 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTime-to-Injury Forecasting in Elite Female Football: A DeepHit Survival Approach
Jan 27, 2026Injury occurrence in football poses significant challenges for athletes and teams, carrying personal, competitive, and financial consequences. While machine learning has been applied to injury prediction before, existing approaches often rely on static pre-season data and binary outcomes, limiting their real-world utility. This study investigates the feasibility of using a DeepHit neural network to forecast time-to-injury from longitudinal athlete monitoring data, while providing interpretable predictions. The analysis utilised the publicly available SoccerMon dataset, containing two seasons of training, match, and wellness records from elite female footballers. Data was pre-processed through cleaning, feature engineering, and the application of three imputation strategies. Baseline models (Random Forest, XGBoost, Logistic Regression) were optimised via grid search for benchmarking, while the DeepHit model, implemented with a multilayer perceptron backbone, was evaluated using chronological and leave-one-player-out (LOPO) validation. DeepHit achieved a concordance index of 0.762, outperforming baseline models and delivering individualised, time-varying risk estimates. Shapley Additive Explanations (SHAP) identified clinically relevant predictors consistent with established risk factors, enhancing interpretability. Overall, this study provides a novel proof of concept: survival modelling with DeepHit shows strong potential to advance injury forecasting in football, offering accurate, explainable, and actionable insights for injury prevention across competitive levels.
VideoHEDGE: Entropy-Based Hallucination Detection for Video-VLMs via Semantic Clustering and Spatiotemporal Perturbations
Jan 13, 2026Hallucinations in video-capable vision-language models (Video-VLMs) remain frequent and high-confidence, while existing uncertainty metrics often fail to align with correctness. We introduce VideoHEDGE, a modular framework for hallucination detection in video question answering that extends entropy-based reliability estimation from images to temporally structured inputs. Given a video-question pair, VideoHEDGE draws a baseline answer and multiple high-temperature generations from both clean clips and photometrically and spatiotemporally perturbed variants, then clusters the resulting textual outputs into semantic hypotheses using either Natural Language Inference (NLI)-based or embedding-based methods. Cluster-level probability masses yield three reliability scores: Semantic Entropy (SE), RadFlag, and Vision-Amplified Semantic Entropy (VASE). We evaluate VideoHEDGE on the SoccerChat benchmark using an LLM-as-a-judge to obtain binary hallucination labels. Across three 7B Video-VLMs (Qwen2-VL, Qwen2.5-VL, and a SoccerChat-finetuned model), VASE consistently achieves the highest ROC-AUC, especially at larger distortion budgets, while SE and RadFlag often operate near chance. We further show that embedding-based clustering matches NLI-based clustering in detection performance at substantially lower computational cost, and that domain fine-tuning reduces hallucination frequency but yields only modest improvements in calibration. The hedge-bench PyPI library enables reproducible and extensible benchmarking, with full code and experimental resources available at https://github.com/Simula/HEDGE#videohedge .
ExposureEngine: Oriented Logo Detection and Sponsor Visibility Analytics in Sports Broadcasts
Oct 06, 2025Quantifying sponsor visibility in sports broadcasts is a critical marketing task traditionally hindered by manual, subjective, and unscalable analysis methods. While automated systems offer an alternative, their reliance on axis-aligned Horizontal Bounding Box (HBB) leads to inaccurate exposuremetrics when logos appear rotated or skewed due to dynamic camera angles and perspective distortions. This paper introduces ExposureEngine, an end-to-end system designed for accurate, rotation-aware sponsor visibility analytics in sports broadcasts, demonstrated in a soccer case study. Our approach predicts Oriented Bounding Box (OBB) to provide a geometrically precise fit to each logo regardless of the orientation on-screen. To train and evaluate our detector, we developed a new dataset comprising 1,103 frames from Swedish elite soccer, featuring 670 unique sponsor logos annotated with OBBs. Our model achieves a mean Average Precision (mAP@0.5) of 0.859, with a precision of 0.96 and recall of 0.87, demonstrating robust performance in localizing logos under diverse broadcast conditions. The system integrates these detections into an analytical pipeline that calculates precise visibility metrics, such as exposure duration and on-screen coverage. Furthermore, we incorporate a language-driven agentic layer, enabling users to generate reports, summaries, and media content through natural language queries. The complete system, including the dataset and the analytics dashboard, provides a comprehensive solution for auditable and interpretable sponsor measurement in sports media. An overview of the ExposureEngine is available online: https://youtu.be/tRw6OBISuW4 .
SoccerChat: Integrating Multimodal Data for Enhanced Soccer Game Understanding
May 22, 2025The integration of artificial intelligence in sports analytics has transformed soccer video understanding, enabling real-time, automated insights into complex game dynamics. Traditional approaches rely on isolated data streams, limiting their effectiveness in capturing the full context of a match. To address this, we introduce SoccerChat, a multimodal conversational AI framework that integrates visual and textual data for enhanced soccer video comprehension. Leveraging the extensive SoccerNet dataset, enriched with jersey color annotations and automatic speech recognition (ASR) transcripts, SoccerChat is fine-tuned on a structured video instruction dataset to facilitate accurate game understanding, event classification, and referee decision making. We benchmark SoccerChat on action classification and referee decision-making tasks, demonstrating its performance in general soccer event comprehension while maintaining competitive accuracy in referee decision making. Our findings highlight the importance of multimodal integration in advancing soccer analytics, paving the way for more interactive and explainable AI-driven sports analysis. https://github.com/simula/SoccerChat
Enhancing Structured-Data Retrieval with GraphRAG: Soccer Data Case Study
Sep 26, 2024



