 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSelf-supervised Monocular Depth and Pose Estimation for Endoscopy with Generative Latent Priors
Nov 26, 2024


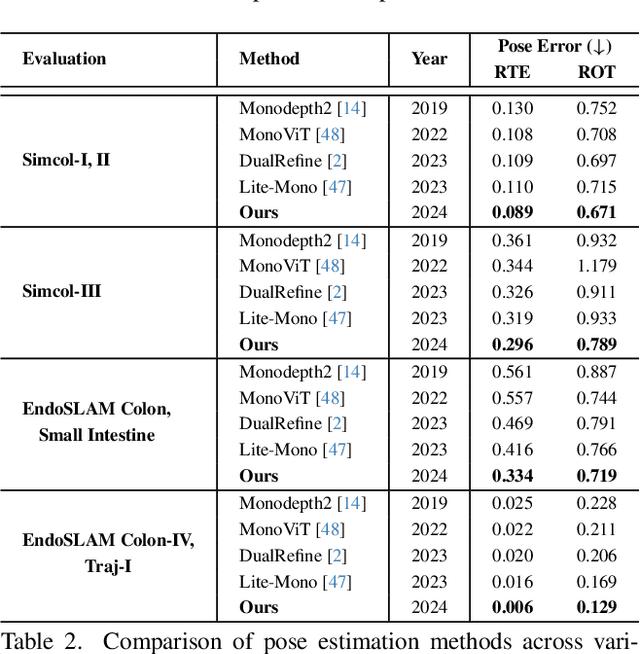
Accurate 3D mapping in endoscopy enables quantitative, holistic lesion characterization within the gastrointestinal (GI) tract, requiring reliable depth and pose estimation. However, endoscopy systems are monocular, and existing methods relying on synthetic datasets or complex models often lack generalizability in challenging endoscopic conditions. We propose a robust self-supervised monocular depth and pose estimation framework that incorporates a Generative Latent Bank and a Variational Autoencoder (VAE). The Generative Latent Bank leverages extensive depth scenes from natural images to condition the depth network, enhancing realism and robustness of depth predictions through latent feature priors. For pose estimation, we reformulate it within a VAE framework, treating pose transitions as latent variables to regularize scale, stabilize z-axis prominence, and improve x-y sensitivity. This dual refinement pipeline enables accurate depth and pose predictions, effectively addressing the GI tract's complex textures and lighting. Extensive evaluations on SimCol and EndoSLAM datasets confirm our framework's superior performance over published self-supervised methods in endoscopic depth and pose estimation.
A translational pathway of deep learning methods in GastroIntestinal Endoscopy
Oct 12, 2020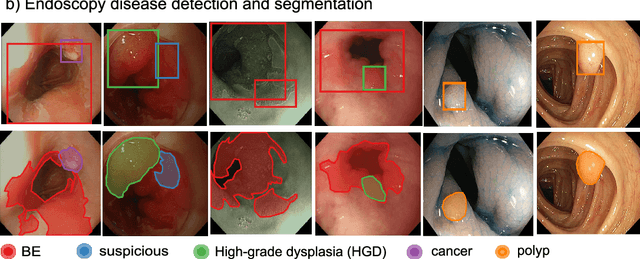
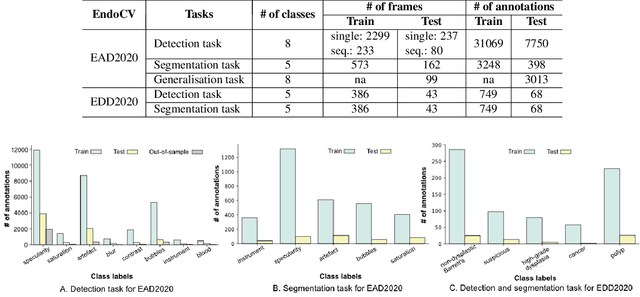
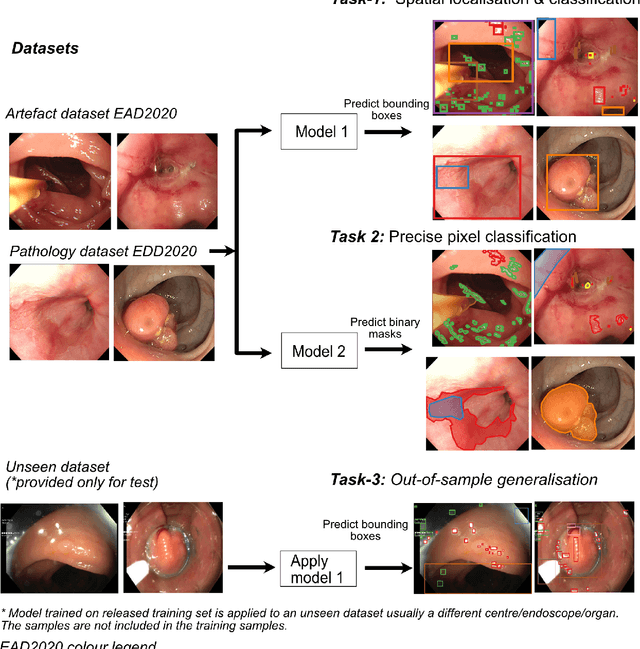
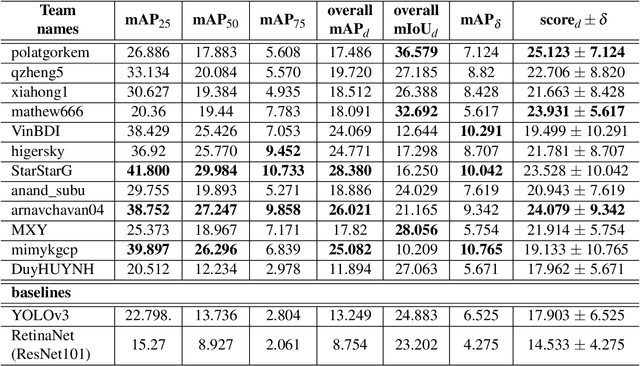
The Endoscopy Computer Vision Challenge (EndoCV) is a crowd-sourcing initiative to address eminent problems in developing reliable computer aided detection and diagnosis endoscopy systems and suggest a pathway for clinical translation of technologies. Whilst endoscopy is a widely used diagnostic and treatment tool for hollow-organs, there are several core challenges often faced by endoscopists, mainly: 1) presence of multi-class artefacts that hinder their visual interpretation, and 2) difficulty in identifying subtle precancerous precursors and cancer