 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOptimal Control of Mechanical Ventilators with Learned Respiratory Dynamics
Nov 12, 2024Deciding on appropriate mechanical ventilator management strategies significantly impacts the health outcomes for patients with respiratory diseases. Acute Respiratory Distress Syndrome (ARDS) is one such disease that requires careful ventilator operation to be effectively treated. In this work, we frame the management of ventilators for patients with ARDS as a sequential decision making problem using the Markov decision process framework. We implement and compare controllers based on clinical guidelines contained in the ARDSnet protocol, optimal control theory, and learned latent dynamics represented as neural networks. The Pulse Physiology Engine's respiratory dynamics simulator is used to establish a repeatable benchmark, gather simulated data, and quantitatively compare these controllers. We score performance in terms of measured improvement in established ARDS health markers (pertaining to improved respiratory rate, oxygenation, and vital signs). Our results demonstrate that techniques leveraging neural networks and optimal control can automatically discover effective ventilation management strategies without access to explicit ventilator management procedures or guidelines (such as those defined in the ARDSnet protocol).
Improving Contrastive Learning on Visually Homogeneous Mars Rover Images
Oct 17, 2022

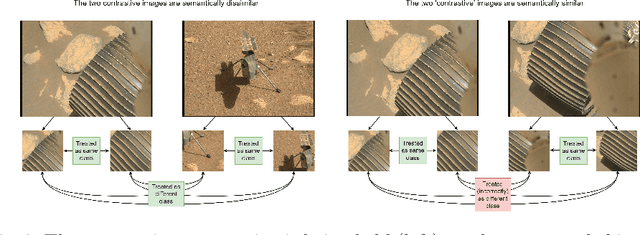

Contrastive learning has recently demonstrated superior performance to supervised learning, despite requiring no training labels. We explore how contrastive learning can be applied to hundreds of thousands of unlabeled Mars terrain images, collected from the Mars rovers Curiosity and Perseverance, and from the Mars Reconnaissance Orbiter. Such methods are appealing since the vast majority of Mars images are unlabeled as manual annotation is labor intensive and requires extensive domain knowledge. Contrastive learning, however, assumes that any given pair of distinct images contain distinct semantic content. This is an issue for Mars image datasets, as any two pairs of Mars images are far more likely to be semantically similar due to the lack of visual diversity on the planet's surface. Making the assumption that pairs of images will be in visual contrast - when they are in fact not - results in pairs that are falsely considered as negatives, impacting training performance. In this study, we propose two approaches to resolve this: 1) an unsupervised deep clustering step on the Mars datasets, which identifies clusters of images containing similar semantic content and corrects false negative errors during training, and 2) a simple approach which mixes data from different domains to increase visual diversity of the total training dataset. Both cases reduce the rate of false negative pairs, thus minimizing the rate in which the model is incorrectly penalized during contrastive training. These modified approaches remain fully unsupervised end-to-end. To evaluate their performance, we add a single linear layer trained to generate class predictions based on these contrastively-learned features and demonstrate increased performance compared to supervised models; observing an improvement in classification accuracy of 3.06% using only 10% of the labeled data.
Explainable Artificial Intelligence for Pharmacovigilance: What Features Are Important When Predicting Adverse Outcomes?
