 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Self-Supervised Approach to Land Cover Segmentation
Oct 27, 2023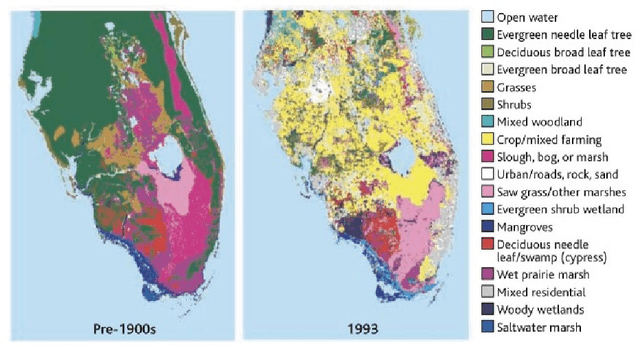


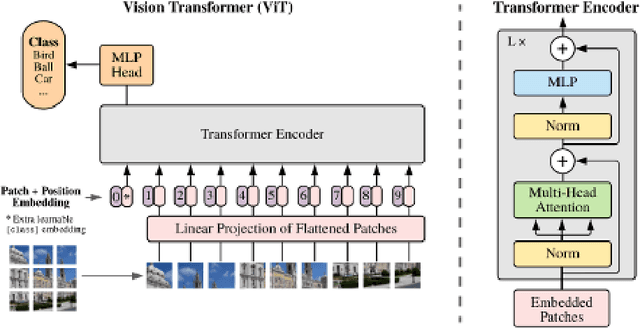
Land use/land cover change (LULC) maps are integral resources in earth science and agricultural research. Due to the nature of such maps, the creation of LULC maps is often constrained by the time and human resources necessary to accurately annotate satellite imagery and remote sensing data. While computer vision models that perform semantic segmentation to create detailed labels from such data are not uncommon, litle research has been done on self-supervised and unsupervised approaches to labelling LULC maps without the use of ground-truth masks. Here, we demonstrate a self-supervised method of land cover segmentation that has no need for high-quality ground truth labels. The proposed deep learning employs a frozen pre-trained ViT backbone transferred from DINO in a STEGO architecture and is fine-tuned using a custom dataset consisting of very high resolution (VHR) sattelite imagery. After only 10 epochs of fine-tuning, an accuracy of roughly 52% was observed across 5 samples, signifying the feasibility of self-supervised models for the automated labelling of VHR LULC maps.
URA*: Uncertainty-aware Path Planning using Image-based Aerial-to-Ground Traversability Estimation for Off-road Environments
Sep 15, 2023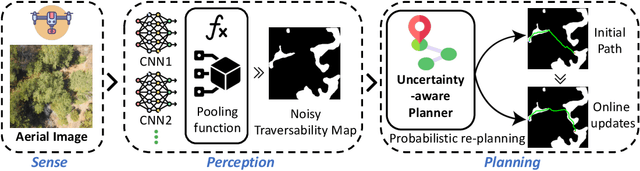
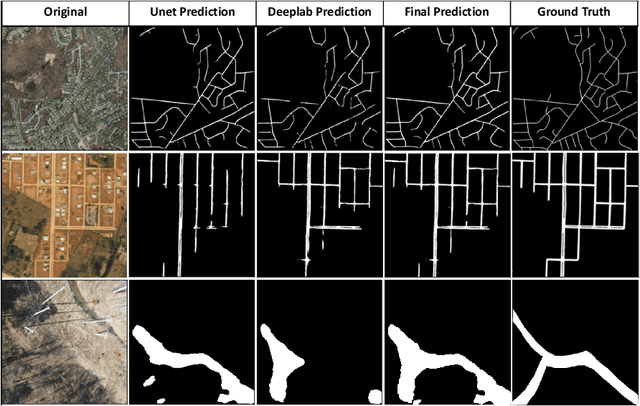
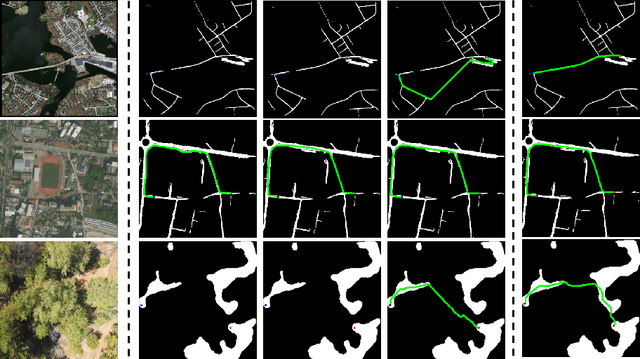
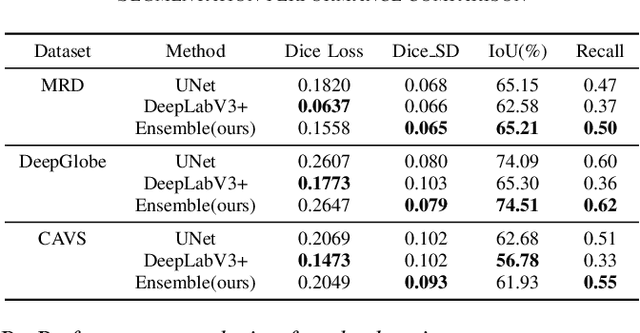
A major challenge with off-road autonomous navigation is the lack of maps or road markings that can be used to plan a path for autonomous robots. Classical path planning methods mostly assume a perfectly known environment without accounting for the inherent perception and sensing uncertainty from detecting terrain and obstacles in off-road environments. Recent work in computer vision and deep neural networks has advanced the capability of terrain traversability segmentation from raw images; however, the feasibility of using these noisy segmentation maps for navigation and path planning has not been adequately explored. To address this problem, this research proposes an uncertainty-aware path planning method, URA* using aerial images for autonomous navigation in off-road environments. An ensemble convolutional neural network (CNN) model is first used to perform pixel-level traversability estimation from aerial images of the region of interest. The traversability predictions are represented as a grid of traversal probability values. An uncertainty-aware planner is then applied to compute the best path from a start point to a goal point given these noisy traversal probability estimates. The proposed planner also incorporates replanning techniques to allow rapid replanning during online robot operation. The proposed method is evaluated on the Massachusetts Road Dataset, the DeepGlobe dataset, as well as a dataset of aerial images from off-road proving grounds at Mississippi State University. Results show that the proposed image segmentation and planning methods outperform conventional planning algorithms in terms of the quality and feasibility of the initial path, as well as the quality of replanned paths.
Improving Contrastive Learning on Visually Homogeneous Mars Rover Images
Oct 17, 2022

