 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhy is the winner the best?
Mar 30, 2023



International benchmarking competitions have become fundamental for the comparative performance assessment of image analysis methods. However, little attention has been given to investigating what can be learnt from these competitions. Do they really generate scientific progress? What are common and successful participation strategies? What makes a solution superior to a competing method? To address this gap in the literature, we performed a multi-center study with all 80 competitions that were conducted in the scope of IEEE ISBI 2021 and MICCAI 2021. Statistical analyses performed based on comprehensive descriptions of the submitted algorithms linked to their rank as well as the underlying participation strategies revealed common characteristics of winning solutions. These typically include the use of multi-task learning (63%) and/or multi-stage pipelines (61%), and a focus on augmentation (100%), image preprocessing (97%), data curation (79%), and postprocessing (66%). The "typical" lead of a winning team is a computer scientist with a doctoral degree, five years of experience in biomedical image analysis, and four years of experience in deep learning. Two core general development strategies stood out for highly-ranked teams: the reflection of the metrics in the method design and the focus on analyzing and handling failure cases. According to the organizers, 43% of the winning algorithms exceeded the state of the art but only 11% completely solved the respective domain problem. The insights of our study could help researchers (1) improve algorithm development strategies when approaching new problems, and (2) focus on open research questions revealed by this work.
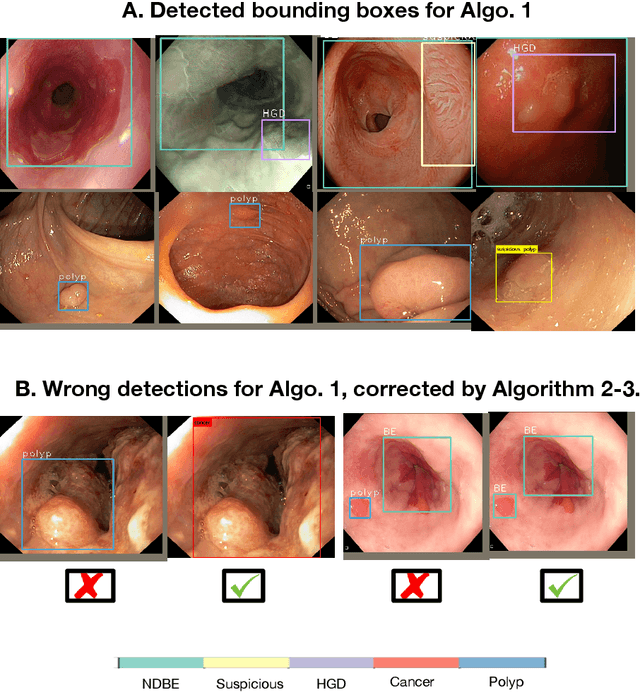
Assessing generalisability of deep learning-based polyp detection and segmentation methods through a computer vision challenge