abnormalities. Artefacts often affect the robustness of deep learning methods applied to the gastrointestinal tract organs as they can be confused with tissue of interest. EndoCV2020 challenges are designed to address research questions in these remits. In this paper, we present a summary of methods developed by the top 17 teams and provide an objective comparison of state-of-the-art methods and methods designed by the participants for two sub-challenges: i) artefact detection and segmentation (EAD2020), and ii) disease detection and segmentation (EDD2020). Multi-center, multi-organ, multi-class, and multi-modal clinical endoscopy datasets were compiled for both EAD2020 and EDD2020 sub-challenges. An out-of-sample generalisation ability of detection algorithms was also evaluated. Whilst most teams focused on accuracy improvements, only a few methods hold credibility for clinical usability. The best performing teams provided solutions to tackle class imbalance, and variabilities in size, origin, modality and occurrences by exploring data augmentation, data fusion, and optimal class thresholding techniques.
Endoscopy disease detection challenge 2020
Mar 07, 2020
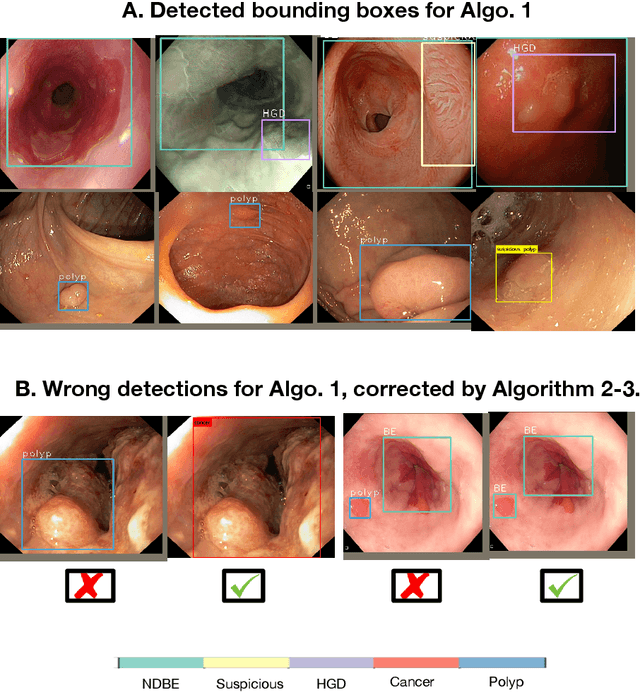
Whilst many technologies are built around endoscopy, there is a need to have a comprehensive dataset collected from multiple centers to address the generalization issues with most deep learning frameworks. What could be more important than disease detection and localization? Through our extensive network of clinical and computational experts, we have collected, curated and annotated gastrointestinal endoscopy video frames. We have released this dataset and have launched disease detection and segmentation challenge EDD2020 https://edd2020.grand-challenge.org to address the limitations and explore new directions. EDD2020 is a crowd sourcing initiative to test the feasibility of recent deep learning methods and to promote research for building robust technologies. In this paper, we provide an overview of the EDD2020 dataset, challenge tasks, evaluation strategies and a short summary of results on test data. A detailed paper will be drafted after the challenge workshop with more detailed analysis of the results.