Extracting meaningful insights from large and complex datasets poses significant challenges, particularly in ensuring the accuracy and relevance of retrieved information. Traditional data retrieval methods such as sequential search and index-based retrieval often fail when handling intricate and interconnected data structures, resulting in incomplete or misleading outputs. To overcome these limitations, we introduce Structured-GraphRAG, a versatile framework designed to enhance information retrieval across structured datasets in natural language queries. Structured-GraphRAG utilizes multiple knowledge graphs, which represent data in a structured format and capture complex relationships between entities, enabling a more nuanced and comprehensive retrieval of information. This graph-based approach reduces the risk of errors in language model outputs by grounding responses in a structured format, thereby enhancing the reliability of results. We demonstrate the effectiveness of Structured-GraphRAG by comparing its performance with that of a recently published method using traditional retrieval-augmented generation. Our findings show that Structured-GraphRAG significantly improves query processing efficiency and reduces response times. While our case study focuses on soccer data, the framework's design is broadly applicable, offering a powerful tool for data analysis and enhancing language model applications across various structured domains.
Kvasir-VQA: A Text-Image Pair GI Tract Dataset
Sep 02, 2024



We introduce Kvasir-VQA, an extended dataset derived from the HyperKvasir and Kvasir-Instrument datasets, augmented with question-and-answer annotations to facilitate advanced machine learning tasks in Gastrointestinal (GI) diagnostics. This dataset comprises 6,500 annotated images spanning various GI tract conditions and surgical instruments, and it supports multiple question types including yes/no, choice, location, and numerical count. The dataset is intended for applications such as image captioning, Visual Question Answering (VQA), text-based generation of synthetic medical images, object detection, and classification. Our experiments demonstrate the dataset's effectiveness in training models for three selected tasks, showcasing significant applications in medical image analysis and diagnostics. We also present evaluation metrics for each task, highlighting the usability and versatility of our dataset. The dataset and supporting artifacts are available at https://datasets.simula.no/kvasir-vqa.
PLayerTV: Advanced Player Tracking and Identification for Automatic Soccer Highlight Clips
Jul 22, 2024



In the rapidly evolving field of sports analytics, the automation of targeted video processing is a pivotal advancement. We propose PlayerTV, an innovative framework which harnesses state-of-the-art AI technologies for automatic player tracking and identification in soccer videos. By integrating object detection and tracking, Optical Character Recognition (OCR), and color analysis, PlayerTV facilitates the generation of player-specific highlight clips from extensive game footage, significantly reducing the manual labor traditionally associated with such tasks. Preliminary results from the evaluation of our core pipeline, tested on a dataset from the Norwegian Eliteserien league, indicate that PlayerTV can accurately and efficiently identify teams and players, and our interactive Graphical User Interface (GUI) serves as a user-friendly application wrapping this functionality for streamlined use.
SoccerRAG: Multimodal Soccer Information Retrieval via Natural Queries
Jun 03, 2024



The rapid evolution of digital sports media necessitates sophisticated information retrieval systems that can efficiently parse extensive multimodal datasets. This paper introduces SoccerRAG, an innovative framework designed to harness the power of Retrieval Augmented Generation (RAG) and Large Language Models (LLMs) to extract soccer-related information through natural language queries. By leveraging a multimodal dataset, SoccerRAG supports dynamic querying and automatic data validation, enhancing user interaction and accessibility to sports archives. Our evaluations indicate that SoccerRAG effectively handles complex queries, offering significant improvements over traditional retrieval systems in terms of accuracy and user engagement. The results underscore the potential of using RAG and LLMs in sports analytics, paving the way for future advancements in the accessibility and real-time processing of sports data.
Demo: Soccer Information Retrieval via Natural Queries using SoccerRAG
Jun 03, 2024

