 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKnowledge-Guided Retrieval-Augmented Generation for Zero-Shot Psychiatric Data: Privacy Preserving Synthetic Data Generation
Mar 26, 2026AI systems in healthcare research have shown potential to increase patient throughput and assist clinicians, yet progress is constrained by limited access to real patient data. To address this issue, we present a zero-shot, knowledge-guided framework for psychiatric tabular data in which large language models (LLMs) are steered via Retrieval-Augmented Generation using the Diagnostic and Statistical Manual of Mental Disorders (DSM-5) and the International Classification of Diseases (ICD-10). We conducted experiments using different combinations of knowledge bases to generate privacy-preserving synthetic data. The resulting models were benchmarked against two state-of-the-art deep learning models for synthetic tabular data generation, namely CTGAN and TVAE, both of which rely on real data and therefore entail potential privacy risks. Evaluation was performed on six anxiety-related disorders: specific phobia, social anxiety disorder, agoraphobia, generalized anxiety disorder, separation anxiety disorder, and panic disorder. CTGAN typically achieves the best marginals and multivariate structure, while the knowledge-augmented LLM is competitive on pairwise structure and attains the lowest pairwise error in separation anxiety and social anxiety. An ablation study shows that clinical retrieval reliably improves univariate and pairwise fidelity over a no-retrieval LLM. Privacy analyses indicate that the real data-free LLM yields modest overlaps and a low average linkage risk comparable to CTGAN, whereas TVAE exhibits extensive duplication despite a low k-map score. Overall, grounding an LLM in clinical knowledge enables high-quality, privacy-preserving synthetic psychiatric data when real datasets are unavailable or cannot be shared.
Synthetic Cardiac MRI Image Generation using Deep Generative Models
Mar 25, 2026Synthetic cardiac MRI (CMRI) generation has emerged as a promising strategy to overcome the scarcity of annotated medical imaging data. Recent advances in GANs, VAEs, diffusion probabilistic models, and flow-matching techniques aim to generate anatomically accurate images while addressing challenges such as limited labeled datasets, vendor variability, and risks of privacy leakage through model memorization. Maskconditioned generation improves structural fidelity by guiding synthesis with segmentation maps, while diffusion and flowmatching models offer strong boundary preservation and efficient deterministic transformations. Cross-domain generalization is further supported through vendor-style conditioning and preprocessing steps like intensity normalization. To ensure privacy, studies increasingly incorporate membership inference attacks, nearest-neighbor analyses, and differential privacy mechanisms. Utility evaluations commonly measure downstream segmentation performance, with evidence showing that anatomically constrained synthetic data can enhance accuracy and robustness across multi-vendor settings. This review aims to compare existing CMRI generation approaches through the lenses of fidelity, utility, and privacy, highlighting current limitations and the need for integrated, evaluation-driven frameworks for reliable clinical workflows.
Balancing Fidelity, Utility, and Privacy in Synthetic Cardiac MRI Generation: A Comparative Study
Mar 04, 2026Deep learning in cardiac MRI (CMR) is fundamentally constrained by both data scarcity and privacy regulations. This study systematically benchmarks three generative architectures: Denoising Diffusion Probabilistic Models (DDPM), Latent Diffusion Models (LDM), and Flow Matching (FM) for synthetic CMR generation. Utilizing a two-stage pipeline where anatomical masks condition image synthesis, we evaluate generated data across three critical axes: fidelity, utility, and privacy. Our results show that diffusion-based models, particularly DDPM, provide the most effective balance between downstream segmentation utility, image fidelity, and privacy preservation under limited-data conditions, while FM demonstrates promising privacy characteristics with slightly lower task-level performance. These findings quantify the trade-offs between cross-domain generalization and patient confidentiality, establishing a framework for safe and effective synthetic data augmentation in medical imaging.
Calliope: A TTS-based Narrated E-book Creator Ensuring Exact Synchronization, Privacy, and Layout Fidelity
Feb 11, 2026A narrated e-book combines synchronized audio with digital text, highlighting the currently spoken word or sentence during playback. This format supports early literacy and assists individuals with reading challenges, while also allowing general readers to seamlessly switch between reading and listening. With the emergence of natural-sounding neural Text-to-Speech (TTS) technology, several commercial services have been developed to leverage these technology for converting standard text e-books into high-quality narrated e-books. However, no open-source solutions currently exist to perform this task. In this paper, we present Calliope, an open-source framework designed to fill this gap. Our method leverages state-of-the-art open-source TTS to convert a text e-book into a narrated e-book in the EPUB 3 Media Overlay format. The method offers several innovative steps: audio timestamps are captured directly during TTS, ensuring exact synchronization between narration and text highlighting; the publisher's original typography, styling, and embedded media are strictly preserved; and the entire pipeline operates offline. This offline capability eliminates recurring API costs, mitigates privacy concerns, and avoids copyright compliance issues associated with cloud-based services. The framework currently supports the state-of-the-art open-source TTS systems XTTS-v2 and Chatterbox. A potential alternative approach involves first generating narration via TTS and subsequently synchronizing it with the text using forced alignment. However, while our method ensures exact synchronization, our experiments show that forced alignment introduces drift between the audio and text highlighting significant enough to degrade the reading experience. Source code and usage instructions are available at https://github.com/hugohammer/TTS-Narrated-Ebook-Creator.git.
