 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHybrid Transformer-Mamba Architecture for Weakly Supervised Volumetric Medical Segmentation
Dec 11, 2025Weakly supervised semantic segmentation offers a label-efficient solution to train segmentation models for volumetric medical imaging. However, existing approaches often rely on 2D encoders that neglect the inherent volumetric nature of the data. We propose TranSamba, a hybrid Transformer-Mamba architecture designed to capture 3D context for weakly supervised volumetric medical segmentation. TranSamba augments a standard Vision Transformer backbone with Cross-Plane Mamba blocks, which leverage the linear complexity of state space models for efficient information exchange across neighboring slices. The information exchange enhances the pairwise self-attention within slices computed by the Transformer blocks, directly contributing to the attention maps for object localization. TranSamba achieves effective volumetric modeling with time complexity that scales linearly with the input volume depth and maintains constant memory usage for batch processing. Extensive experiments on three datasets demonstrate that TranSamba establishes new state-of-the-art performance, consistently outperforming existing methods across diverse modalities and pathologies. Our source code and trained models are openly accessible at: https://github.com/YihengLyu/TranSamba.
Watch and Listen: Understanding Audio-Visual-Speech Moments with Multimodal LLM
May 23, 2025Humans naturally understand moments in a video by integrating visual and auditory cues. For example, localizing a scene in the video like "A scientist passionately speaks on wildlife conservation as dramatic orchestral music plays, with the audience nodding and applauding" requires simultaneous processing of visual, audio, and speech signals. However, existing models often struggle to effectively fuse and interpret audio information, limiting their capacity for comprehensive video temporal understanding. To address this, we present TriSense, a triple-modality large language model designed for holistic video temporal understanding through the integration of visual, audio, and speech modalities. Central to TriSense is a Query-Based Connector that adaptively reweights modality contributions based on the input query, enabling robust performance under modality dropout and allowing flexible combinations of available inputs. To support TriSense's multimodal capabilities, we introduce TriSense-2M, a high-quality dataset of over 2 million curated samples generated via an automated pipeline powered by fine-tuned LLMs. TriSense-2M includes long-form videos and diverse modality combinations, facilitating broad generalization. Extensive experiments across multiple benchmarks demonstrate the effectiveness of TriSense and its potential to advance multimodal video analysis. Code and dataset will be publicly released.
Multitask Deep Learning for Accurate Risk Stratification and Prediction of Next Steps for Coronary CT Angiography Patients
Sep 01, 2023Diagnostic investigation has an important role in risk stratification and clinical decision making of patients with suspected and documented Coronary Artery Disease (CAD). However, the majority of existing tools are primarily focused on the selection of gatekeeper tests, whereas only a handful of systems contain information regarding the downstream testing or treatment. We propose a multi-task deep learning model to support risk stratification and down-stream test selection for patients undergoing Coronary Computed Tomography Angiography (CCTA). The analysis included 14,021 patients who underwent CCTA between 2006 and 2017. Our novel multitask deep learning framework extends the state-of-the art Perceiver model to deal with real-world CCTA report data. Our model achieved an Area Under the receiver operating characteristic Curve (AUC) of 0.76 in CAD risk stratification, and 0.72 AUC in predicting downstream tests. Our proposed deep learning model can accurately estimate the likelihood of CAD and provide recommended downstream tests based on prior CCTA data. In clinical practice, the utilization of such an approach could bring a paradigm shift in risk stratification and downstream management. Despite significant progress using deep learning models for tabular data, they do not outperform gradient boosting decision trees, and further research is required in this area. However, neural networks appear to benefit more readily from multi-task learning than tree-based models. This could offset the shortcomings of using single task learning approach when working with tabular data.
