 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCottonSim: Development of an autonomous visual-guided robotic cotton-picking system in the Gazebo
May 08, 2025



In this study, an autonomous visual-guided robotic cotton-picking system, built on a Clearpath's Husky robot platform and the Cotton-Eye perception system, was developed in the Gazebo robotic simulator. Furthermore, a virtual cotton farm was designed and developed as a Robot Operating System (ROS 1) package to deploy the robotic cotton picker in the Gazebo environment for simulating autonomous field navigation. The navigation was assisted by the map coordinates and an RGB-depth camera, while the ROS navigation algorithm utilized a trained YOLOv8n-seg model for instance segmentation. The model achieved a desired mean Average Precision (mAP) of 85.2%, a recall of 88.9%, and a precision of 93.0% for scene segmentation. The developed ROS navigation packages enabled our robotic cotton-picking system to autonomously navigate through the cotton field using map-based and GPS-based approaches, visually aided by a deep learning-based perception system. The GPS-based navigation approach achieved a 100% completion rate (CR) with a threshold of 5 x 10^-6 degrees, while the map-based navigation approach attained a 96.7% CR with a threshold of 0.25 m. This study establishes a fundamental baseline of simulation for future agricultural robotics and autonomous vehicles in cotton farming and beyond. CottonSim code and data are released to the research community via GitHub: https://github.com/imtheva/CottonSim
X-DECODE: EXtreme Deblurring with Curriculum Optimization and Domain Equalization
Apr 10, 2025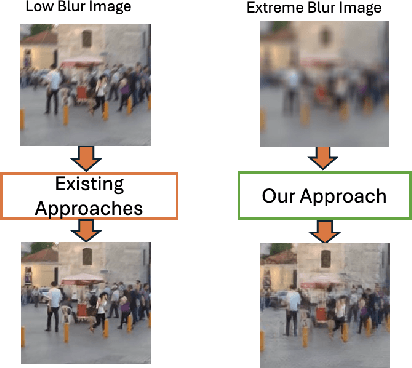
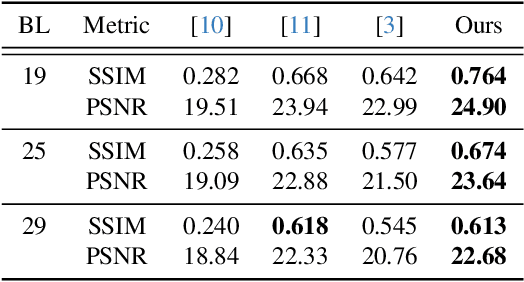
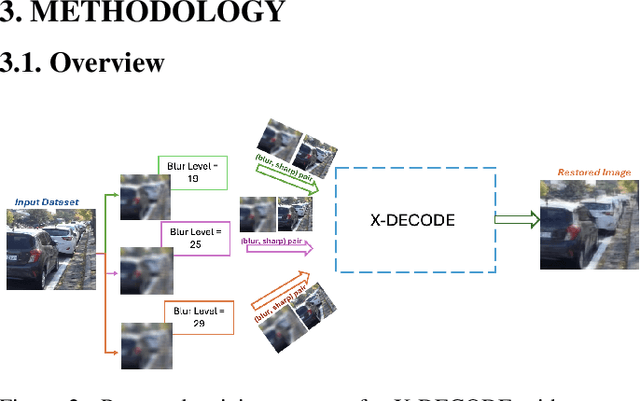
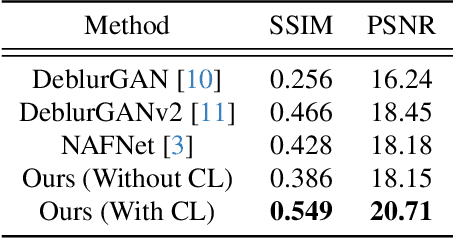
Restoring severely blurred images remains a significant challenge in computer vision, impacting applications in autonomous driving, medical imaging, and photography. This paper introduces a novel training strategy based on curriculum learning to improve the robustness of deep learning models for extreme image deblurring. Unlike conventional approaches that train on only low to moderate blur levels, our method progressively increases the difficulty by introducing images with higher blur severity over time, allowing the model to adapt incrementally. Additionally, we integrate perceptual and hinge loss during training to enhance fine detail restoration and improve training stability. We experimented with various curriculum learning strategies and explored the impact of the train-test domain gap on the deblurring performance. Experimental results on the Extreme-GoPro dataset showed that our method outperforms the next best method by 14% in SSIM, whereas experiments on the Extreme-KITTI