 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhen No Benchmark Exists: Validating Comparative LLM Safety Scoring Without Ground-Truth Labels
May 07, 2026Many deployments must compare candidate language models for safety before a labeled benchmark exists for the relevant language, sector, or regulatory regime. We formalize this setting as benchmarkless comparative safety scoring and specify the contract under which a scenario-based audit can be interpreted as deployment evidence. Scores are valid only under a fixed scenario pack, rubric, auditor, judge, sampling configuration, and rerun budget. Because no labels are available, we replace ground-truth agreement with an instrumental-validity chain: responsiveness to a controlled safe-versus-abliterated contrast, dominance of target-driven variance over auditor and judge artifacts, and stability across reruns. We instantiate the chain in SimpleAudit, a local-first scoring instrument, and validate it on a Norwegian safety pack. Safe and abliterated targets separate with AUROC values between 0.89 and 1.00, target identity is the dominant variance component ($η^2 \approx 0.52$), and severity profiles stabilize by ten reruns. Applying the same chain to Petri shows that it admits both tools. The substantial differences arise upstream of the chain, in claim-contract enforcement and deployment fit. A Norwegian public-sector procurement case comparing Borealis and Gemma 3 demonstrates the resulting evidence in practice: the safer model depends on scenario category and risk measure. Consequently, scores, matched deltas, critical rates, uncertainty, and the auditor and judge used must be reported together rather than collapsed into a single ranking.
Knowledge-Guided Retrieval-Augmented Generation for Zero-Shot Psychiatric Data: Privacy Preserving Synthetic Data Generation
Mar 26, 2026AI systems in healthcare research have shown potential to increase patient throughput and assist clinicians, yet progress is constrained by limited access to real patient data. To address this issue, we present a zero-shot, knowledge-guided framework for psychiatric tabular data in which large language models (LLMs) are steered via Retrieval-Augmented Generation using the Diagnostic and Statistical Manual of Mental Disorders (DSM-5) and the International Classification of Diseases (ICD-10). We conducted experiments using different combinations of knowledge bases to generate privacy-preserving synthetic data. The resulting models were benchmarked against two state-of-the-art deep learning models for synthetic tabular data generation, namely CTGAN and TVAE, both of which rely on real data and therefore entail potential privacy risks. Evaluation was performed on six anxiety-related disorders: specific phobia, social anxiety disorder, agoraphobia, generalized anxiety disorder, separation anxiety disorder, and panic disorder. CTGAN typically achieves the best marginals and multivariate structure, while the knowledge-augmented LLM is competitive on pairwise structure and attains the lowest pairwise error in separation anxiety and social anxiety. An ablation study shows that clinical retrieval reliably improves univariate and pairwise fidelity over a no-retrieval LLM. Privacy analyses indicate that the real data-free LLM yields modest overlaps and a low average linkage risk comparable to CTGAN, whereas TVAE exhibits extensive duplication despite a low k-map score. Overall, grounding an LLM in clinical knowledge enables high-quality, privacy-preserving synthetic psychiatric data when real datasets are unavailable or cannot be shared.
VideoHEDGE: Entropy-Based Hallucination Detection for Video-VLMs via Semantic Clustering and Spatiotemporal Perturbations
Jan 13, 2026Hallucinations in video-capable vision-language models (Video-VLMs) remain frequent and high-confidence, while existing uncertainty metrics often fail to align with correctness. We introduce VideoHEDGE, a modular framework for hallucination detection in video question answering that extends entropy-based reliability estimation from images to temporally structured inputs. Given a video-question pair, VideoHEDGE draws a baseline answer and multiple high-temperature generations from both clean clips and photometrically and spatiotemporally perturbed variants, then clusters the resulting textual outputs into semantic hypotheses using either Natural Language Inference (NLI)-based or embedding-based methods. Cluster-level probability masses yield three reliability scores: Semantic Entropy (SE), RadFlag, and Vision-Amplified Semantic Entropy (VASE). We evaluate VideoHEDGE on the SoccerChat benchmark using an LLM-as-a-judge to obtain binary hallucination labels. Across three 7B Video-VLMs (Qwen2-VL, Qwen2.5-VL, and a SoccerChat-finetuned model), VASE consistently achieves the highest ROC-AUC, especially at larger distortion budgets, while SE and RadFlag often operate near chance. We further show that embedding-based clustering matches NLI-based clustering in detection performance at substantially lower computational cost, and that domain fine-tuning reduces hallucination frequency but yields only modest improvements in calibration. The hedge-bench PyPI library enables reproducible and extensible benchmarking, with full code and experimental resources available at https://github.com/Simula/HEDGE#videohedge .