Analysis and Evaluation of Explainable Artificial Intelligence on Suicide Risk Assessment
Mar 09, 2023This study investigates the effectiveness of Explainable Artificial Intelligence (XAI) techniques in predicting suicide risks and identifying the dominant causes for such behaviours. Data augmentation techniques and ML models are utilized to predict the associated risk. Furthermore, SHapley Additive exPlanations (SHAP) and correlation analysis are used to rank the importance of variables in predictions. Experimental results indicate that Decision Tree (DT), Random Forest (RF) and eXtreme Gradient Boosting (XGBoost) models achieve the best results while DT has the best performance with an accuracy of 95:23% and an Area Under Curve (AUC) of 0.95. As per SHAP results, anger problems, depression, and social isolation are the leading variables in predicting the risk of suicide, and patients with good incomes, respected occupations, and university education have the least risk. Results demonstrate the effectiveness of machine learning and XAI framework for suicide risk prediction, and they can assist psychiatrists in understanding complex human behaviours and can also assist in reliable clinical decision-making.
3D Brain and Heart Volume Generative Models: A Survey
Oct 12, 2022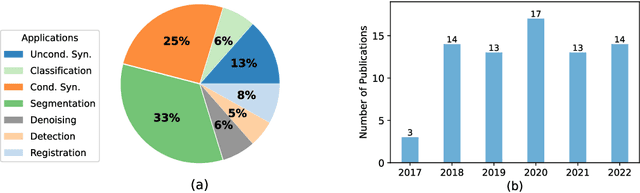
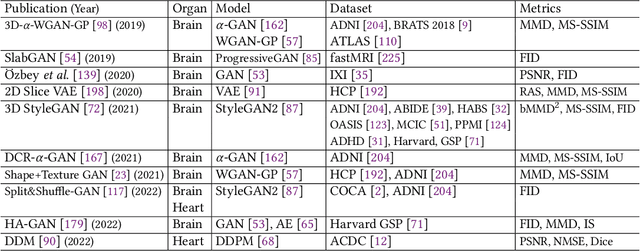
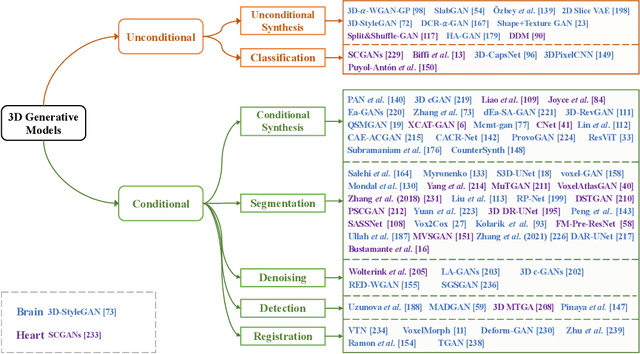

Generative models such as generative adversarial networks and autoencoders have gained a great deal of attention in the medical field due to their excellent data generation capability. This paper provides a comprehensive survey of generative models for three-dimensional (3D) volumes, focusing on the brain and heart. A new and elaborate taxonomy of unconditional and conditional generative models is proposed to cover diverse medical tasks for the brain and heart: unconditional synthesis, classification, conditional synthesis, segmentation, denoising, detection, and registration. We provide relevant background, examine each task and also suggest potential future directions. A list of the latest publications will be updated on Github to keep up with the rapid influx of papers at \url{https://github.com/csyanbin/3D-Medical-Generative-Survey}.