Dec 25, 2021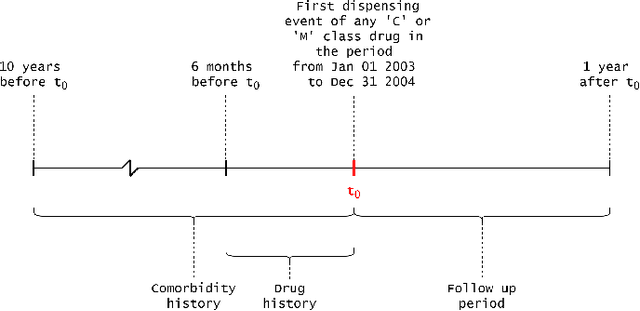

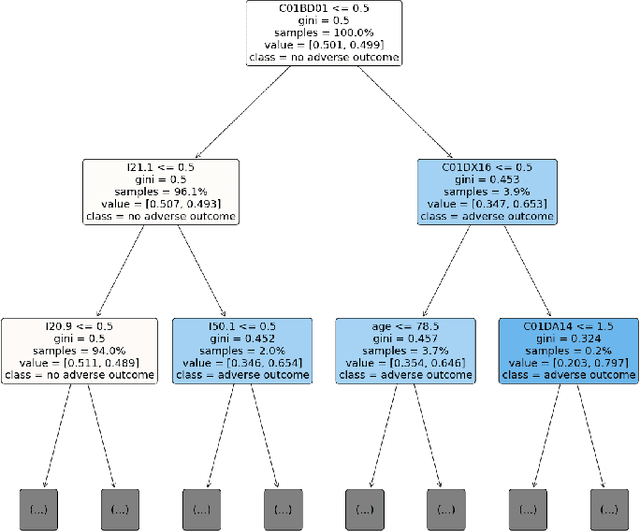
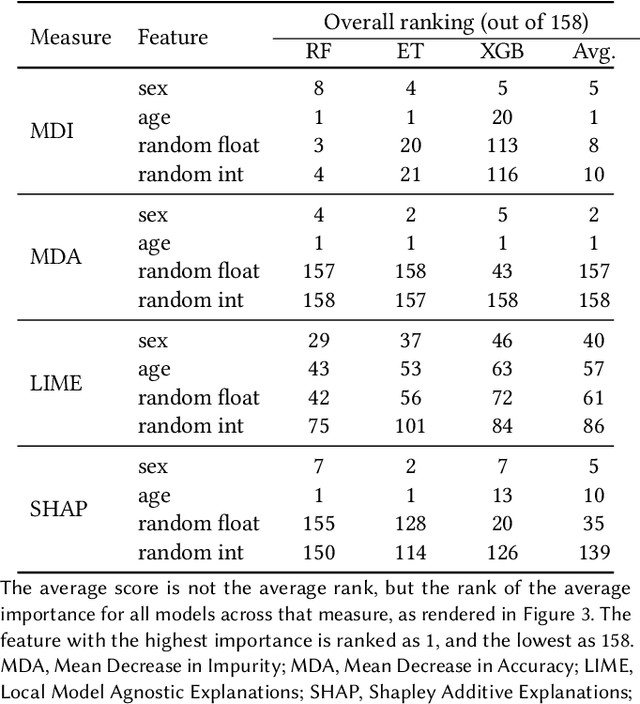
Explainable Artificial Intelligence (XAI) has been identified as a viable method for determining the importance of features when making predictions using Machine Learning (ML) models. In this study, we created models that take an individual's health information (e.g. their drug history and comorbidities) as inputs, and predict the probability that the individual will have an Acute Coronary Syndrome (ACS) adverse outcome. Using XAI, we quantified the contribution that specific drugs had on these ACS predictions, thus creating an XAI-based technique for pharmacovigilance monitoring, using ACS as an example of the adverse outcome to detect. Individuals aged over 65 who were supplied Musculo-skeletal system (anatomical therapeutic chemical (ATC) class M) or Cardiovascular system (ATC class C) drugs between 1993 and 2009 were identified, and their drug histories, comorbidities, and other key features were extracted from linked Western Australian datasets. Multiple ML models were trained to predict if these individuals would have an ACS related adverse outcome (i.e., death or hospitalisation with a discharge diagnosis of ACS), and a variety of ML and XAI techniques were used to calculate which features -- specifically which drugs -- led to these predictions. The drug dispensing features for rofecoxib and celecoxib were found to have a greater than zero contribution to ACS related adverse outcome predictions (on average), and it was found that ACS related adverse outcomes can be predicted with 72% accuracy. Furthermore, the XAI libraries LIME and SHAP were found to successfully identify both important and unimportant features, with SHAP slightly outperforming LIME. ML models trained on linked administrative health datasets in tandem with XAI algorithms can successfully quantify feature importance, and with further development, could potentially be used as pharmacovigilance monitoring techniques.