Anatomy-Preserving Latent Diffusion for Generation of Brain Segmentation Masks with Ischemic Infarct
Feb 10, 2026The scarcity of high-quality segmentation masks remains a major bottleneck for medical image analysis, particularly in non-contrast CT (NCCT) neuroimaging, where manual annotation is costly and variable. To address this limitation, we propose an anatomy-preserving generative framework for the unconditional synthesis of multi-class brain segmentation masks, including ischemic infarcts. The proposed approach combines a variational autoencoder trained exclusively on segmentation masks to learn an anatomical latent representation, with a diffusion model operating in this latent space to generate new samples from pure noise. At inference, synthetic masks are obtained by decoding denoised latent vectors through the frozen VAE decoder, with optional coarse control over lesion presence via a binary prompt. Qualitative results show that the generated masks preserve global brain anatomy, discrete tissue semantics, and realistic variability, while avoiding the structural artifacts commonly observed in pixel-space generative models. Overall, the proposed framework offers a simple and scalable solution for anatomy-aware mask generation in data-scarce medical imaging scenarios.
ECG-IMN: Interpretable Mesomorphic Neural Networks for 12-Lead Electrocardiogram Interpretation
Feb 10, 2026Deep learning has achieved expert-level performance in automated electrocardiogram (ECG) diagnosis, yet the "black-box" nature of these models hinders their clinical deployment. Trust in medical AI requires not just high accuracy but also transparency regarding the specific physiological features driving predictions. Existing explainability methods for ECGs typically rely on post-hoc approximations (e.g., Grad-CAM and SHAP), which can be unstable, computationally expensive, and unfaithful to the model's actual decision-making process. In this work, we propose the ECG-IMN, an Interpretable Mesomorphic Neural Network tailored for high-resolution 12-lead ECG classification. Unlike standard classifiers, the ECG-IMN functions as a hypernetwork: a deep convolutional backbone generates the parameters of a strictly linear model specific to each input sample. This architecture enforces intrinsic interpretability, as the decision logic is mathematically transparent and the generated weights (W) serve as exact, high-resolution feature attribution maps. We introduce a transition decoder that effectively maps latent features to sample-wise weights, enabling precise localization of pathological evidence (e.g., ST-elevation, T-wave inversion) in both time and lead dimensions. We evaluate our approach on the PTB-XL dataset for classification tasks, demonstrating that the ECG-IMN achieves competitive predictive performance (AUROC comparable to black-box baselines) while providing faithful, instance-specific explanations. By explicitly decoupling parameter generation from prediction execution, our framework bridges the gap between deep learning capability and clinical trustworthiness, offering a principled path toward "white-box" cardiac diagnostics.
VideoHEDGE: Entropy-Based Hallucination Detection for Video-VLMs via Semantic Clustering and Spatiotemporal Perturbations
Jan 13, 2026Hallucinations in video-capable vision-language models (Video-VLMs) remain frequent and high-confidence, while existing uncertainty metrics often fail to align with correctness. We introduce VideoHEDGE, a modular framework for hallucination detection in video question answering that extends entropy-based reliability estimation from images to temporally structured inputs. Given a video-question pair, VideoHEDGE draws a baseline answer and multiple high-temperature generations from both clean clips and photometrically and spatiotemporally perturbed variants, then clusters the resulting textual outputs into semantic hypotheses using either Natural Language Inference (NLI)-based or embedding-based methods. Cluster-level probability masses yield three reliability scores: Semantic Entropy (SE), RadFlag, and Vision-Amplified Semantic Entropy (VASE). We evaluate VideoHEDGE on the SoccerChat benchmark using an LLM-as-a-judge to obtain binary hallucination labels. Across three 7B Video-VLMs (Qwen2-VL, Qwen2.5-VL, and a SoccerChat-finetuned model), VASE consistently achieves the highest ROC-AUC, especially at larger distortion budgets, while SE and RadFlag often operate near chance. We further show that embedding-based clustering matches NLI-based clustering in detection performance at substantially lower computational cost, and that domain fine-tuning reduces hallucination frequency but yields only modest improvements in calibration. The hedge-bench PyPI library enables reproducible and extensible benchmarking, with full code and experimental resources available at https://github.com/Simula/HEDGE#videohedge .