Inflating 2D Convolution Weights for Efficient Generation of 3D Medical Images
Aug 08, 2022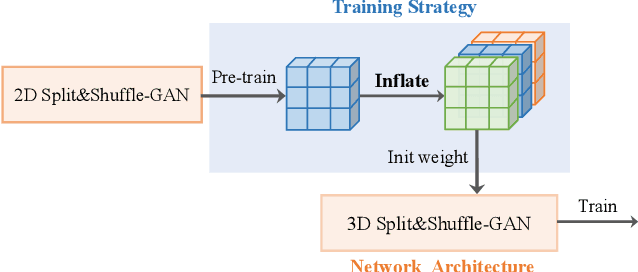
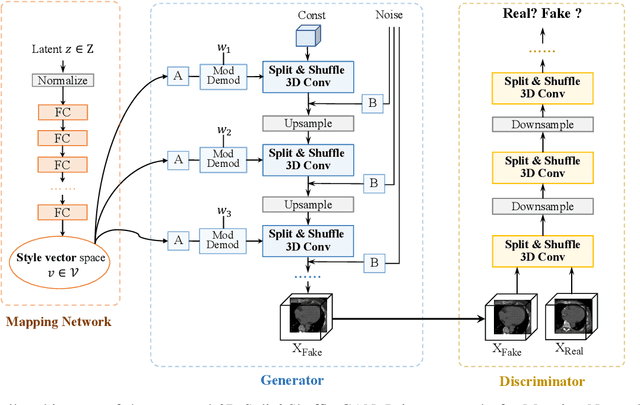
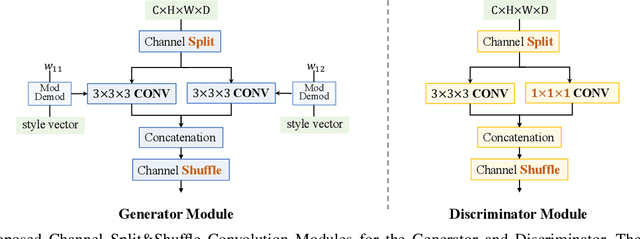
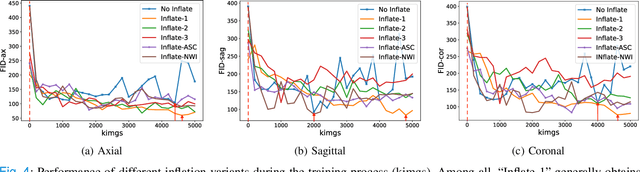
The generation of three-dimensional (3D) medical images can have great application potential since it takes into account the 3D anatomical structure. There are two problems, however, that prevent effective training of a 3D medical generative model: (1) 3D medical images are very expensive to acquire and annotate, resulting in an insufficient number of training images, (2) a large number of parameters are involved in 3D convolution. To address both problems, we propose a novel GAN model called 3D Split&Shuffle-GAN. In order to address the 3D data scarcity issue, we first pre-train a two-dimensional (2D) GAN model using abundant image slices and inflate the 2D convolution weights to improve initialization of the 3D GAN. Novel 3D network architectures are proposed for both the generator and discriminator of the GAN model to significantly reduce the number of parameters while maintaining the quality of image generation. A number of weight inflation strategies and parameter-efficient 3D architectures are investigated. Experiments on both heart (Stanford AIMI Coronary Calcium) and brain (Alzheimer's Disease Neuroimaging Initiative) datasets demonstrate that the proposed approach leads to improved 3D images generation quality with significantly fewer parameters.
Performance of multilabel machine learning models and risk stratification schemas for predicting stroke and bleeding risk in patients with non-valvular atrial fibrillation
Feb 02, 2022
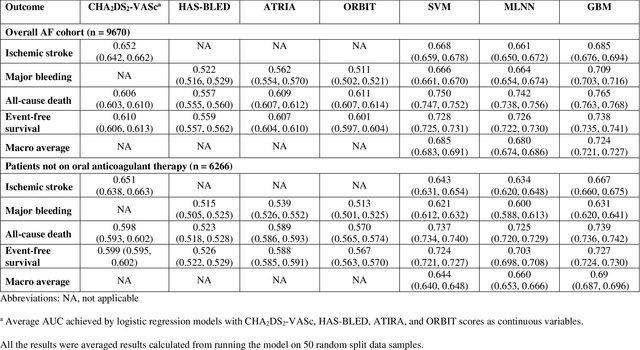
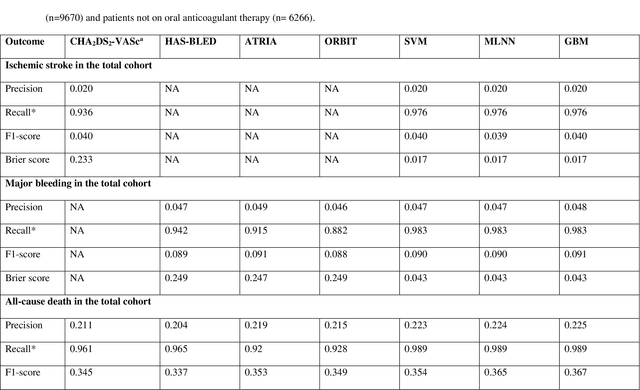