dataset showed that our method outperforms the next best by 18% in SSIM. Ablation studies showed that a linear curriculum progression outperforms step-wise, sigmoid, and exponential progressions, while hyperparameter settings such as the training blur percentage and loss function formulation all play important roles in addressing extreme blur artifacts. Datasets and code are available at https://github.com/RAPTOR-MSSTATE/XDECODE
The AI Pentad, the CHARME$^{2}$D Model, and an Assessment of Current-State AI Regulation
Mar 08, 2025



Artificial Intelligence (AI) has made remarkable progress in the past few years with AI-enabled applications beginning to permeate every aspect of our society. Despite the widespread consensus on the need to regulate AI, there remains a lack of a unified approach to framing, developing, and assessing AI regulations. Many of the existing methods take a value-based approach, for example, accountability, fairness, free from bias, transparency, and trust. However, these methods often face challenges at the outset due to disagreements in academia over the subjective nature of these definitions. This paper aims to establish a unifying model for AI regulation from the perspective of core AI components. We first introduce the AI Pentad, which comprises the five essential components of AI: humans and organizations, algorithms, data, computing, and energy. We then review AI regulatory enablers, including AI registration and disclosure, AI monitoring, and AI enforcement mechanisms. Subsequently, we present the CHARME$^{2}$D Model to explore further the relationship between the AI Pentad and AI regulatory enablers. Finally, we apply the CHARME$^{2}$D model to assess AI regulatory efforts in the European Union (EU), China, the United Arab Emirates (UAE), the United Kingdom (UK), and the United States (US), highlighting their strengths, weaknesses, and gaps. This comparative evaluation offers insights for future legislative work in the AI domain.
A Survey on Privacy Attacks Against Digital Twin Systems in AI-Robotics
Jun 27, 2024



Industry 4.0 has witnessed the rise of complex robots fueled by the integration of Artificial Intelligence/Machine Learning (AI/ML) and Digital Twin (DT) technologies. While these technologies offer numerous benefits, they also introduce potential privacy and security risks. This paper surveys privacy attacks targeting robots enabled by AI and DT models. Exfiltration and data leakage of ML models are discussed in addition to the potential extraction of models derived from first-principles (e.g., physics-based). We also discuss design considerations with DT-integrated robotics touching on the impact of ML model training, responsible AI and DT safeguards, data governance and ethical considerations on the effectiveness of these attacks. We advocate for a trusted autonomy approach, emphasizing the need to combine robotics, AI, and DT technologies with robust ethical frameworks and trustworthiness principles for secure and reliable AI robotic systems.