Medical Imaging AI Competitions Lack Fairness
Dec 19, 2025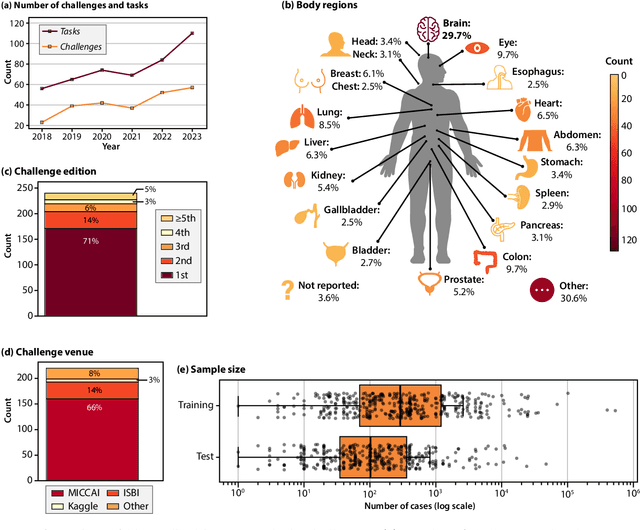
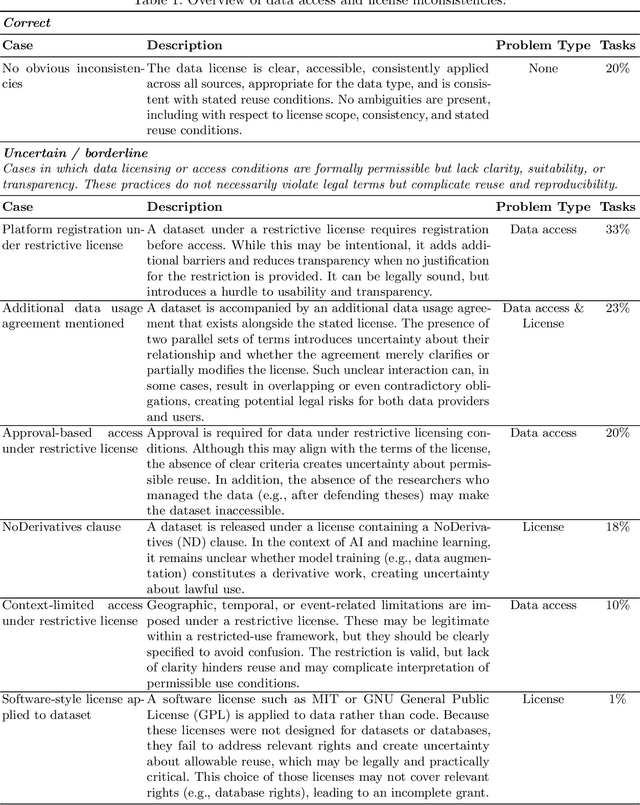
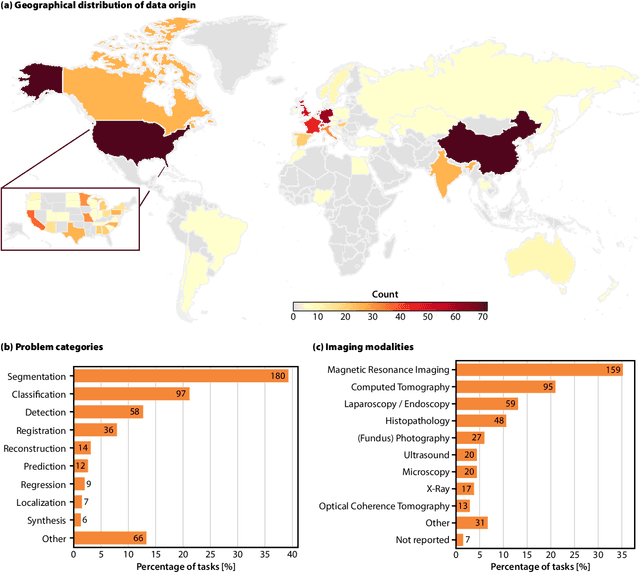
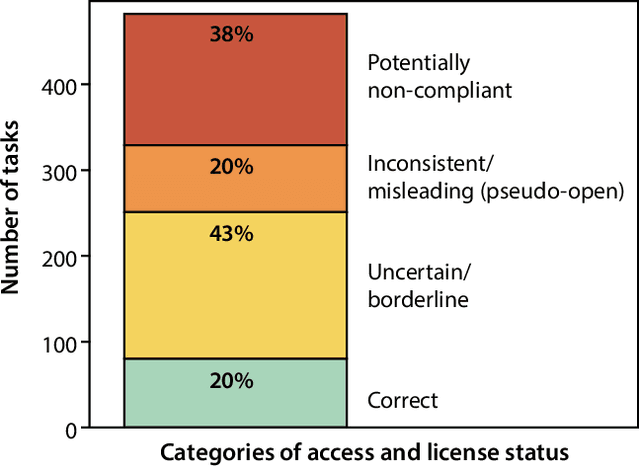
Benchmarking competitions are central to the development of artificial intelligence (AI) in medical imaging, defining performance standards and shaping methodological progress. However, it remains unclear whether these benchmarks provide data that are sufficiently representative, accessible, and reusable to support clinically meaningful AI. In this work, we assess fairness along two complementary dimensions: (1) whether challenge datasets are representative of real-world clinical diversity, and (2) whether they are accessible and legally reusable in line with the FAIR principles. To address this question, we conducted a large-scale systematic study of 241 biomedical image analysis challenges comprising 458 tasks across 19 imaging modalities. Our findings show substantial biases in dataset composition, including geographic location, modality-, and problem type-related biases, indicating that current benchmarks do not adequately reflect real-world clinical diversity. Despite their widespread influence, challenge datasets were frequently constrained by restrictive or ambiguous access conditions, inconsistent or non-compliant licensing practices, and incomplete documentation, limiting reproducibility and long-term reuse. Together, these shortcomings expose foundational fairness limitations in our benchmarking ecosystem and highlight a disconnect between leaderboard success and clinical relevance.