A Practical Guide to Graph Neural Networks
Oct 11, 2020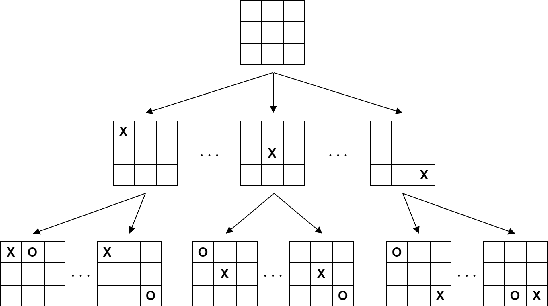
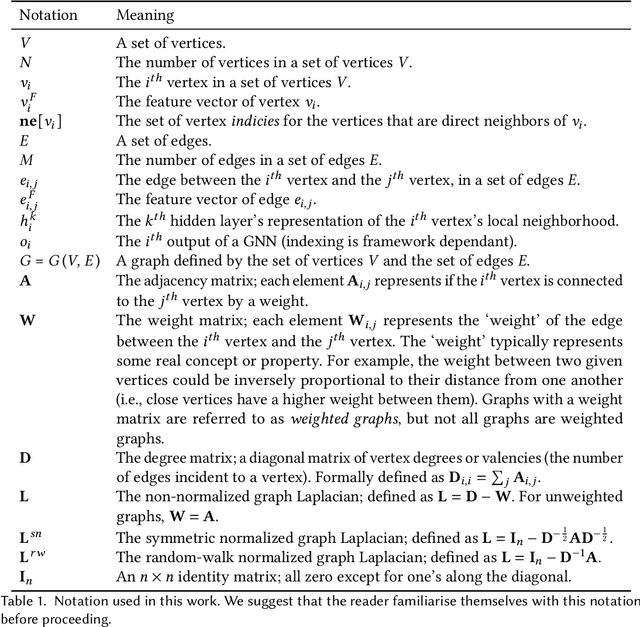
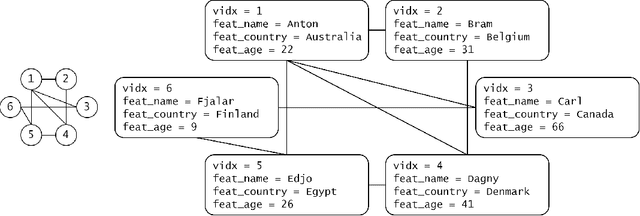
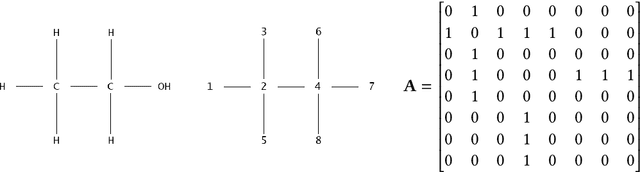
Graph neural networks (GNNs) have recently grown in popularity in the field of artificial intelligence due to their unique ability to ingest relatively unstructured data types as input data. Although some elements of the GNN architecture are conceptually similar in operation to traditional neural networks (and neural network variants), other elements represent a departure from traditional deep learning techniques. This tutorial exposes the power and novelty of GNNs to the average deep learning enthusiast by collating and presenting details on the motivations, concepts, mathematics, and applications of the most common types of GNNs. Importantly, we present this tutorial concisely, alongside worked code examples, and at an introductory pace, thus providing a practical and accessible guide to understanding and using GNNs.
RGB-D image-based Object Detection: from Traditional Methods to Deep Learning Techniques
Jul 22, 2019
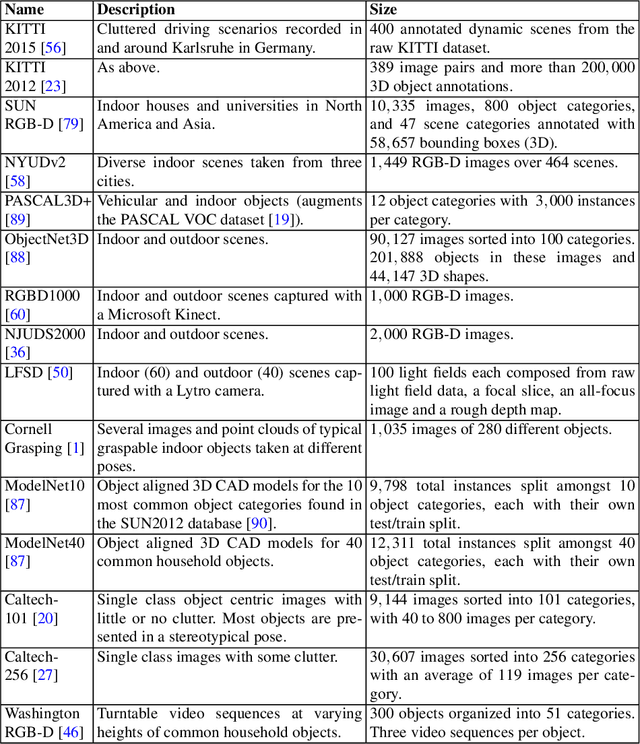

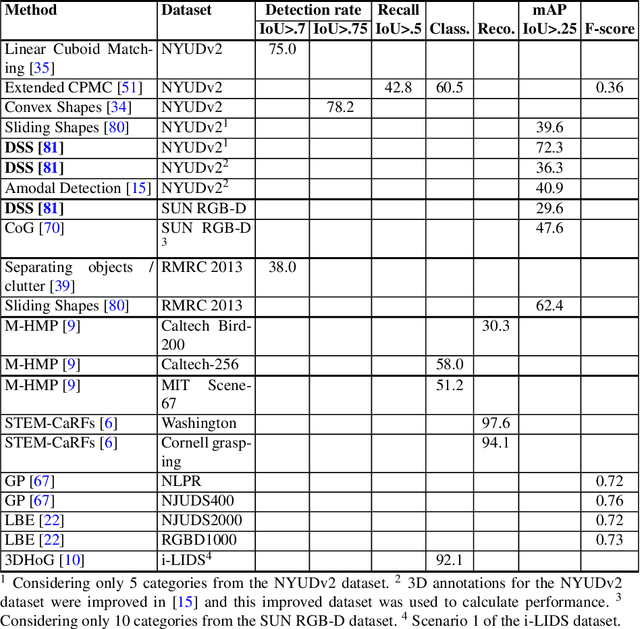
Object detection from RGB images is a long-standing problem in image processing and computer vision. It has applications in various domains including robotics, surveillance, human-computer interaction, and medical diagnosis. With the availability of low cost 3D