Feb 24, 2022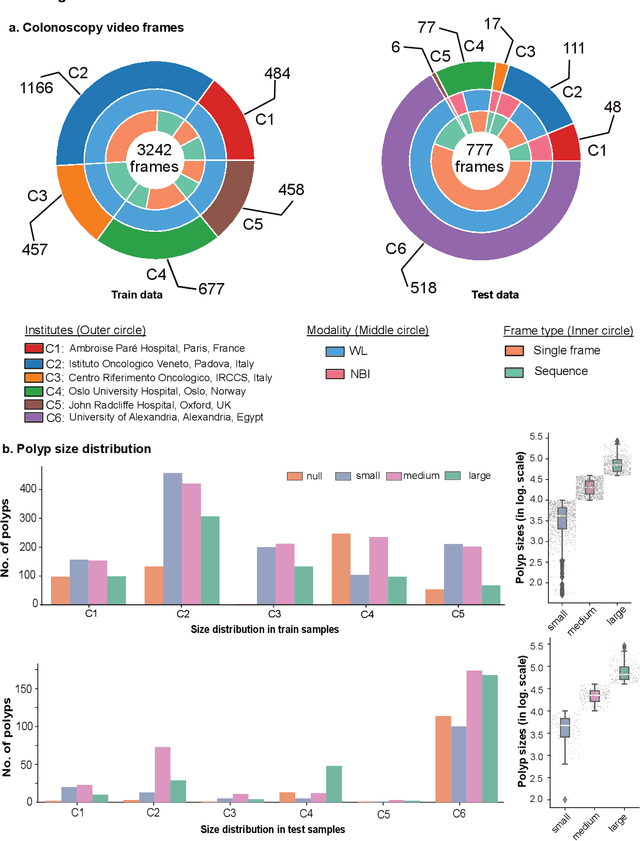
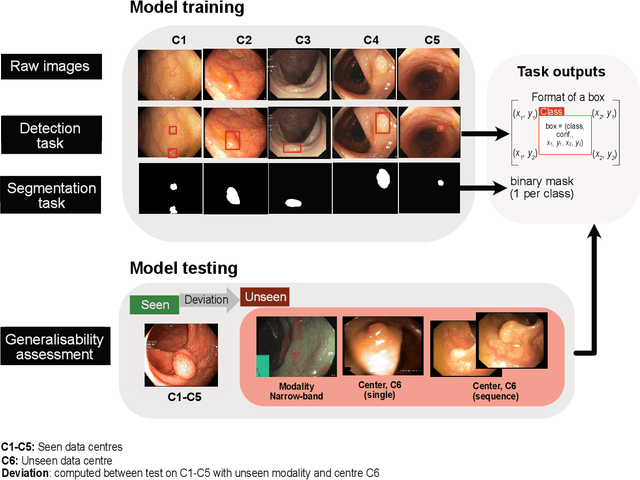
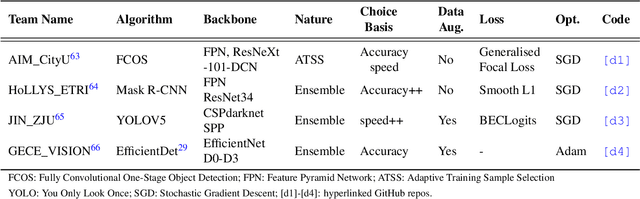
Polyps are well-known cancer precursors identified by colonoscopy. However, variability in their size, location, and surface largely affect identification, localisation, and characterisation. Moreover, colonoscopic surveillance and removal of polyps (referred to as polypectomy ) are highly operator-dependent procedures. There exist a high missed detection rate and incomplete removal of colonic polyps due to their variable nature, the difficulties to delineate the abnormality, the high recurrence rates, and the anatomical topography of the colon. There have been several developments in realising automated methods for both detection and segmentation of these polyps using machine learning. However, the major drawback in most of these methods is their ability to generalise to out-of-sample unseen datasets that come from different centres, modalities and acquisition systems. To test this hypothesis rigorously we curated a multi-centre and multi-population dataset acquired from multiple colonoscopy systems and challenged teams comprising machine learning experts to develop robust automated detection and segmentation methods as part of our crowd-sourcing Endoscopic computer vision challenge (EndoCV) 2021. In this paper, we analyse the detection results of the four top (among seven) teams and the segmentation results of the five top teams (among 16). Our analyses demonstrate that the top-ranking teams concentrated on accuracy (i.e., accuracy > 80% on overall Dice score on different validation sets) over real-time performance required for clinical applicability. We further dissect the methods and provide an experiment-based hypothesis that reveals the need for improved generalisability to tackle diversity present in multi-centre datasets.