Endoscopy artifact detection (EAD 2019) challenge dataset
May 08, 2019
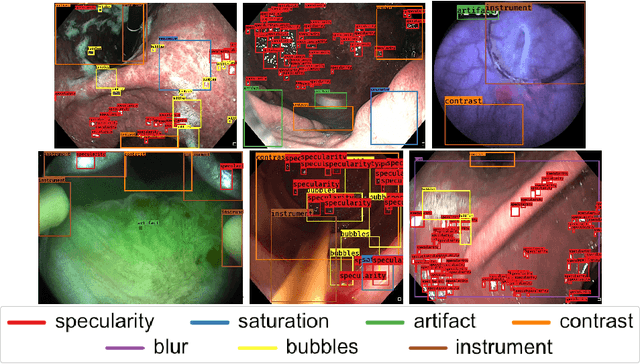
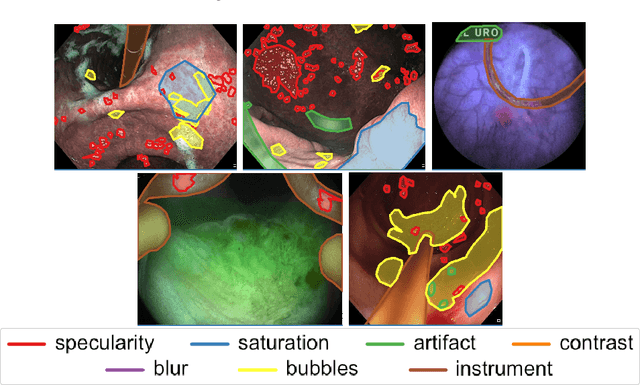
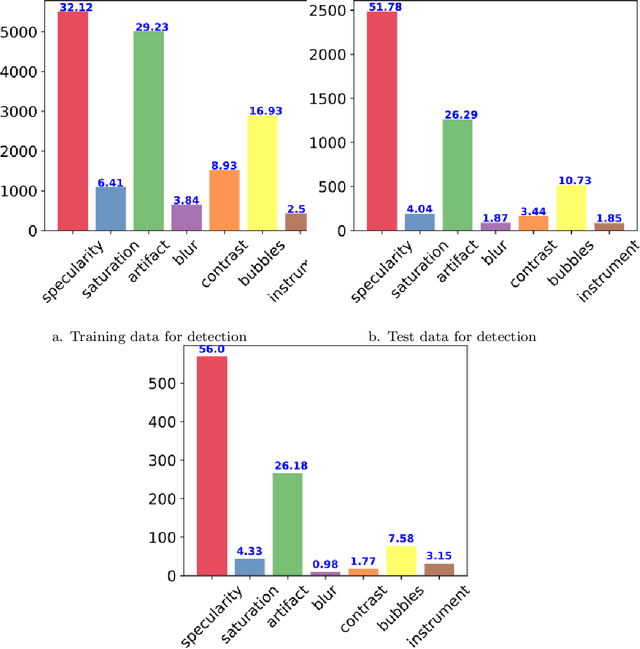
Endoscopic artifacts are a core challenge in facilitating the diagnosis and treatment of diseases in hollow organs. Precise detection of specific artifacts like pixel saturations, motion blur, specular reflections, bubbles and debris is essential for high-quality frame restoration and is crucial for realizing reliable computer-assisted tools for improved patient care. At present most videos in endoscopy are currently not analyzed due to the abundant presence of multi-class artifacts in video frames. Through the endoscopic artifact detection (EAD 2019) challenge, we address this key bottleneck problem by solving the accurate identification and localization of endoscopic frame artifacts to enable further key quantitative analysis of unusable video frames such as mosaicking and 3D reconstruction which is crucial for delivering improved patient care. This paper summarizes the challenge tasks and describes the dataset and evaluation criteria established in the EAD 2019 challenge.