Security Considerations in AI-Robotics: A Survey of Current Methods, Challenges, and Opportunities
Oct 18, 2023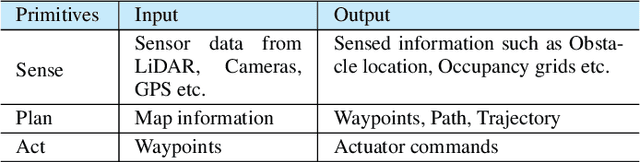
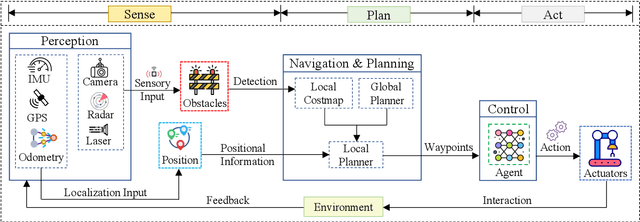
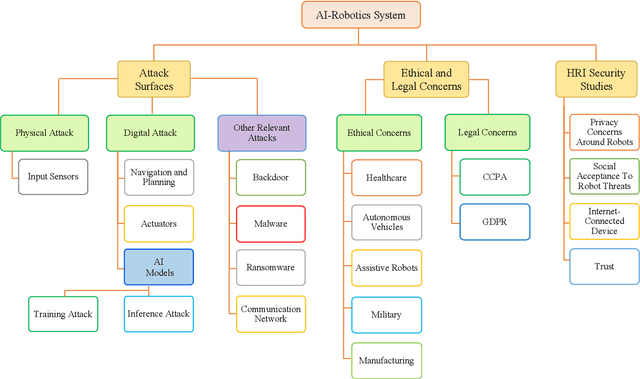
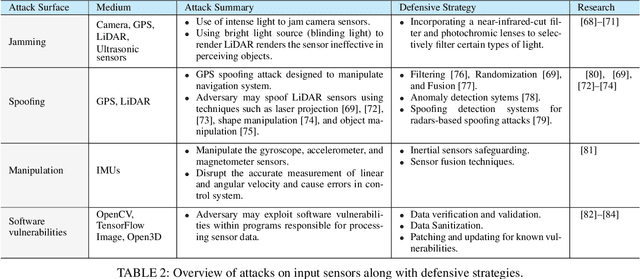
Robotics and Artificial Intelligence (AI) have been inextricably intertwined since their inception. Today, AI-Robotics systems have become an integral part of our daily lives, from robotic vacuum cleaners to semi-autonomous cars. These systems are built upon three fundamental architectural elements: perception, navigation and planning, and control. However, while the integration of AI-Robotics systems has enhanced the quality our lives, it has also presented a serious problem - these systems are vulnerable to security attacks. The physical components, algorithms, and data that make up AI-Robotics systems can be exploited by malicious actors, potentially leading to dire consequences. Motivated by the need to address the security concerns in AI-Robotics systems, this paper presents a comprehensive survey and taxonomy across three dimensions: attack surfaces, ethical and legal concerns, and Human-Robot Interaction (HRI) security. Our goal is to provide users, developers and other stakeholders with a holistic understanding of these areas to enhance the overall AI-Robotics system security. We begin by surveying potential attack surfaces and provide mitigating defensive strategies. We then delve into ethical issues, such as dependency and psychological impact, as well as the legal concerns regarding accountability for these systems. Besides, emerging trends such as HRI are discussed, considering privacy, integrity, safety, trustworthiness, and explainability concerns. Finally, we present our vision for future research directions in this dynamic and promising field.
URA*: Uncertainty-aware Path Planning using Image-based Aerial-to-Ground Traversability Estimation for Off-road Environments
Sep 15, 2023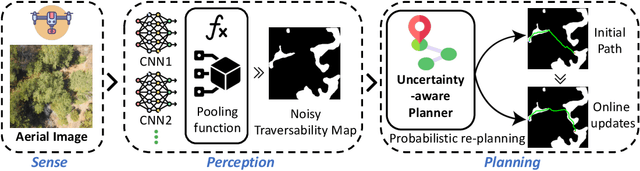
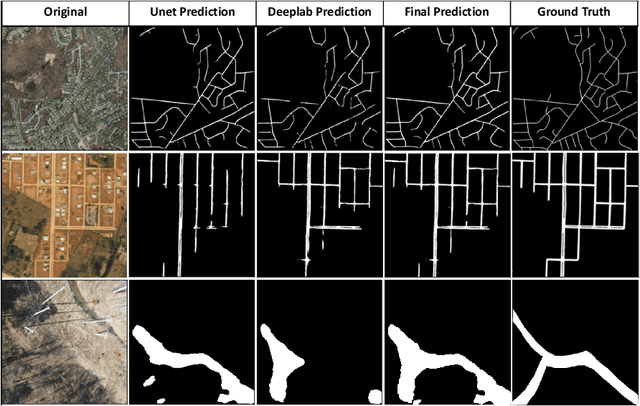
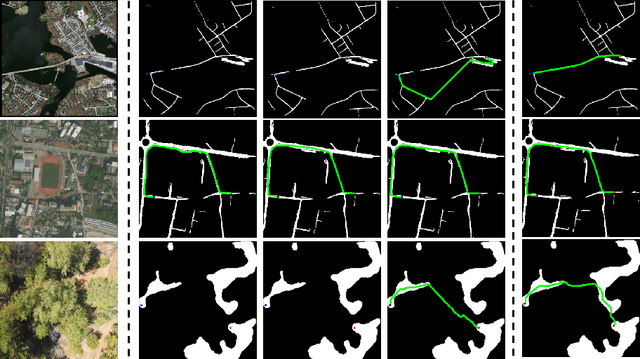
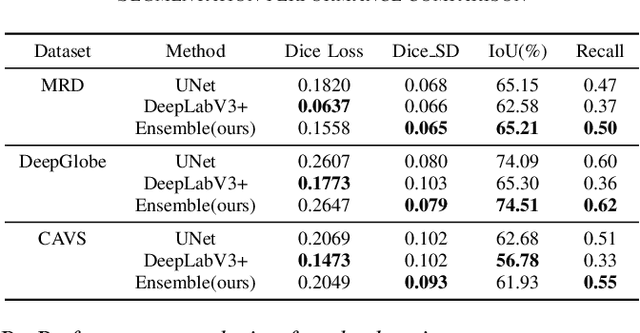
A major challenge with off-road autonomous navigation is the lack of maps or road markings that can be used to plan a path for autonomous robots. Classical path planning methods mostly assume a perfectly known environment without accounting for the inherent perception and sensing uncertainty from detecting terrain and obstacles in off-road environments. Recent work in computer vision and deep neural networks has advanced the capability of terrain traversability