scanners, a large number of RGB-D object detection approaches have been proposed in the past years. This chapter provides a comprehensive survey of the recent developments in this field. We structure the chapter into two parts; the focus of the first part is on techniques that are based on hand-crafted features combined with machine learning algorithms. The focus of the second part is on the more recent work, which is based on deep learning. Deep learning techniques, coupled with the availability of large training datasets, have now revolutionized the field of computer vision, including RGB-D object detection, achieving an unprecedented level of performance. We survey the key contributions, summarize the most commonly used pipelines, discuss their benefits and limitations, and highlight some important directions for future research.
Improving Image-Based Localization with Deep Learning: The Impact of the Loss Function
Apr 28, 2019
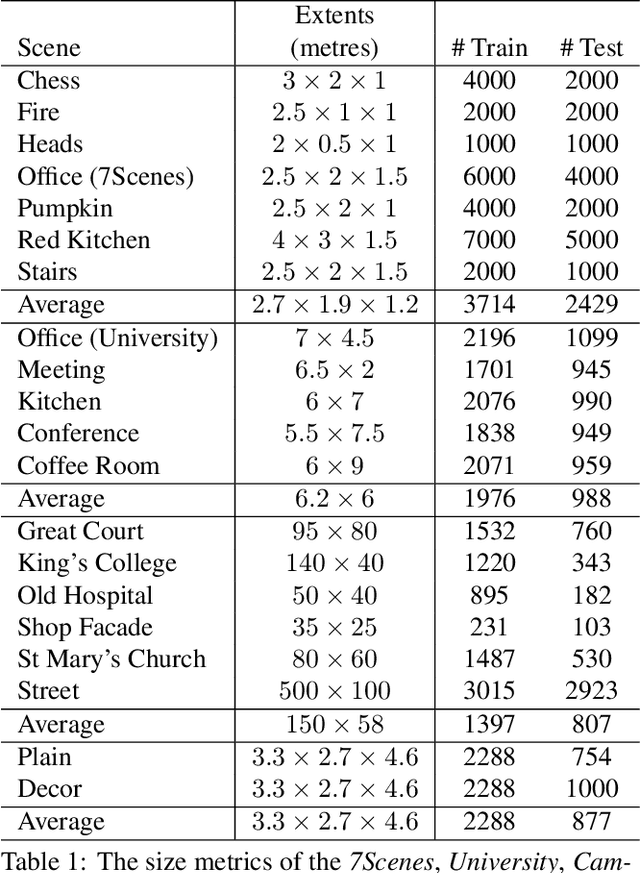
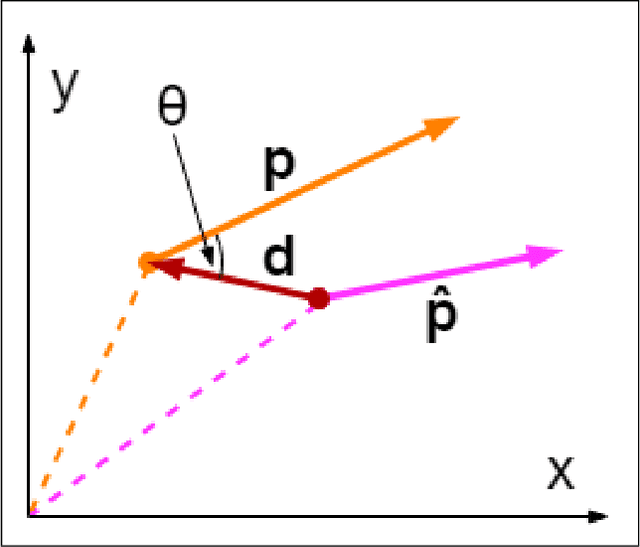
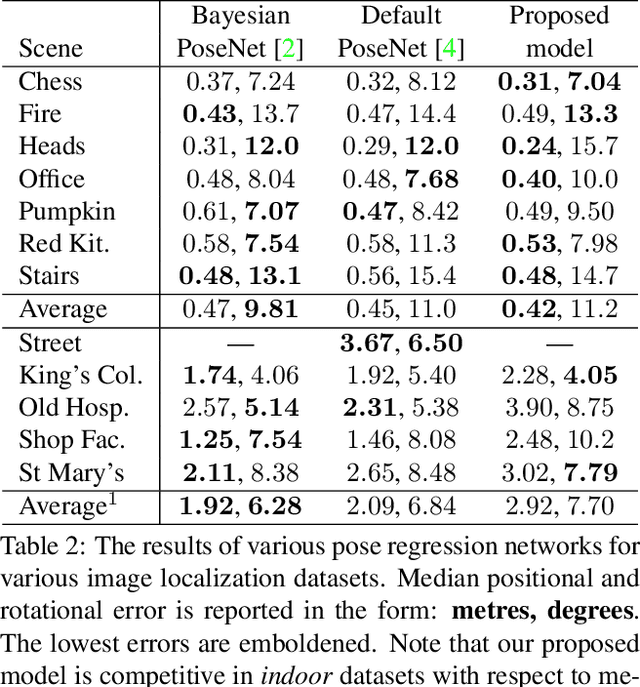
This work formulates a novel loss term which can be appended to an RGB only image localization network's loss function to improve its performance. A common technique used when regressing a camera's pose from an image is to formulate the loss as a linear combination of positional and rotational error (using tuned hyperparameters as coefficients). In this work we observe that changes to rotation and position mutually affect the