 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLeLaR: The First In-Orbit Demonstration of an AI-Based Satellite Attitude Controller
Dec 23, 2025Attitude control is essential for many satellite missions. Classical controllers, however, are time-consuming to design and sensitive to model uncertainties and variations in operational boundary conditions. Deep Reinforcement Learning (DRL) offers a promising alternative by learning adaptive control strategies through autonomous interaction with a simulation environment. Overcoming the Sim2Real gap, which involves deploying an agent trained in simulation onto the real physical satellite, remains a significant challenge. In this work, we present the first successful in-orbit demonstration of an AI-based attitude controller for inertial pointing maneuvers. The controller was trained entirely in simulation and deployed to the InnoCube 3U nanosatellite, which was developed by the Julius-Maximilians-Universität Würzburg in cooperation with the Technische Universität Berlin, and launched in January 2025. We present the AI agent design, the methodology of the training procedure, the discrepancies between the simulation and the observed behavior of the real satellite, and a comparison of the AI-based attitude controller with the classical PD controller of InnoCube. Steady-state metrics confirm the robust performance of the AI-based controller during repeated in-orbit maneuvers.
QBI: Quantile-based Bias Initialization for Efficient Private Data Reconstruction in Federated Learning
Jun 26, 2024



Federated learning enables the training of machine learning models on distributed data without compromising user privacy, as data remains on personal devices and only model updates, such as gradients, are shared with a central coordinator. However, recent research has shown that the central entity can perfectly reconstruct private data from shared model updates by maliciously initializing the model's parameters. In this paper, we propose QBI, a novel bias initialization method that significantly enhances reconstruction capabilities. This is accomplished by directly solving for bias values yielding sparse activation patterns. Further, we propose PAIRS, an algorithm that builds on QBI. PAIRS can be deployed when a separate dataset from the target domain is available to further increase the percentage of data that can be fully recovered. Measured by the percentage of samples that can be perfectly reconstructed from batches of various sizes, our approach achieves significant improvements over previous methods with gains of up to 50% on ImageNet and up to 60% on the IMDB sentiment analysis text dataset. Furthermore, we establish theoretical limits for attacks leveraging stochastic gradient sparsity, providing a foundation for understanding the fundamental constraints of these attacks. We empirically assess these limits using synthetic datasets. Finally, we propose and evaluate AGGP, a defensive framework designed to prevent gradient sparsity attacks, contributing to the development of more secure and private federated learning systems.
OCR4all -- An Open-Source Tool Providing a Automatic OCR Workflow for Historical Printings
Sep 09, 2019

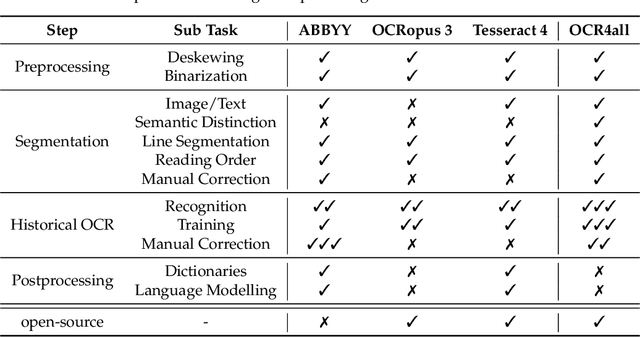
Optical Character Recognition (OCR) on historical printings is a challenging task mainly due to the complexity of the layout and the highly variant typography. Nevertheless, in the last few years great progress has been made in the area of historical OCR, resulting in several powerful open-source tools for preprocessing, layout recognition and segmentation, character recognition and post-processing. The drawback of these tools often is their limited applicability by non-technical users like humanist scholars and in particular the combined use of several tools in a workflow. In this paper we present an open-source OCR software called OCR4all, which combines state-of-the-art OCR components and continuous model training into a comprehensive workflow. A comfortable GUI allows error corrections not only in the final output, but already in early stages to minimize error propagations. Further on, extensive configuration capabilities are provided to set the degree of automation of the workflow and to make adaptations to the carefully selected default parameters for specific printings, if necessary. Experiments showed that users with minimal or no experience were able to capture the text of even the earliest printed books with manageable effort and great quality, achieving excellent character error rates (CERs) below 0.5%. The fully automated application on 19th century novels showed that OCR4all can considerably outperform the commercial state-of-the-art tool ABBYY Finereader on moderate layouts if suitably pretrained mixed OCR models are available. The architecture of OCR4all allows the easy integration (or substitution) of newly developed tools for its main components by standardized interfaces like PageXML, thus aiming at continual higher automation for historical printings.
State of the Art Optical Character Recognition of 19th Century Fraktur Scripts using Open Source Engines
Oct 08, 2018In this paper we evaluate Optical Character Recognition (OCR) of 19th century Fraktur scripts without book-specific training using mixed models, i.e. models trained to recognize a variety of fonts and typesets from previously unseen sources. We describe the training process leading to strong mixed OCR models and compare them to freely available models of the popular open source engines OCRopus and Tesseract as well as the commercial state of the art system ABBYY. For evaluation, we use a varied collection of unseen data from books, journals, and a dictionary from the 19th century. The experiments show that training mixed models with real data is superior to training with synthetic data and that the novel OCR engine Calamari outperforms the other engines considerably, on average reducing ABBYYs character error rate (CER) by over 70%, resulting in an average CER below 1%.
Calamari - A High-Performance Tensorflow-based Deep Learning Package for Optical Character Recognition
Aug 06, 2018
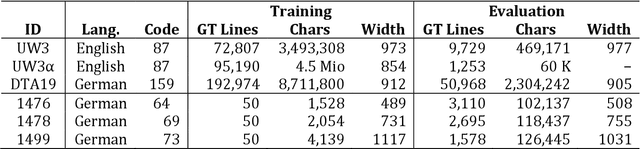