HEDGE: Hallucination Estimation via Dense Geometric Entropy for VQA with Vision-Language Models
Nov 16, 2025Vision-language models (VLMs) enable open-ended visual question answering but remain prone to hallucinations. We present HEDGE, a unified framework for hallucination detection that combines controlled visual perturbations, semantic clustering, and robust uncertainty metrics. HEDGE integrates sampling, distortion synthesis, clustering (entailment- and embedding-based), and metric computation into a reproducible pipeline applicable across multimodal architectures. Evaluations on VQA-RAD and KvasirVQA-x1 with three representative VLMs (LLaVA-Med, Med-Gemma, Qwen2.5-VL) reveal clear architecture- and prompt-dependent trends. Hallucination detectability is highest for unified-fusion models with dense visual tokenization (Qwen2.5-VL) and lowest for architectures with restricted tokenization (Med-Gemma). Embedding-based clustering often yields stronger separation when applied directly to the generated answers, whereas NLI-based clustering remains advantageous for LLaVA-Med and for longer, sentence-level responses. Across configurations, the VASE metric consistently provides the most robust hallucination signal, especially when paired with embedding clustering and a moderate sampling budget (n ~ 10-15). Prompt design also matters: concise, label-style outputs offer clearer semantic structure than syntactically constrained one-sentence responses. By framing hallucination detection as a geometric robustness problem shaped jointly by sampling scale, prompt structure, model architecture, and clustering strategy, HEDGE provides a principled, compute-aware foundation for evaluating multimodal reliability. The hedge-bench PyPI library enables reproducible and extensible benchmarking, with full code and experimental resources available at https://github.com/Simula/HEDGE .
Kvasir-VQA-x1: A Multimodal Dataset for Medical Reasoning and Robust MedVQA in Gastrointestinal Endoscopy
Jun 11, 2025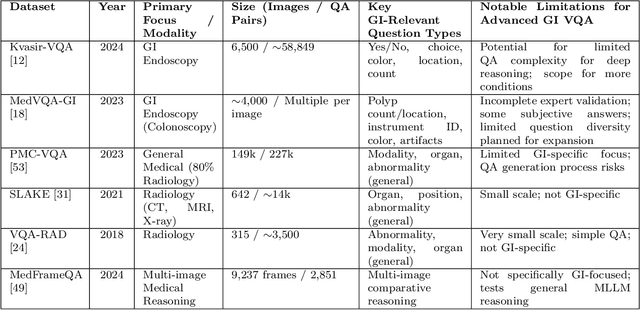
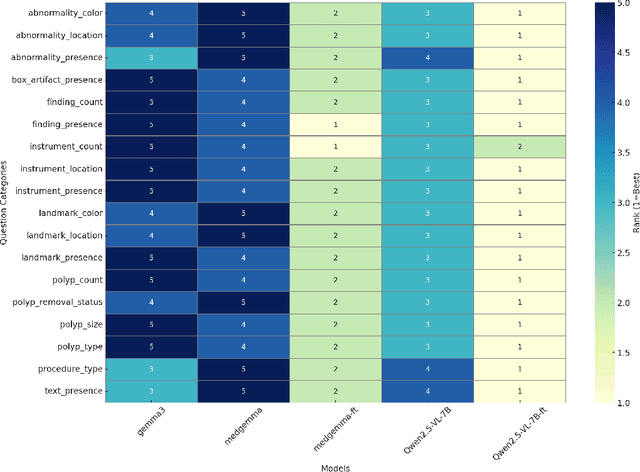
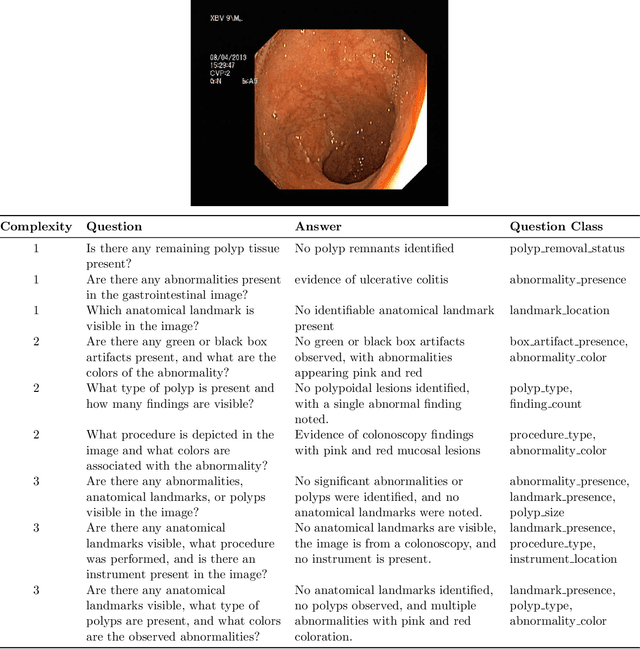
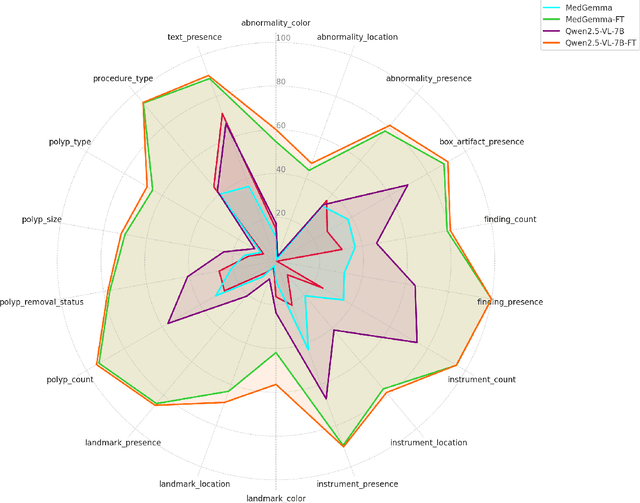
Medical Visual Question Answering (MedVQA) is a promising field for developing clinical decision support systems, yet progress is often limited by the available datasets, which can lack clinical complexity and visual diversity. To address these gaps, we introduce Kvasir-VQA-x1, a new, large-scale dataset for gastrointestinal (GI) endoscopy. Our work significantly expands upon the original Kvasir-VQA by incorporating 159,549 new question-answer pairs that are designed to test deeper clinical reasoning. We developed a systematic method using large language models to generate these questions, which are stratified by complexity to better assess a model's inference capabilities. To ensure our dataset prepares models for real-world clinical scenarios, we have also introduced a variety of visual augmentations that mimic common imaging artifacts. The