 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQBI: Quantile-based Bias Initialization for Efficient Private Data Reconstruction in Federated Learning
Jun 26, 2024



Federated learning enables the training of machine learning models on distributed data without compromising user privacy, as data remains on personal devices and only model updates, such as gradients, are shared with a central coordinator. However, recent research has shown that the central entity can perfectly reconstruct private data from shared model updates by maliciously initializing the model's parameters. In this paper, we propose QBI, a novel bias initialization method that significantly enhances reconstruction capabilities. This is accomplished by directly solving for bias values yielding sparse activation patterns. Further, we propose PAIRS, an algorithm that builds on QBI. PAIRS can be deployed when a separate dataset from the target domain is available to further increase the percentage of data that can be fully recovered. Measured by the percentage of samples that can be perfectly reconstructed from batches of various sizes, our approach achieves significant improvements over previous methods with gains of up to 50% on ImageNet and up to 60% on the IMDB sentiment analysis text dataset. Furthermore, we establish theoretical limits for attacks leveraging stochastic gradient sparsity, providing a foundation for understanding the fundamental constraints of these attacks. We empirically assess these limits using synthetic datasets. Finally, we propose and evaluate AGGP, a defensive framework designed to prevent gradient sparsity attacks, contributing to the development of more secure and private federated learning systems.
An objective validation of polyp and instrument segmentation methods in colonoscopy through Medico 2020 polyp segmentation and MedAI 2021 transparency challenges
Jul 30, 2023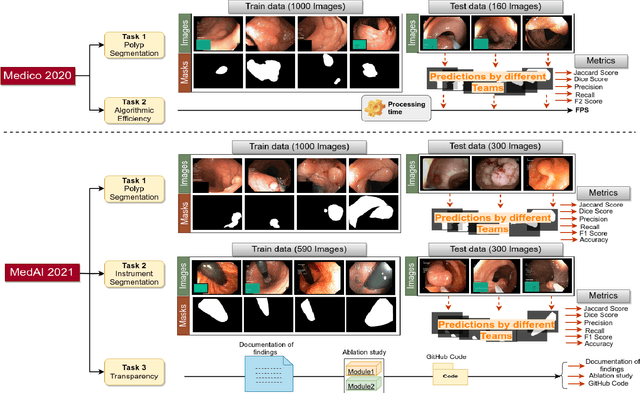
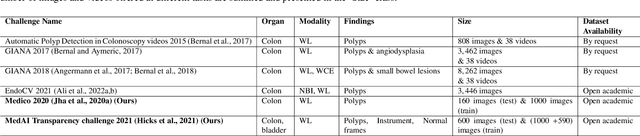
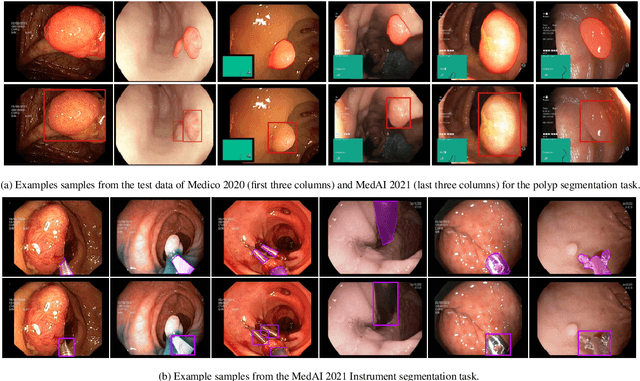
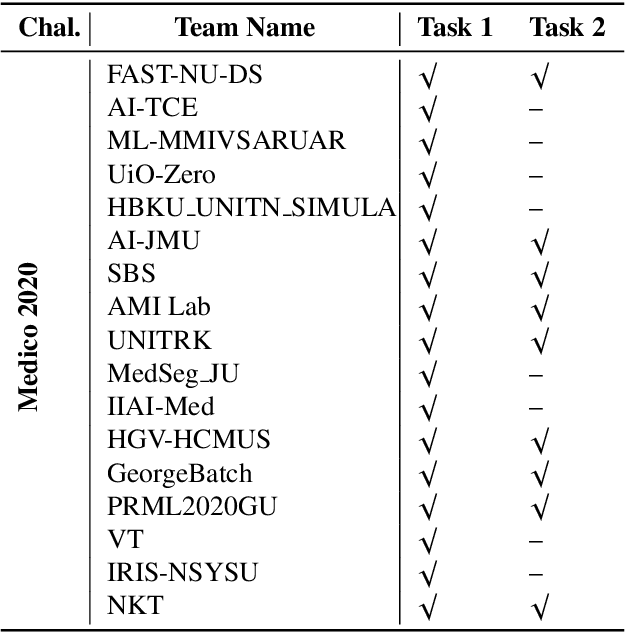
Automatic analysis of colonoscopy images has been an active field of research motivated by the importance of early detection of precancerous polyps. However, detecting polyps during the live examination can be challenging due to various factors such as variation of skills and experience among the endoscopists, lack of attentiveness, and fatigue leading to a high polyp miss-rate. Deep learning has emerged as a promising solution to this challenge as it can assist endoscopists in detecting and classifying overlooked polyps and abnormalities in real time. In addition to the algorithm's accuracy, transparency and interpretability are crucial to explaining the whys and hows of the algorithm's prediction. Further, most algorithms are developed in private data, closed source, or proprietary software, and methods lack reproducibility. Therefore, to