 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSelf-supervised Monocular Depth and Pose Estimation for Endoscopy with Generative Latent Priors
Nov 26, 2024


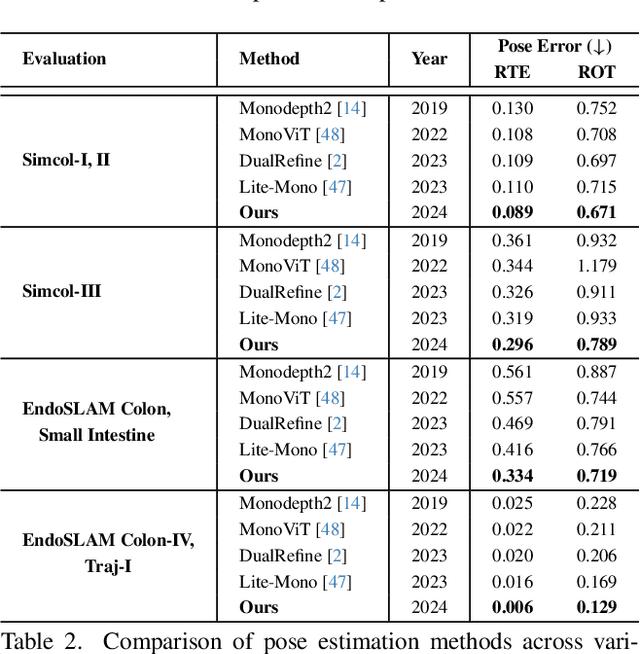
Accurate 3D mapping in endoscopy enables quantitative, holistic lesion characterization within the gastrointestinal (GI) tract, requiring reliable depth and pose estimation. However, endoscopy systems are monocular, and existing methods relying on synthetic datasets or complex models often lack generalizability in challenging endoscopic conditions. We propose a robust self-supervised monocular depth and pose estimation framework that incorporates a Generative Latent Bank and a Variational Autoencoder (VAE). The Generative Latent Bank leverages extensive depth scenes from natural images to condition the depth network, enhancing realism and robustness of depth predictions through latent feature priors. For pose estimation, we reformulate it within a VAE framework, treating pose transitions as latent variables to regularize scale, stabilize z-axis prominence, and improve x-y sensitivity. This dual refinement pipeline enables accurate depth and pose predictions, effectively addressing the GI tract's complex textures and lighting. Extensive evaluations on SimCol and EndoSLAM datasets confirm our framework's superior performance over published self-supervised methods in endoscopic depth and pose estimation.
SSTFB: Leveraging self-supervised pretext learning and temporal self-attention with feature branching for real-time video polyp segmentation
Jun 14, 2024Polyps are early cancer indicators, so assessing occurrences of polyps and their removal is critical. They are observed through a colonoscopy screening procedure that generates a stream of video frames. Segmenting polyps in their natural video screening procedure has several challenges, such as the co-existence of imaging artefacts, motion blur, and floating debris. Most existing polyp segmentation algorithms are developed on curated still image datasets that do not represent real-world colonoscopy. Their performance often degrades on video data. We propose a video polyp segmentation method that performs self-supervised learning as an auxiliary task and a spatial-temporal self-attention mechanism for improved representation learning. Our end-to-end configuration and joint optimisation of losses enable the network to learn more discriminative contextual features in videos. Our experimental results demonstrate an improvement with respect to several state-of-the-art (SOTA) methods. Our ablation study also confirms that the choice of the proposed joint end-to-end training improves network accuracy by over 3% and nearly 10% on both the Dice similarity coefficient and intersection-over-union compared to the recently proposed method PNS+ and Polyp-PVT, respectively. Results on previously unseen video data indicate that the proposed method generalises.
SSL-CPCD: Self-supervised learning with composite pretext-class discrimination for improved generalisability in endoscopic image analysis
May 31, 2023Data-driven methods have shown tremendous progress in medical image analysis. In this context, deep learning-based supervised methods are widely popular. However, they require a large amount of training data and face issues in generalisability to unseen datasets that hinder clinical translation. Endoscopic imaging data incorporates large inter- and intra-patient variability that makes these models more challenging to learn representative features for downstream tasks. Thus, despite the publicly available datasets and datasets that can be generated within hospitals, most supervised models still underperform. While self-supervised learning has addressed this problem to some extent in natural scene data, there is a considerable performance gap in the medical image domain. In this paper, we propose to explore patch-level instance-group discrimination and penalisation of inter-class variation using additive angular margin within the cosine similarity metrics. Our novel approach enables models to learn to cluster similar representative patches, thereby improving their ability to provide better separation between different classes. Our results demonstrate significant improvement on all metrics over the state-of-the-art (SOTA) methods on the test set from the same and diverse datasets. We evaluated our approach for classification, detection, and segmentation. SSL-CPCD achieves 79.77% on Top 1 accuracy for ulcerative colitis classification, 88.62% on mAP for polyp detection, and 82.32% on dice similarity coefficient for segmentation tasks are nearly over 4%, 2%, and 3%, respectively, compared to the baseline architectures. We also demonstrate that our method generalises better than all SOTA methods to unseen datasets, reporting nearly 7% improvement in our generalisability assessment.