Appropriate antithrombotic therapy for patients with atrial fibrillation (AF) requires assessment of ischemic stroke and bleeding risks. However, risk stratification schemas such as CHA2DS2-VASc and HAS-BLED have modest predictive capacity for patients with AF. Machine learning (ML) techniques may improve predictive performance and support decision-making for appropriate antithrombotic therapy. We compared the performance of multilabel ML models with the currently used risk scores for predicting outcomes in AF patients. Materials and Methods This was a retrospective cohort study of 9670 patients, mean age 76.9 years, 46% women, who were hospitalized with non-valvular AF, and had 1-year follow-up. The primary outcome was ischemic stroke and major bleeding admission. The secondary outcomes were all-cause death and event-free survival. The discriminant power of ML models was compared with clinical risk scores by the area under the curve (AUC). Risk stratification was assessed using the net reclassification index. Results Multilabel gradient boosting machine provided the best discriminant power for stroke, major bleeding, and death (AUC = 0.685, 0.709, and 0.765 respectively) compared to other ML models. It provided modest performance improvement for stroke compared to CHA2DS2-VASc (AUC = 0.652), but significantly improved major bleeding prediction compared to HAS-BLED (AUC = 0.522). It also had a much greater discriminant power for death compared with CHA2DS2-VASc (AUC = 0.606). Also, models identified additional risk features (such as hemoglobin level, renal function, etc.) for each outcome. Conclusions Multilabel ML models can outperform clinical risk stratification scores for predicting the risk of major bleeding and death in non-valvular AF patients.
Explainable Artificial Intelligence for Pharmacovigilance: What Features Are Important When Predicting Adverse Outcomes?
Dec 25, 2021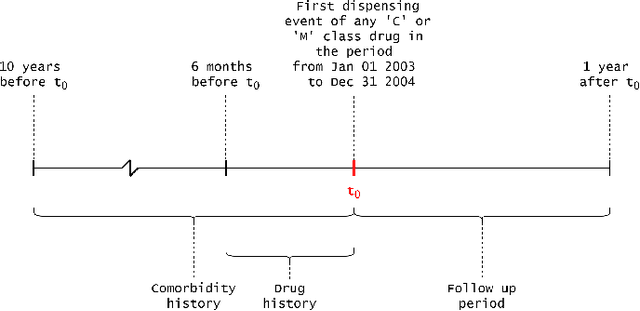

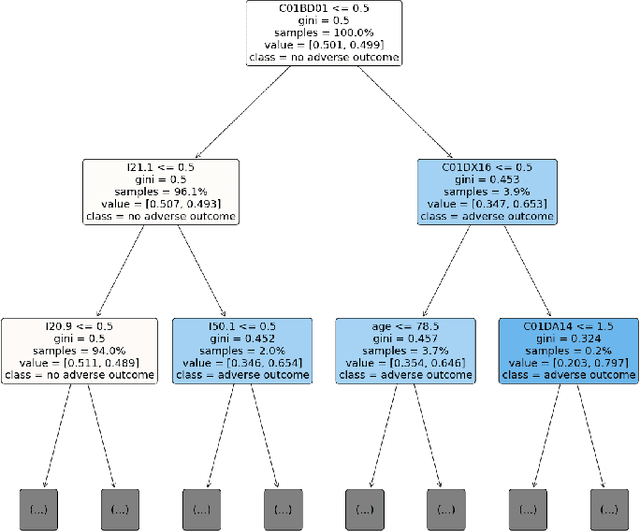
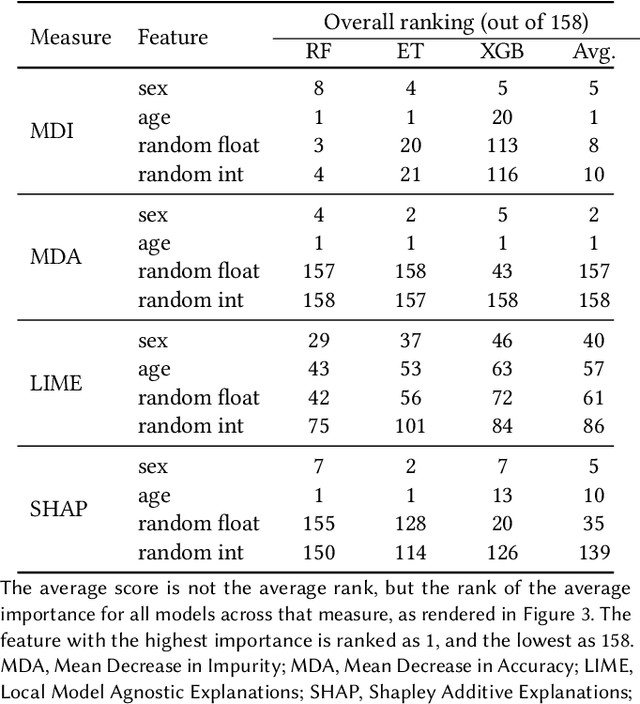
Explainable Artificial Intelligence (XAI) has been identified as a viable method for determining the importance of features when making predictions using Machine Learning (ML) models. In this study, we created models that take an individual's health information (e.g. their drug history and comorbidities) as inputs, and predict the probability that