promote the development of efficient and transparent methods, we have organized the "Medico automatic polyp segmentation (Medico 2020)" and "MedAI: Transparency in Medical Image Segmentation (MedAI 2021)" competitions. We present a comprehensive summary and analyze each contribution, highlight the strength of the best-performing methods, and discuss the possibility of clinical translations of such methods into the clinic. For the transparency task, a multi-disciplinary team, including expert gastroenterologists, accessed each submission and evaluated the team based on open-source practices, failure case analysis, ablation studies, usability and understandability of evaluations to gain a deeper understanding of the models' credibility for clinical deployment. Through the comprehensive analysis of the challenge, we not only highlight the advancements in polyp and surgical instrument segmentation but also encourage qualitative evaluation for building more transparent and understandable AI-based colonoscopy systems.
Biomedical image analysis competitions: The state of current participation practice
Dec 16, 2022The number of international benchmarking competitions is steadily increasing in various fields of machine learning (ML) research and practice. So far, however, little is known about the common practice as well as bottlenecks faced by the community in tackling the research questions posed. To shed light on the status quo of algorithm development in the specific field of biomedical imaging analysis, we designed an international survey that was issued to all participants of challenges conducted in conjunction with the IEEE ISBI 2021 and MICCAI 2021 conferences (80 competitions in total). The survey covered participants' expertise and working environments, their chosen strategies, as well as algorithm characteristics. A median of 72% challenge participants took part in the survey. According to our results, knowledge exchange was the primary incentive (70%) for participation, while the reception of prize money played only a minor role (16%). While a median of 80 working hours was spent on method development, a large portion of participants stated that they did not have enough time for method development (32%). 25% perceived the infrastructure to be a bottleneck. Overall, 94% of all solutions were deep learning-based. Of these, 84% were based on standard architectures. 43% of the respondents reported that the data samples (e.g., images) were too large to be processed at once. This was most commonly addressed by patch-based training (69%), downsampling (37%), and solving 3D analysis tasks as a series of 2D tasks. K-fold cross-validation on the training set was performed by only 37% of the participants and only 50% of the participants performed ensembling based on multiple identical models (61%) or heterogeneous models (39%). 48% of the respondents applied postprocessing steps.