segmentation from raw images; however, the feasibility of using these noisy segmentation maps for navigation and path planning has not been adequately explored. To address this problem, this research proposes an uncertainty-aware path planning method, URA* using aerial images for autonomous navigation in off-road environments. An ensemble convolutional neural network (CNN) model is first used to perform pixel-level traversability estimation from aerial images of the region of interest. The traversability predictions are represented as a grid of traversal probability values. An uncertainty-aware planner is then applied to compute the best path from a start point to a goal point given these noisy traversal probability estimates. The proposed planner also incorporates replanning techniques to allow rapid replanning during online robot operation. The proposed method is evaluated on the Massachusetts Road Dataset, the DeepGlobe dataset, as well as a dataset of aerial images from off-road proving grounds at Mississippi State University. Results show that the proposed image segmentation and planning methods outperform conventional planning algorithms in terms of the quality and feasibility of the initial path, as well as the quality of replanned paths.
Analysis of LiDAR Configurations on Off-road Semantic Segmentation Performance
Jun 28, 2023This paper investigates the impact of LiDAR configuration shifts on the performance of 3D LiDAR point cloud semantic segmentation models, a topic not extensively studied before. We explore the effect of using different LiDAR channels when training and testing a 3D LiDAR point cloud semantic segmentation model, utilizing Cylinder3D for the experiments. A Cylinder3D model is trained and tested on simulated 3D LiDAR point cloud datasets created using the Mississippi State University Autonomous Vehicle Simulator (MAVS) and 32, 64 channel 3D LiDAR point clouds of the RELLIS-3D dataset collected in a real-world off-road environment. Our experimental results demonstrate that sensor and spatial domain shifts significantly impact the performance of LiDAR-based semantic segmentation models. In the absence of spatial domain changes between training and testing, models trained and tested on the same sensor type generally exhibited better performance. Moreover, higher-resolution sensors showed improved performance compared to those with lower-resolution ones. However, results varied when spatial domain changes were present. In some cases, the advantage of a sensor's higher resolution led to better performance both with and without sensor domain shifts. In other instances, the higher resolution resulted in overfitting within a specific domain, causing a lack of generalization capability and decreased performance when tested on data with different sensor configurations.