A deep learning framework for quality assessment and restoration in video endoscopy
Apr 15, 2019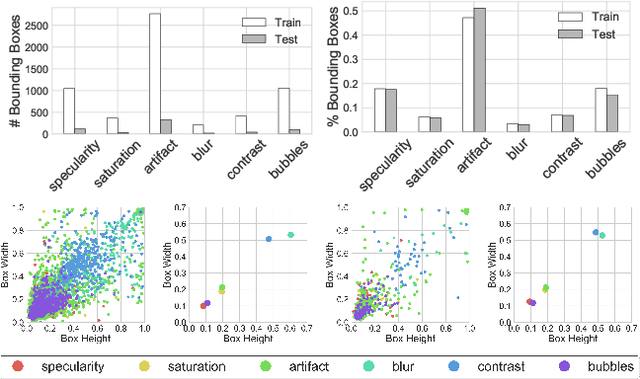
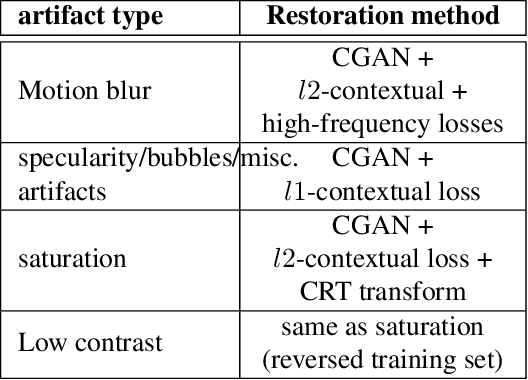
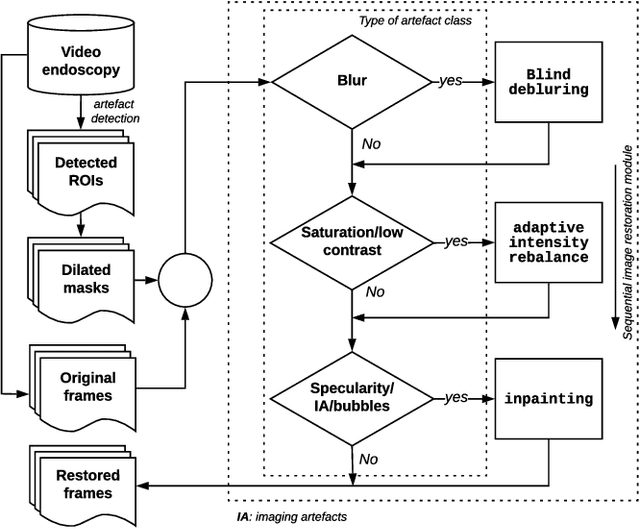
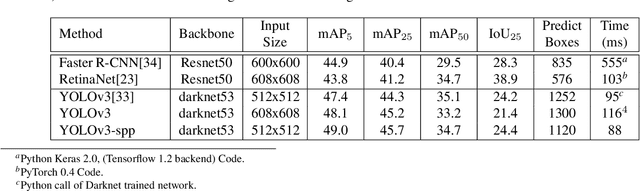
Endoscopy is a routine imaging technique used for both diagnosis and minimally invasive surgical treatment. Artifacts such as motion blur, bubbles, specular reflections, floating objects and pixel saturation impede the visual interpretation and the automated analysis of endoscopy videos. Given the widespread use of endoscopy in different clinical applications, we contend that the robust and reliable identification of such artifacts and the automated restoration of corrupted video frames is a fundamental medical imaging problem. Existing state-of-the-art methods only deal with the detection and restoration of selected artifacts. However, typically endoscopy videos contain numerous artifacts which motivates to establish a comprehensive solution. We propose a fully automatic framework that can: 1) detect and classify six different primary artifacts, 2) provide a quality score for each frame and 3) restore mildly corrupted frames. To detect different artifacts our framework exploits fast multi-scale, single stage convolutional neural network detector. We introduce a quality metric to assess frame quality and predict image restoration success. Generative adversarial networks with carefully chosen regularization are finally used to restore corrupted frames. Our detector yields the highest mean average precision (mAP at 5% threshold) of 49.0 and the lowest computational time of 88 ms allowing for accurate real-time processing. Our restoration models for blind deblurring, saturation correction and inpainting demonstrate significant improvements over previous methods. On a set of 10 test videos we show that our approach preserves an average of 68.7% which is 25% more frames than that retained from the raw videos.