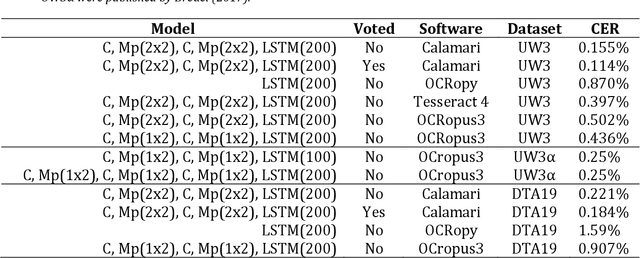
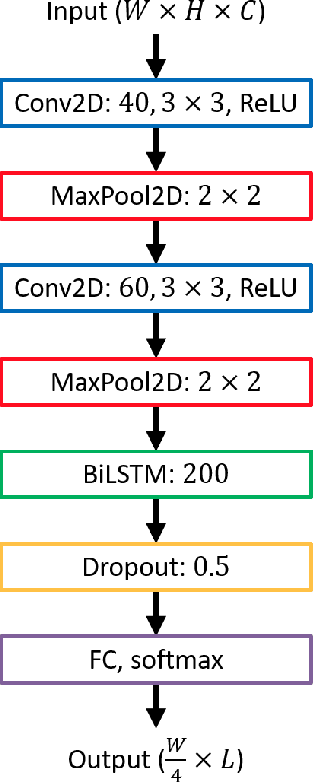
Optical Character Recognition (OCR) on contemporary and historical data is still in the focus of many researchers. Especially historical prints require book specific trained OCR models to achieve applicable results (Springmann and L\"udeling, 2016, Reul et al., 2017a). To reduce the human effort for manually annotating ground truth (GT) various techniques such as voting and pretraining have shown to be very efficient (Reul et al., 2018a, Reul et al., 2018b). Calamari is a new open source OCR line recognition software that both uses state-of-the art Deep Neural Networks (DNNs) implemented in Tensorflow and giving native support for techniques such as pretraining and voting. The customizable network architectures constructed of Convolutional Neural Networks (CNNS) and Long-ShortTerm-Memory (LSTM) layers are trained by the so-called Connectionist Temporal Classification (CTC) algorithm of Graves et al. (2006). Optional usage of a GPU drastically reduces the computation times for both training and prediction. We use two different datasets to compare the performance of Calamari to OCRopy, OCRopus3, and Tesseract 4. Calamari reaches a Character Error Rate (CER) of 0.11% on the UW3 dataset written in modern English and 0.18% on the DTA19 dataset written in German Fraktur, which considerably outperforms the results of the existing softwares.
Improving OCR Accuracy on Early Printed Books by combining Pretraining, Voting, and Active Learning
Feb 28, 2018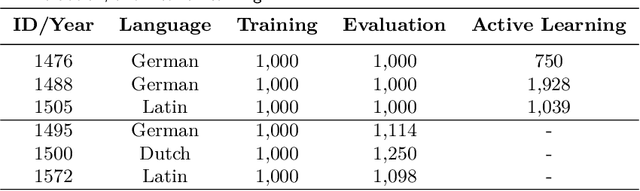