From Flat to Feeling: A Feasibility and Impact Study on Dynamic Facial Emotions in AI-Generated Avatars
Jun 16, 2025
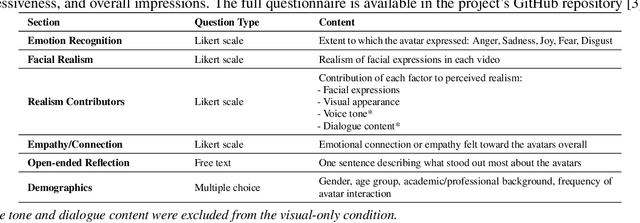
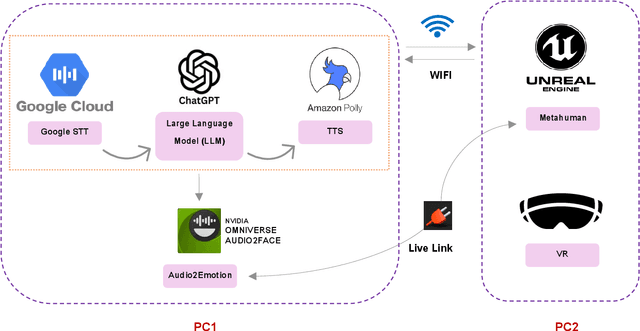

Dynamic facial emotion is essential for believable AI-generated avatars; however, most systems remain visually inert, limiting their utility in high-stakes simulations such as virtual training for investigative interviews with abused children. We introduce and evaluate a real-time architecture fusing Unreal Engine 5 MetaHuman rendering with NVIDIA Omniverse Audio2Face to translate vocal prosody into high-fidelity facial expressions on photorealistic child avatars. We implemented a distributed two-PC setup that decouples language processing and speech synthesis from GPU-intensive rendering, designed to support low-latency interaction in desktop and VR environments. A between-subjects study ($N=70$) using audio+visual and visual-only conditions assessed perceptual impacts as participants rated emotional clarity, facial realism, and empathy for two avatars expressing joy, sadness, and anger. Results demonstrate that avatars could express emotions recognizably, with sadness and joy achieving high identification rates. However, anger recognition significantly dropped without audio, highlighting the importance of congruent vocal cues for high-arousal emotions. Interestingly, removing audio boosted perceived facial realism, suggesting that audiovisual desynchrony remains a key design challenge. These findings confirm the technical feasibility of generating emotionally expressive avatars and provide guidance for improving non-verbal communication in sensitive training simulations.
SoccerChat: Integrating Multimodal Data for Enhanced Soccer Game Understanding
May 22, 2025The integration of artificial intelligence in sports analytics has transformed soccer video understanding, enabling real-time, automated insights into complex game dynamics. Traditional approaches rely on isolated data streams, limiting their effectiveness in capturing the full context of a match. To address this, we introduce SoccerChat, a multimodal conversational AI framework that integrates visual and textual data for enhanced soccer video comprehension. Leveraging the extensive SoccerNet dataset, enriched with jersey color annotations and automatic speech recognition (ASR) transcripts, SoccerChat is fine-tuned on a structured video instruction dataset to facilitate accurate game understanding, event classification, and referee decision making. We benchmark SoccerChat on action classification and referee decision-making tasks, demonstrating its performance in general soccer event comprehension while maintaining competitive accuracy in referee decision making. Our findings highlight the importance of multimodal integration in advancing soccer analytics, paving the way for more interactive and explainable AI-driven sports analysis. https://github.com/simula/SoccerChat