Patch-level instance-group discrimination with pretext-invariant learning for colitis scoring
Jul 11, 2022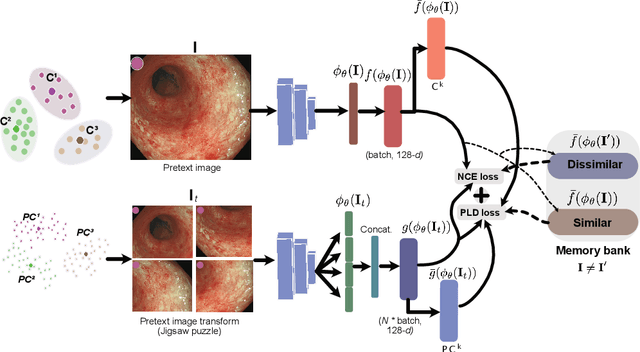
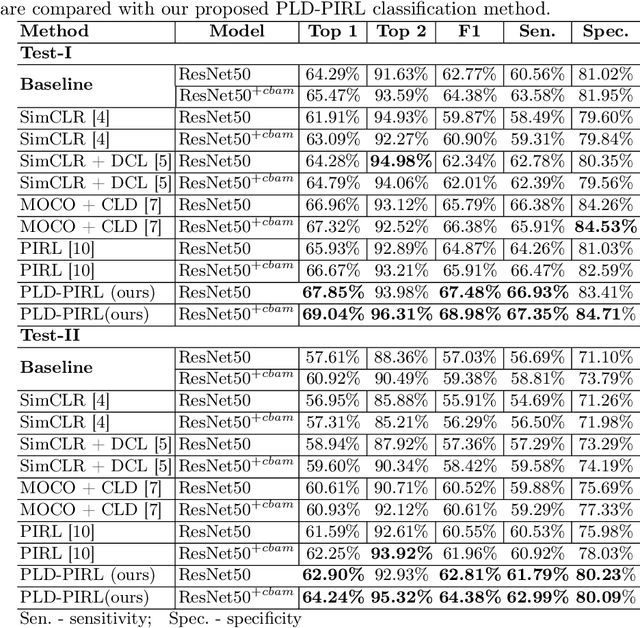
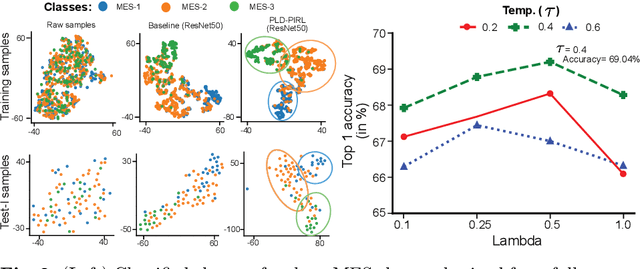
Inflammatory bowel disease (IBD), in particular ulcerative colitis (UC), is graded by endoscopists and this assessment is the basis for risk stratification and therapy monitoring. Presently, endoscopic characterisation is largely operator dependant leading to sometimes undesirable clinical outcomes for patients with IBD. We focus on the Mayo Endoscopic Scoring (MES) system which is widely used but requires the reliable identification of subtle changes in mucosal inflammation. Most existing deep learning classification methods cannot detect these fine-grained changes which make UC grading such a challenging task. In this work, we introduce a novel patch-level instance-group discrimination with pretext-invariant representation learning (PLD-PIRL) for self-supervised learning (SSL). Our experiments demonstrate both improved accuracy and robustness compared to the baseline supervised network and several state-of-the-art SSL methods. Compared to the baseline (ResNet50) supervised classification our proposed PLD-PIRL obtained an improvement of 4.75% on hold-out test data and 6.64% on unseen center test data for top-1 accuracy.