dataset is structured to support two main evaluation tracks: one for standard VQA performance and another to test model robustness against these visual perturbations. By providing a more challenging and clinically relevant benchmark, Kvasir-VQA-x1 aims to accelerate the development of more reliable and effective multimodal AI systems for use in clinical settings. The dataset is fully accessible and adheres to FAIR data principles, making it a valuable resource for the wider research community. Code and data: https://github.com/Simula/Kvasir-VQA-x1 and https://huggingface.co/datasets/SimulaMet/Kvasir-VQA-x1
SoccerChat: Integrating Multimodal Data for Enhanced Soccer Game Understanding
May 22, 2025The integration of artificial intelligence in sports analytics has transformed soccer video understanding, enabling real-time, automated insights into complex game dynamics. Traditional approaches rely on isolated data streams, limiting their effectiveness in capturing the full context of a match. To address this, we introduce SoccerChat, a multimodal conversational AI framework that integrates visual and textual data for enhanced soccer video comprehension. Leveraging the extensive SoccerNet dataset, enriched with jersey color annotations and automatic speech recognition (ASR) transcripts, SoccerChat is fine-tuned on a structured video instruction dataset to facilitate accurate game understanding, event classification, and referee decision making. We benchmark SoccerChat on action classification and referee decision-making tasks, demonstrating its performance in general soccer event comprehension while maintaining competitive accuracy in referee decision making. Our findings highlight the importance of multimodal integration in advancing soccer analytics, paving the way for more interactive and explainable AI-driven sports analysis. https://github.com/simula/SoccerChat
Point, Detect, Count: Multi-Task Medical Image Understanding with Instruction-Tuned Vision-Language Models
May 22, 2025We investigate fine-tuning Vision-Language Models (VLMs) for multi-task medical image understanding, focusing on detection, localization, and counting of findings in medical images. Our objective is to evaluate whether instruction-tuned VLMs can simultaneously improve these tasks, with the goal of enhancing diagnostic accuracy and efficiency. Using MedMultiPoints, a multimodal dataset with annotations from endoscopy (polyps and instruments) and microscopy (sperm cells), we reformulate each task into instruction-based prompts suitable for vision-language reasoning. We fine-tune Qwen2.5-VL-7B-Instruct using Low-Rank Adaptation (LoRA) across multiple task combinations. Results show that multi-task training improves robustness and accuracy. For example, it reduces the Count Mean Absolute Error (MAE) and increases Matching Accuracy in the Counting + Pointing task. However, trade-offs emerge, such as more zero-case point predictions, indicating reduced reliability in edge cases despite overall