A translational pathway of deep learning methods in GastroIntestinal Endoscopy
Oct 12, 2020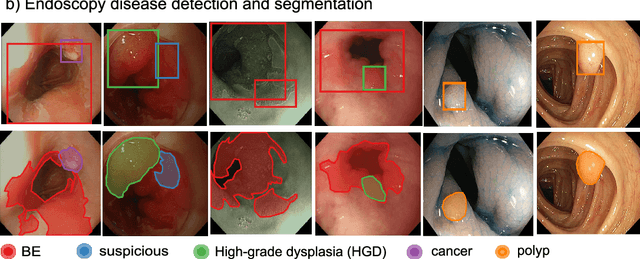
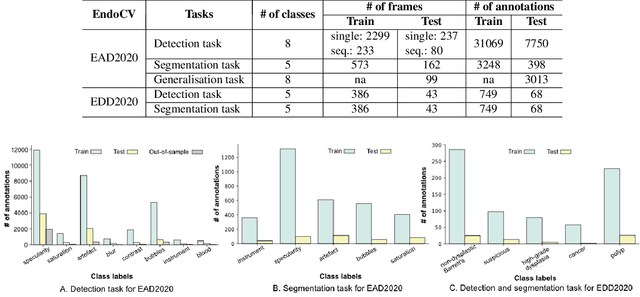
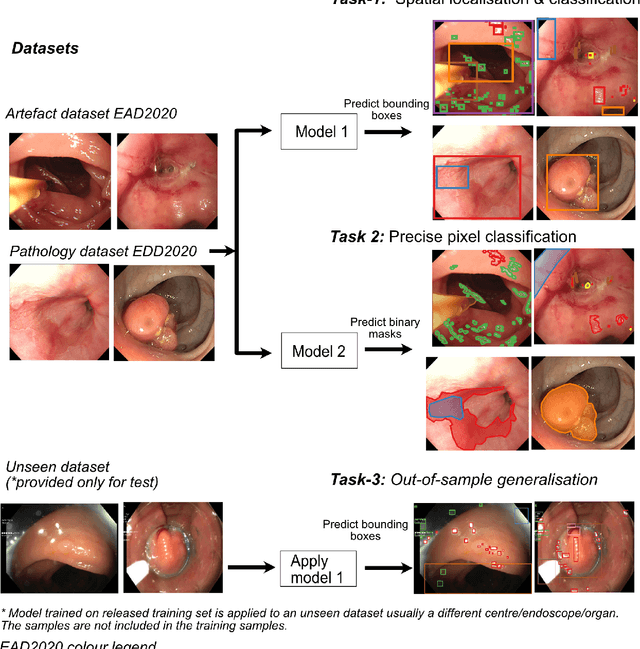
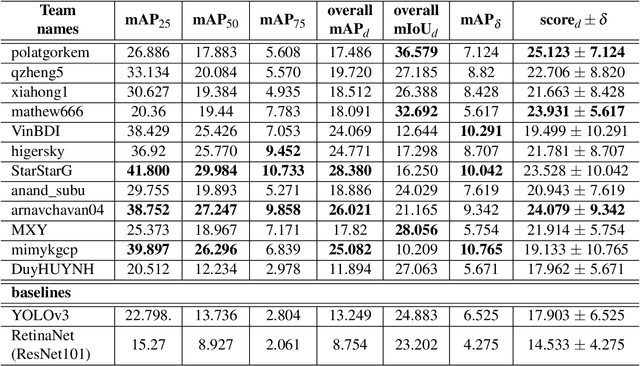
The Endoscopy Computer Vision Challenge (EndoCV) is a crowd-sourcing initiative to address eminent problems in developing reliable computer aided detection and diagnosis endoscopy systems and suggest a pathway for clinical translation of technologies. Whilst endoscopy is a widely used diagnostic and treatment tool for hollow-organs, there are several core challenges often faced by endoscopists, mainly: 1) presence of multi-class artefacts that hinder their visual interpretation, and 2) difficulty in identifying subtle precancerous precursors and cancer abnormalities. Artefacts often affect the robustness of deep learning methods applied to the gastrointestinal tract organs as they can be confused with tissue of interest. EndoCV2020 challenges are designed to address research questions in these remits. In this paper, we present a summary of methods developed by the top 17 teams and provide an objective comparison of state-of-the-art methods and methods designed by the participants for two sub-challenges: i) artefact detection and segmentation (EAD2020), and ii) disease detection and segmentation (EDD2020). Multi-center, multi-organ, multi-class, and multi-modal clinical endoscopy datasets were compiled for both EAD2020 and EDD2020 sub-challenges. An out-of-sample generalisation ability of detection algorithms was also evaluated. Whilst most teams focused on accuracy improvements, only a few methods hold credibility for clinical usability. The best performing teams provided solutions to tackle class imbalance, and variabilities in size, origin, modality and occurrences by exploring data augmentation, data fusion, and optimal class thresholding techniques.