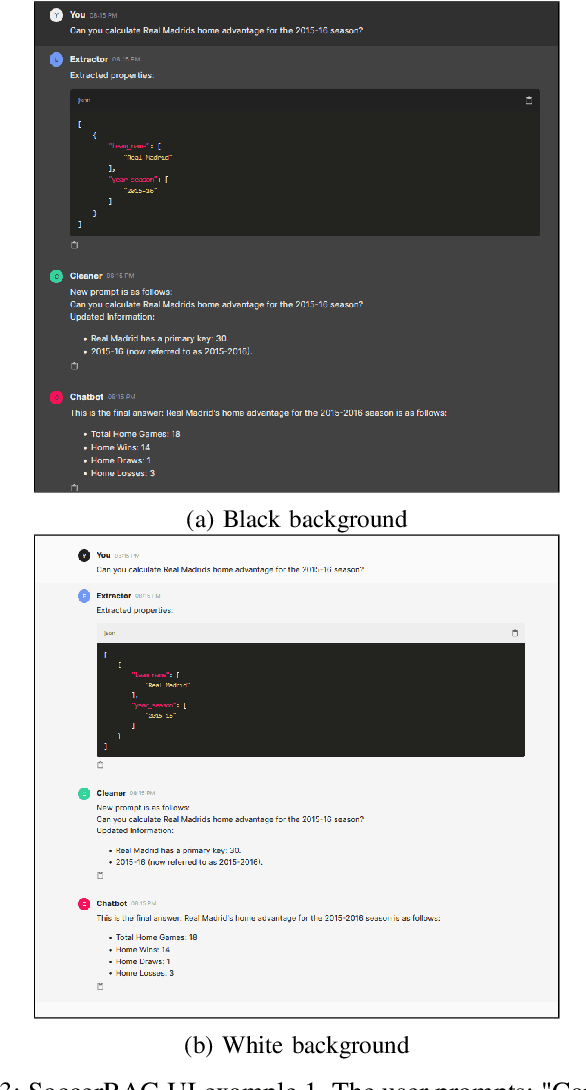

The rapid evolution of digital sports media necessitates sophisticated information retrieval systems that can efficiently parse extensive multimodal datasets. This paper demonstrates SoccerRAG, an innovative framework designed to harness the power of Retrieval Augmented Generation (RAG) and Large Language Models (LLMs) to extract soccer-related information through natural language queries. By leveraging a multimodal dataset, SoccerRAG supports dynamic querying and automatic data validation, enhancing user interaction and accessibility to sports archives. We present a novel interactive user interface (UI) based on the Chainlit framework which wraps around the core functionality, and enable users to interact with the SoccerRAG framework in a chatbot-like visual manner.
SoccerNet-Echoes: A Soccer Game Audio Commentary Dataset
May 12, 2024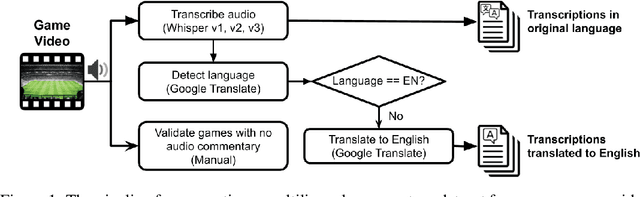


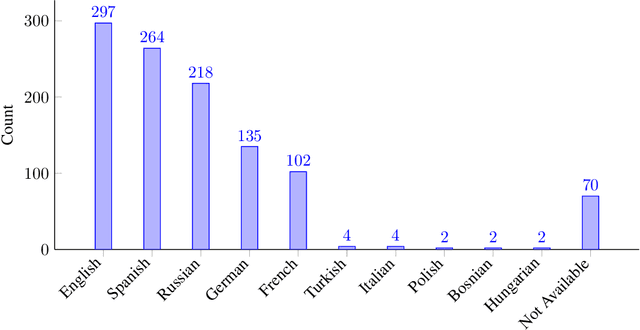
The application of Automatic Speech Recognition (ASR) technology in soccer offers numerous opportunities for sports analytics. Specifically, extracting audio commentaries with ASR provides valuable insights into the events of the game, and opens the door to several downstream applications such as automatic highlight generation. This paper presents SoccerNet-Echoes, an augmentation of the SoccerNet dataset with automatically generated transcriptions of audio commentaries from soccer game broadcasts, enhancing video content with rich layers of textual information derived from the game audio using ASR. These textual commentaries, generated using the Whisper model and translated with Google Translate, extend the usefulness of the SoccerNet dataset in diverse applications such as enhanced action spotting, automatic caption generation, and game summarization. By incorporating textual data alongside visual and auditory content, SoccerNet-Echoes aims to serve as a comprehensive resource for the development of algorithms specialized in capturing the dynamics of soccer games. We detail the methods involved in the curation of this dataset and the integration of ASR. We also highlight the implications of a multimodal approach in sports analytics, and how the enriched dataset can support diverse applications, thus broadening the scope of research and development in the field of sports analytics.