performance gains. Our study highlights the potential of adapting general-purpose VLMs to specialized medical tasks via prompt-driven fine-tuning. This approach mirrors clinical workflows, where radiologists simultaneously localize, count, and describe findings - demonstrating how VLMs can learn composite diagnostic reasoning patterns. The model produces interpretable, structured outputs, offering a promising step toward explainable and versatile medical AI. Code, model weights, and scripts will be released for reproducibility at https://github.com/simula/PointDetectCount.
Prompt to Polyp: Medical Text-Conditioned Image Synthesis with Diffusion Models
May 12, 2025The generation of realistic medical images from text descriptions has significant potential to address data scarcity challenges in healthcare AI while preserving patient privacy. This paper presents a comprehensive study of text-to-image synthesis in the medical domain, comparing two distinct approaches: (1) fine-tuning large pre-trained latent diffusion models and (2) training small, domain-specific models. We introduce a novel model named MSDM, an optimized architecture based on Stable Diffusion that integrates a clinical text encoder, variational autoencoder, and cross-attention mechanisms to better align medical text prompts with generated images. Our study compares two approaches: fine-tuning large pre-trained models (FLUX, Kandinsky) versus training compact domain-specific models (MSDM). Evaluation across colonoscopy (MedVQA-GI) and radiology (ROCOv2) datasets reveals that while large models achieve higher fidelity, our optimized MSDM delivers comparable quality with lower computational costs. Quantitative metrics and qualitative evaluations by medical experts reveal strengths and limitations of each approach.
Prompt to Polyp: Clinically-Aware Medical Image Synthesis with Diffusion Models
May 08, 2025The generation of realistic medical images from text descriptions has significant potential to address data scarcity challenges in healthcare AI while preserving patient privacy. This paper presents a comprehensive study of text-to-image synthesis in the medical domain, comparing two distinct approaches: (1) fine-tuning large pre-trained latent diffusion models and (2) training small, domain-specific models. We introduce a novel model named MSDM, an optimized architecture based on Stable Diffusion that integrates a clinical text encoder, variational autoencoder, and cross-attention mechanisms to better align medical text prompts with generated images. Our study compares two approaches: fine-tuning large pre-trained models (FLUX, Kandinsky) versus training compact domain-specific models (MSDM). Evaluation across colonoscopy (MedVQA-GI) and radiology (ROCOv2) datasets reveals that while large models achieve higher fidelity, our optimized MSDM delivers comparable quality with lower computational costs. Quantitative metrics and qualitative evaluations by medical experts reveal strengths and limitations of each approach.