captured image, and in order to improve performance, a network's loss function should include a term which combines error in both position and rotation. To that end we design a geometric loss term which considers the similarity between the predicted and ground truth poses using both position and rotation, and use it to augment the existing image localization network PoseNet. The loss term is simply appended to the loss function of the already existing image localization network. We achieve improvements in the localization accuracy of the network for indoor scenes: with decreases of up to 9.64% and 2.99% in the median positional and rotational error when compared to similar pipelines.
Optical Flow Techniques for Facial Expression Analysis: Performance Evaluation and Improvements
Apr 25, 2019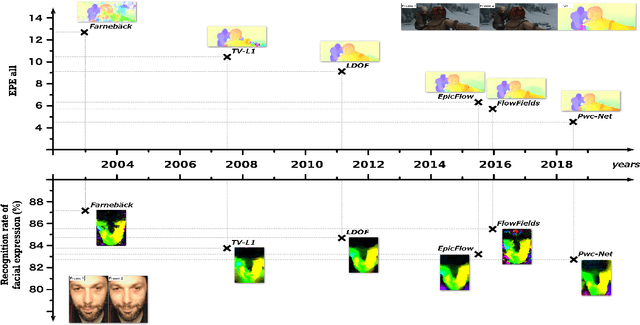


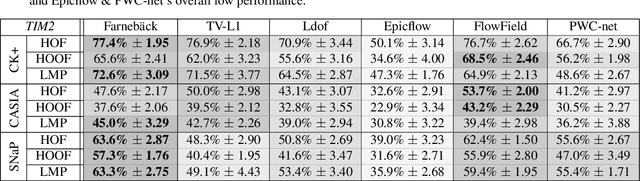
Optical flow techniques are becoming increasingly performant and robust when estimating motion in a scene, but their performance has yet to be proven in the area of facial expression recognition. In this work, a variety of optical flow approaches are evaluated across multiple facial expression datasets, so as to provide a consistent performance evaluation. Additionally, the strengths of multiple optical flow approaches are combined in a novel data augmentation scheme. Under this scheme, increases in average accuracy of up to 6% (depending on the choice of optical flow approaches and dataset) have been achieved.