PolypGen: A multi-center polyp detection and segmentation dataset for generalisability assessment
Jun 08, 2021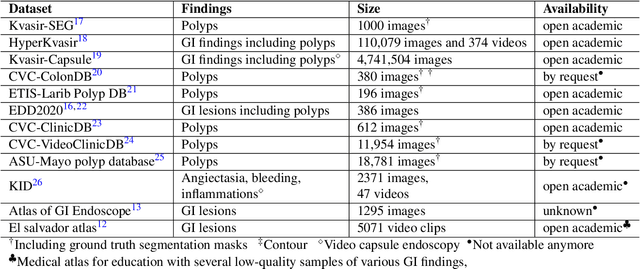
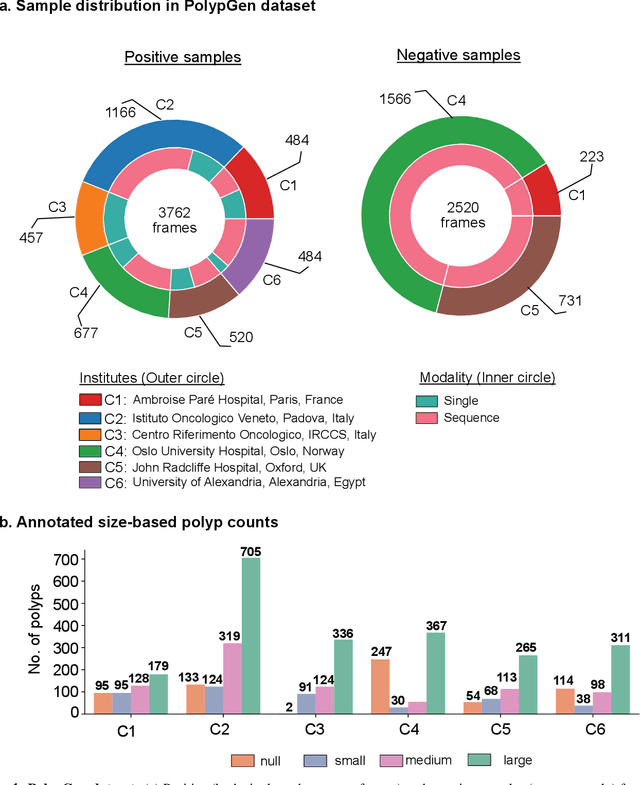
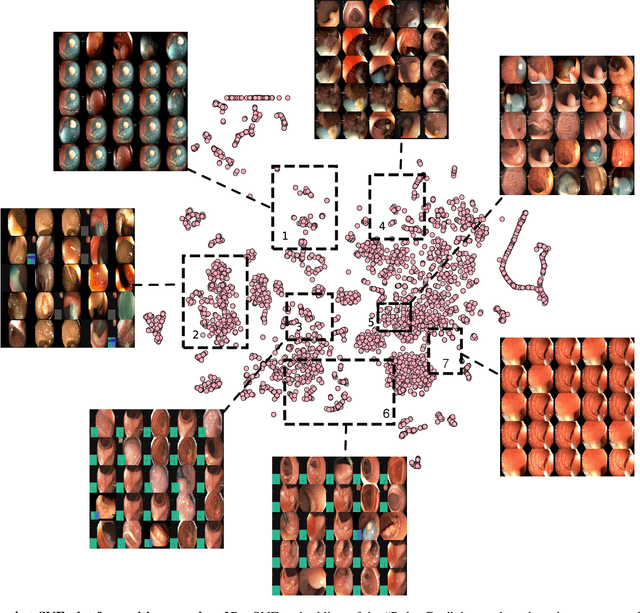
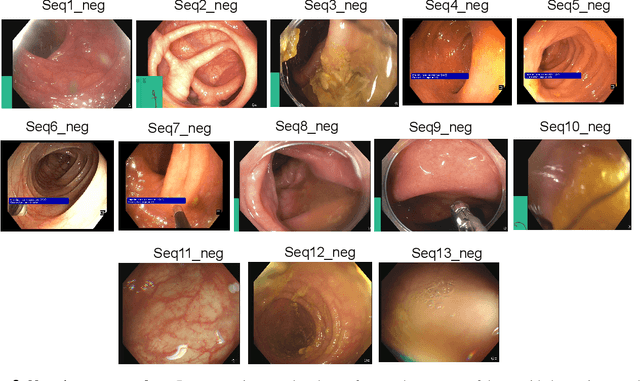
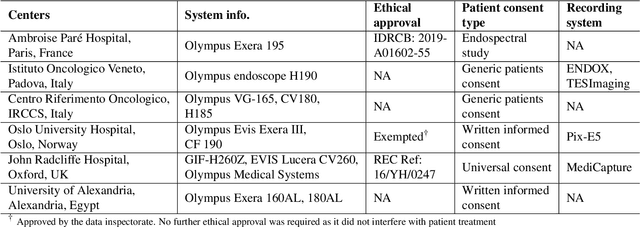
Polyps in the colon are widely known as cancer precursors identified by colonoscopy either related to diagnostic work-up for symptoms, colorectal cancer screening or systematic surveillance of certain diseases. Whilst most polyps are benign, the number, size and the surface structure of the polyp are tightly linked to the risk of colon cancer. There exists a high missed detection rate and incomplete removal of colon polyps due to the variable nature, difficulties to delineate the abnormality, high recurrence rates and the anatomical topography of the colon. In the past, several methods have been built to automate polyp detection and segmentation. However, the key issue of most methods is that they have not been tested rigorously on a large multi-center purpose-built dataset. Thus, these methods may not generalise to different population datasets as they overfit to a specific population and endoscopic surveillance. To this extent, we have curated a dataset from 6 different centers incorporating more than 300 patients. The dataset includes both single frame and sequence data with 3446 annotated polyp labels with precise delineation of polyp boundaries verified by six senior gastroenterologists. To our knowledge, this is the most comprehensive detection and pixel-level segmentation dataset curated by a team of computational scientists and expert gastroenterologists. This