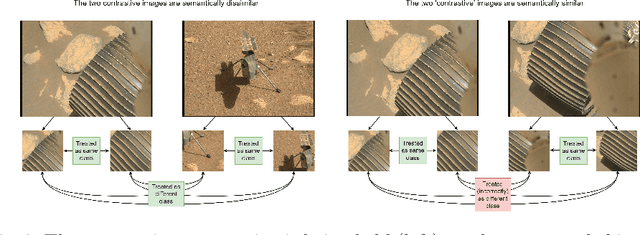

Contrastive learning has recently demonstrated superior performance to supervised learning, despite requiring no training labels. We explore how contrastive learning can be applied to hundreds of thousands of unlabeled Mars terrain images, collected from the Mars rovers Curiosity and Perseverance, and from the Mars Reconnaissance Orbiter. Such methods are appealing since the vast majority of Mars images are unlabeled as manual annotation is labor intensive and requires extensive domain knowledge. Contrastive learning, however, assumes that any given pair of distinct images contain distinct semantic content. This is an issue for Mars image datasets, as any two pairs of Mars images are far more likely to be semantically similar due to the lack of visual diversity on the planet's surface. Making the assumption that pairs of images will be in visual contrast - when they are in fact not - results in pairs that are falsely considered as negatives, impacting training performance. In this study, we propose two approaches to resolve this: 1) an unsupervised deep clustering step on the Mars datasets, which identifies clusters of images containing similar semantic content and corrects false negative errors during training, and 2) a simple approach which mixes data from different domains to increase visual diversity of the total training dataset. Both cases reduce the rate of false negative pairs, thus minimizing the rate in which the model is incorrectly penalized during contrastive training. These modified approaches remain fully unsupervised end-to-end. To evaluate their performance, we add a single linear layer trained to generate class predictions based on these contrastively-learned features and demonstrate increased performance compared to supervised models; observing an improvement in classification accuracy of 3.06% using only 10% of the labeled data.