the individual will have an Acute Coronary Syndrome (ACS) adverse outcome. Using XAI, we quantified the contribution that specific drugs had on these ACS predictions, thus creating an XAI-based technique for pharmacovigilance monitoring, using ACS as an example of the adverse outcome to detect. Individuals aged over 65 who were supplied Musculo-skeletal system (anatomical therapeutic chemical (ATC) class M) or Cardiovascular system (ATC class C) drugs between 1993 and 2009 were identified, and their drug histories, comorbidities, and other key features were extracted from linked Western Australian datasets. Multiple ML models were trained to predict if these individuals would have an ACS related adverse outcome (i.e., death or hospitalisation with a discharge diagnosis of ACS), and a variety of ML and XAI techniques were used to calculate which features -- specifically which drugs -- led to these predictions. The drug dispensing features for rofecoxib and celecoxib were found to have a greater than zero contribution to ACS related adverse outcome predictions (on average), and it was found that ACS related adverse outcomes can be predicted with 72% accuracy. Furthermore, the XAI libraries LIME and SHAP were found to successfully identify both important and unimportant features, with SHAP slightly outperforming LIME. ML models trained on linked administrative health datasets in tandem with XAI algorithms can successfully quantify feature importance, and with further development, could potentially be used as pharmacovigilance monitoring techniques.
Training Spiking Neural Networks Using Lessons From Deep Learning
Oct 01, 2021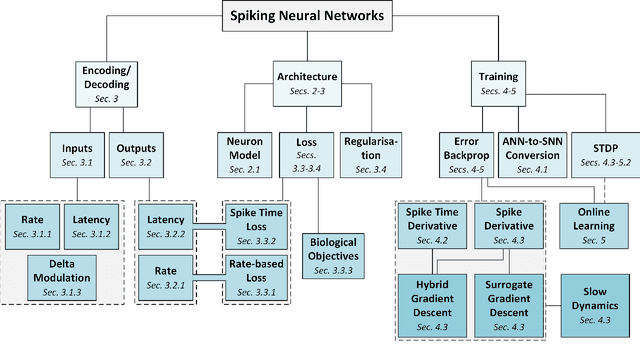

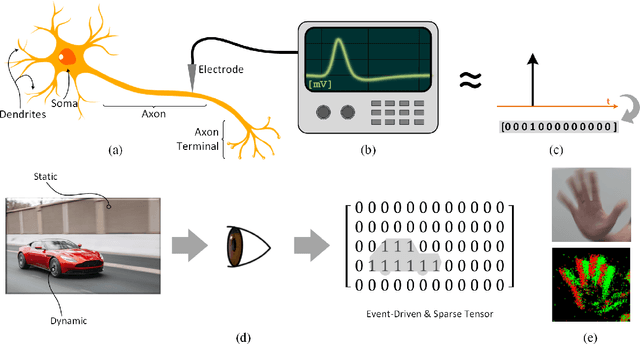

The brain is the perfect place to look for inspiration to develop more efficient neural networks. The inner workings of our synapses and neurons provide a glimpse at what the future of deep learning might look like. This paper serves as a tutorial and perspective showing how to apply the lessons learnt from several decades of research in deep learning, gradient