dataset has been originated as the part of the Endocv2021 challenge aimed at addressing generalisability in polyp detection and segmentation. In this paper, we provide comprehensive insight into data construction and annotation strategies, annotation quality assurance and technical validation for our extended EndoCV2021 dataset which we refer to as PolypGen.
A translational pathway of deep learning methods in GastroIntestinal Endoscopy
Oct 12, 2020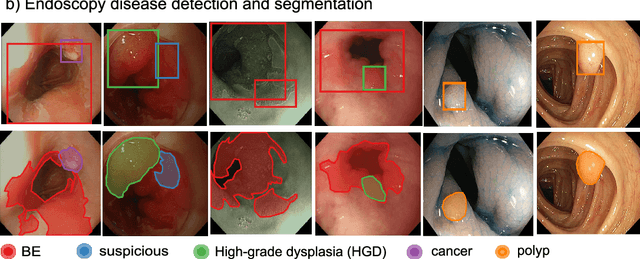
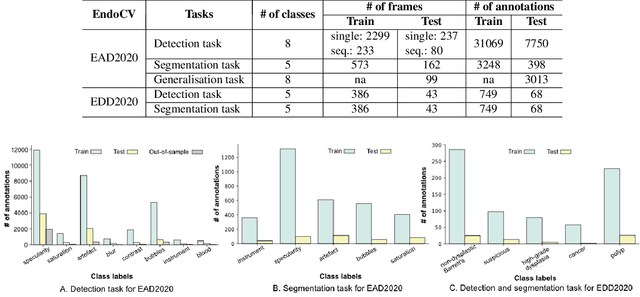
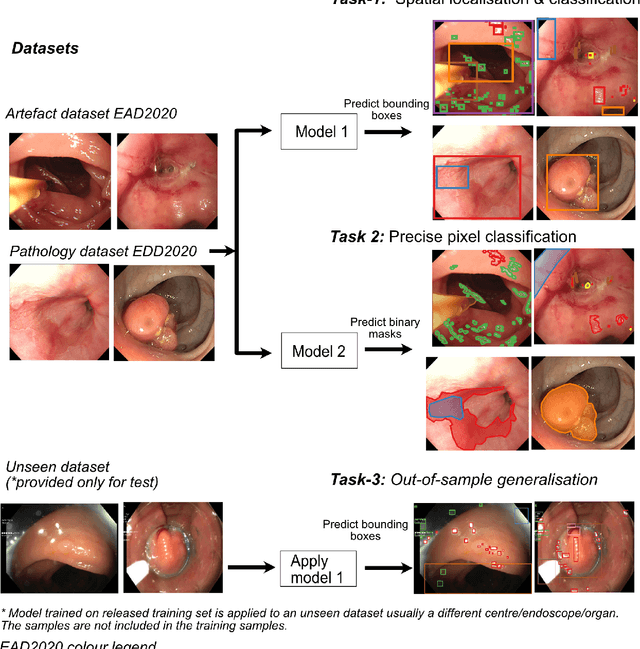
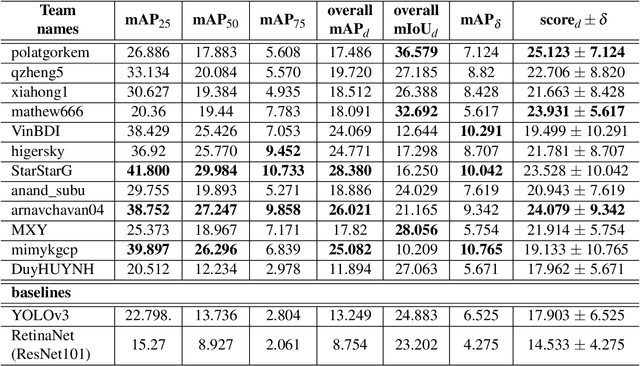
The Endoscopy Computer Vision Challenge (EndoCV) is a crowd-sourcing initiative to address eminent problems in developing reliable computer aided detection and diagnosis endoscopy systems and suggest a pathway for clinical translation of technologies. Whilst endoscopy is a widely used diagnostic and treatment tool for hollow-organs, there are several core challenges often faced by endoscopists, mainly: 1) presence of multi-class artefacts that hinder their visual interpretation, and 2) difficulty in identifying subtle precancerous precursors and cancer abnormalities. Artefacts often affect the robustness of deep learning methods applied to the gastrointestinal tract organs as they can be confused with tissue of interest. EndoCV2020 challenges are designed to address research questions in these remits. In this paper, we present a summary of methods developed by the top 17 teams and provide an objective comparison of state-of-the-art methods and methods designed by the participants for two sub-challenges: i) artefact detection and segmentation (EAD2020), and