A Hybrid Semantic-Geometric Approach for Clutter-Resistant Floorplan Generation from Building Point Clouds
May 15, 2023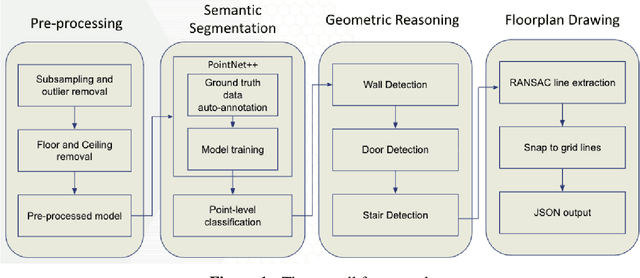



Building Information Modeling (BIM) technology is a key component of modern construction engineering and project management workflows. As-is BIM models that represent the spatial reality of a project site can offer crucial information to stakeholders for construction progress monitoring, error checking, and building maintenance purposes. Geometric methods for automatically converting raw scan data into BIM models (Scan-to-BIM) often fail to make use of higher-level semantic information in the data. Whereas, semantic segmentation methods only output labels at the point level without creating object level models that is necessary for BIM. To address these issues, this research proposes a hybrid semantic-geometric approach for clutter-resistant floorplan generation from laser-scanned building point clouds. The input point clouds are first pre-processed by normalizing the coordinate system and removing outliers. Then, a semantic segmentation network based on PointNet++ is used to label each point as ceiling, floor, wall, door, stair, and clutter. The clutter points are removed whereas the wall, door, and stair points are used for 2D floorplan generation. A region-growing segmentation algorithm paired with geometric reasoning rules is applied to group the points together into individual building elements. Finally, a 2-fold Random Sample Consensus (RANSAC) algorithm is applied to parameterize the building elements into 2D lines which are used to create the output floorplan. The proposed method is evaluated using the metrics of precision, recall, Intersection-over-Union (IOU), Betti error, and warping error.
AI Security Threats against Pervasive Robotic Systems: A Course for Next Generation Cybersecurity Workforce
Feb 15, 2023Robotics, automation, and related Artificial Intelligence (AI) systems have become pervasive bringing in concerns related to security, safety, accuracy, and trust. With growing dependency on physical robots that work in close proximity to humans, the security of these systems is becoming increasingly important to prevent cyber-attacks that could lead to privacy invasion, critical operations sabotage, and bodily harm. The current shortfall of professionals who can defend such systems demands development and integration of such a curriculum. This course description includes details about seven self-contained and adaptive modules on "AI security threats against pervasive robotic systems". Topics include: 1) Introduction, examples of attacks, and motivation; 2) - Robotic AI attack surfaces and penetration testing; 3) - Attack patterns and security strategies for input sensors; 4) - Training attacks and associated security strategies; 5) - Inference attacks and associated security strategies; 6) - Actuator attacks and associated security strategies; and 7) - Ethics of AI, robotics, and cybersecurity.
Improving Contrastive Learning on Visually Homogeneous Mars Rover Images
Oct 17, 2022

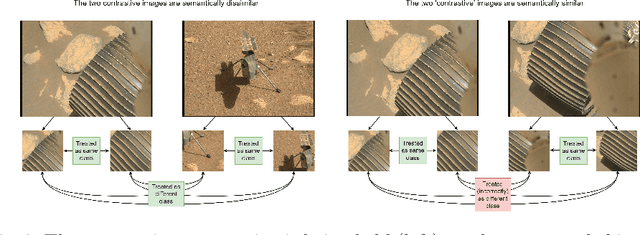

Contrastive learning has recently demonstrated superior performance to supervised learning, despite requiring no training labels. We explore how contrastive learning can be applied to hundreds of thousands of unlabeled Mars terrain images, collected from the Mars rovers Curiosity and Perseverance, and from the Mars Reconnaissance Orbiter. Such methods are appealing since the vast majority of Mars images are unlabeled as manual annotation is labor intensive and requires extensive domain knowledge. Contrastive learning, however, assumes that any given pair of distinct images contain distinct semantic content. This is an issue for Mars image datasets, as any two pairs of Mars images are far more likely to be semantically similar due to the lack of visual diversity on the planet's surface. Making the assumption that pairs of images will be in visual contrast - when they are in fact not - results in pairs that are falsely considered as negatives, impacting training performance. In this study, we propose two approaches to resolve this: 1) an unsupervised deep clustering step on the Mars datasets, which identifies clusters of images containing similar semantic content and corrects false negative errors during training, and 2) a simple approach which mixes data from different domains to increase visual diversity of the total training dataset. Both cases reduce the rate of false negative pairs, thus minimizing the rate in which the model is incorrectly penalized during contrastive training. These modified approaches remain fully unsupervised end-to-end. To evaluate their performance, we add a single linear layer trained to generate class predictions based on these contrastively-learned features and demonstrate increased performance compared to supervised models; observing an improvement in classification accuracy of 3.06% using only 10% of the labeled data.