descent, backpropagation and neuroscience to biologically plausible spiking neural neural networks. We also explore the delicate interplay between encoding data as spikes and the learning process; the challenges and solutions of applying gradient-based learning to spiking neural networks; the subtle link between temporal backpropagation and spike timing dependent plasticity, and how deep learning might move towards biologically plausible online learning. Some ideas are well accepted and commonly used amongst the neuromorphic engineering community, while others are presented or justified for the first time here. A series of companion interactive tutorials complementary to this paper using our Python package, snnTorch, are also made available: https://snntorch.readthedocs.io/en/latest/tutorials/index.html
Imputation of Missing Data with Class Imbalance using Conditional Generative Adversarial Networks
Dec 01, 2020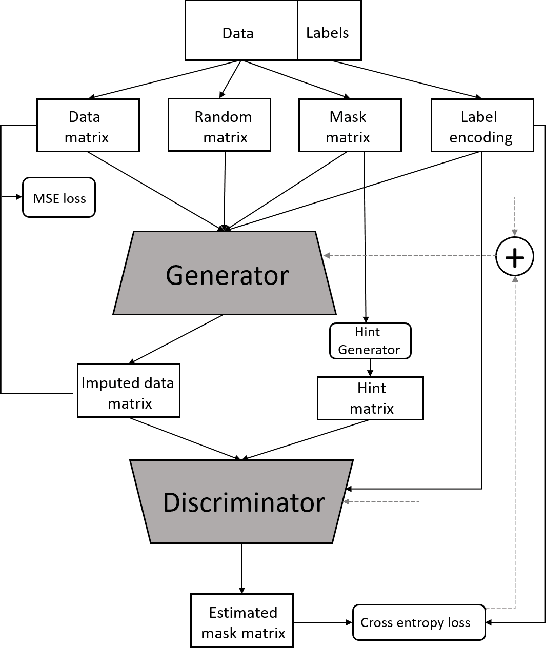

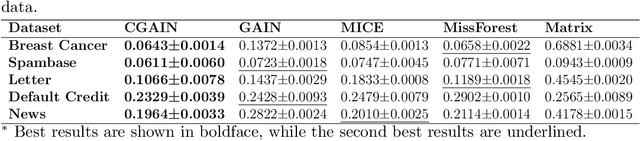
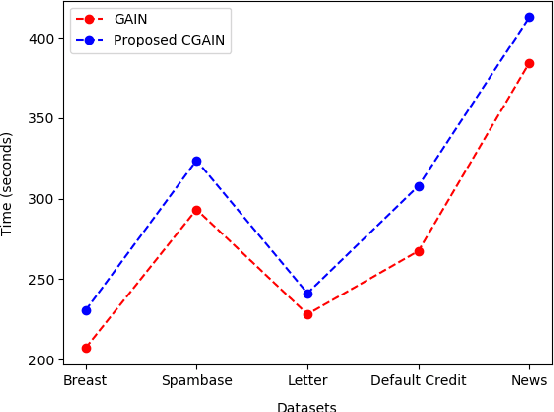
Missing data is a common problem faced with real-world datasets. Imputation is a widely used technique to estimate the missing data. State-of-the-art imputation approaches, such as Generative Adversarial Imputation Nets (GAIN), model the distribution of observed data to approximate the missing values. Such an approach usually models a single distribution for the entire dataset, which overlooks the class-specific characteristics of the data. Class-specific characteristics are especially useful when there is a class imbalance. We propose a new method for imputing missing data based on its class-specific characteristics by adapting the popular Conditional Generative Adversarial Networks (CGAN). Our Conditional Generative Adversarial Imputation Network (CGAIN) imputes the missing data using class-specific distributions, which can produce the best estimates for the missing values. We tested our approach on benchmark datasets and achieved superior performance compared with the state-of-the-art and popular imputation approaches.