dataset into a small synthetic subset that retains essential information. Existing methods assume that all samples are perfectly labeled, limiting their real-world applications where incorrect labels are ubiquitous. These mislabeled samples introduce untrustworthy information into the dataset, which misleads model optimization in dataset distillation. To tackle this issue, we propose a Trust-Aware Diversion (TAD) dataset distillation method. Our proposed TAD introduces an iterative dual-loop optimization framework for data-effective distillation. Specifically, the outer loop divides data into trusted and untrusted spaces, redirecting distillation toward trusted samples to guarantee trust in the distillation process. This step minimizes the impact of mislabeled samples on dataset distillation. The inner loop maximizes the distillation objective by recalibrating untrusted samples, thus transforming them into valuable ones for distillation. This dual-loop iteratively refines and compensates for each other, gradually expanding the trusted space and shrinking the untrusted space. Experiments demonstrate that our method can significantly improve the performance of existing dataset distillation methods on three widely used benchmarks (CIFAR10, CIFAR100, and Tiny ImageNet) in three challenging mislabeled settings (symmetric, asymmetric, and real-world).