ii) disease detection and segmentation (EDD2020). Multi-center, multi-organ, multi-class, and multi-modal clinical endoscopy datasets were compiled for both EAD2020 and EDD2020 sub-challenges. An out-of-sample generalisation ability of detection algorithms was also evaluated. Whilst most teams focused on accuracy improvements, only a few methods hold credibility for clinical usability. The best performing teams provided solutions to tackle class imbalance, and variabilities in size, origin, modality and occurrences by exploring data augmentation, data fusion, and optimal class thresholding techniques.
Endoscopy disease detection challenge 2020
Mar 07, 2020
Whilst many technologies are built around endoscopy, there is a need to have a comprehensive dataset collected from multiple centers to address the generalization issues with most deep learning frameworks. What could be more important than disease detection and localization? Through our extensive network of clinical and computational experts, we have collected, curated and annotated gastrointestinal endoscopy video frames. We have released this dataset and have launched disease detection and segmentation challenge EDD2020 https://edd2020.grand-challenge.org to address the limitations and explore new directions. EDD2020 is a crowd sourcing initiative to test the feasibility of recent deep learning methods and to promote research for building robust technologies. In this paper, we provide an overview of the EDD2020 dataset, challenge tasks, evaluation strategies and a short summary of results on test data. A detailed paper will be drafted after the challenge workshop with more detailed analysis of the results.