X-DECODE: EXtreme Deblurring with Curriculum Optimization and Domain Equalization
Apr 10, 2025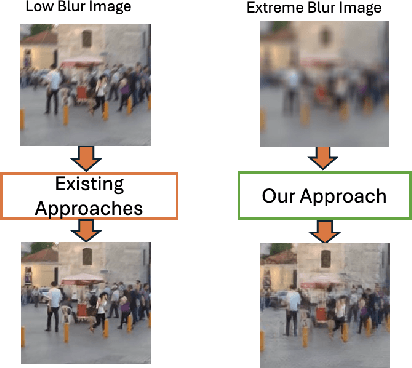
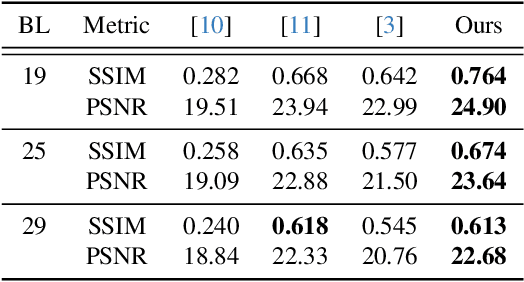
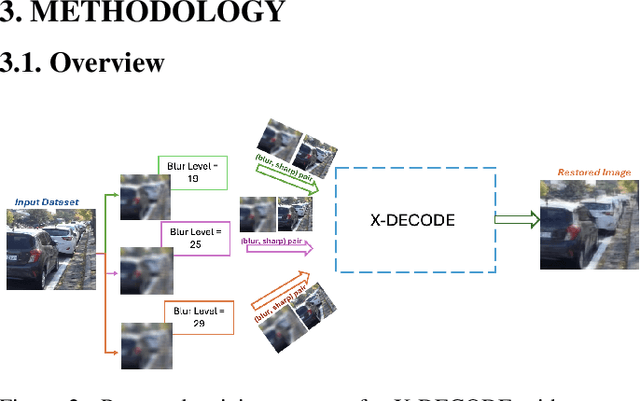
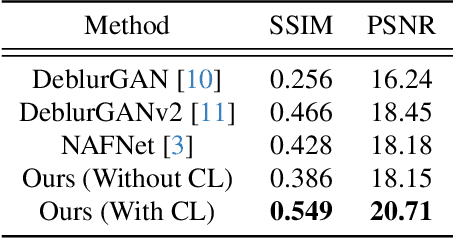
Restoring severely blurred images remains a significant challenge in computer vision, impacting applications in autonomous driving, medical imaging, and photography. This paper introduces a novel training strategy based on curriculum learning to improve the robustness of deep learning models for extreme image deblurring. Unlike conventional approaches that train on only low to moderate blur levels, our method progressively increases the difficulty by introducing images with higher blur severity over time, allowing the model to adapt incrementally. Additionally, we integrate perceptual and hinge loss during training to enhance fine detail restoration and improve training stability. We experimented with various curriculum learning strategies and explored the impact of the train-test domain gap on the deblurring performance. Experimental results on the Extreme-GoPro dataset showed that our method outperforms the next best method by 14% in SSIM, whereas experiments on the Extreme-KITTI dataset showed that our method outperforms the next best by 18% in SSIM. Ablation studies showed that a linear curriculum progression outperforms step-wise, sigmoid, and exponential progressions, while hyperparameter settings such as the training blur percentage and loss function formulation all play important roles in addressing extreme blur artifacts. Datasets and code are available at https://github.com/RAPTOR-MSSTATE/XDECODE