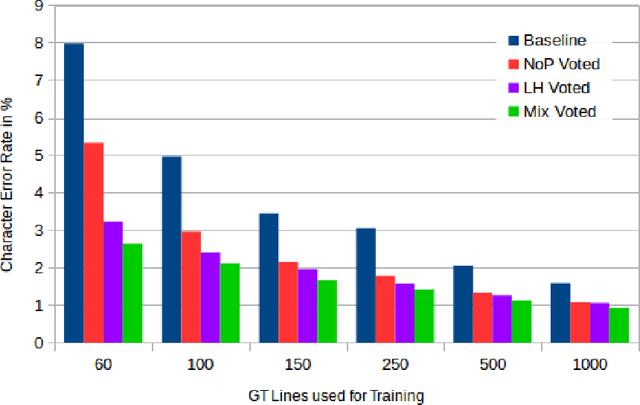
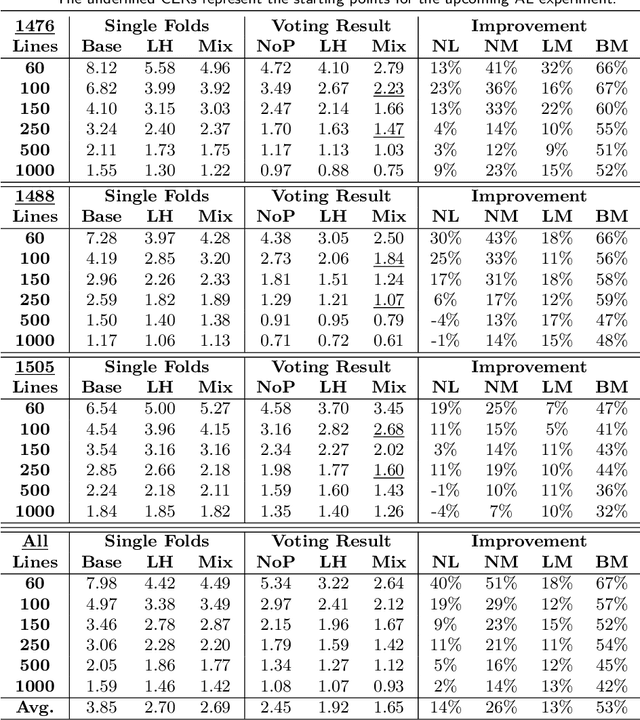
We combine three methods which significantly improve the OCR accuracy of OCR models trained on early printed books: (1) The pretraining method utilizes the information stored in already existing models trained on a variety of typesets (mixed models) instead of starting the training from scratch. (2) Performing cross fold training on a single set of ground truth data (line images and their transcriptions) with a single OCR engine (OCRopus) produces a committee whose members then vote for the best outcome by also taking the top-N alternatives and their intrinsic confidence values into account. (3) Following the principle of maximal disagreement we select additional training lines which the voters disagree most on, expecting them to offer the highest information gain for a subsequent training (active learning). Evaluations on six early printed books yielded the following results: On average the combination of pretraining and voting improved the character accuracy by 46% when training five folds starting from the same mixed model. This number rose to 53% when using different models for pretraining, underlining the importance of diverse voters. Incorporating active learning improved the obtained results by another 16% on average (evaluated on three of the six books). Overall, the proposed methods lead to an average error rate of 2.5% when training on only 60 lines. Using a substantial ground truth pool of 1,000 lines brought the error rate down even further to less than 1% on average.
Improving OCR Accuracy on Early Printed Books using Deep Convolutional Networks
Feb 27, 2018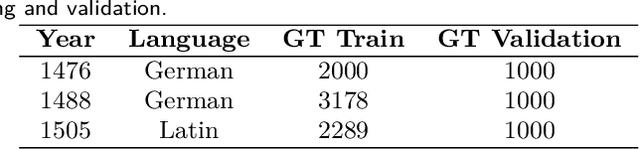


This paper proposes a combination of a convolutional and a LSTM network to improve the accuracy of OCR on early printed books. While the standard model of line based OCR uses a single LSTM layer, we utilize a CNN- and Pooling-Layer combination in advance of an LSTM layer. Due to the higher amount of trainable parameters the performance of the network relies on a high amount of training examples to unleash its power. Hereby, the error is reduced by a factor of up to 44%, yielding a CER of 1% and below. To further improve the results we use a voting mechanism to achieve character error rates (CER) below $0.5%$. The runtime of the deep model for training and prediction of a book behaves very similar to a shallow network.
Fully Convolutional Neural Networks for Page Segmentation of Historical Document Images
Feb 15, 2018


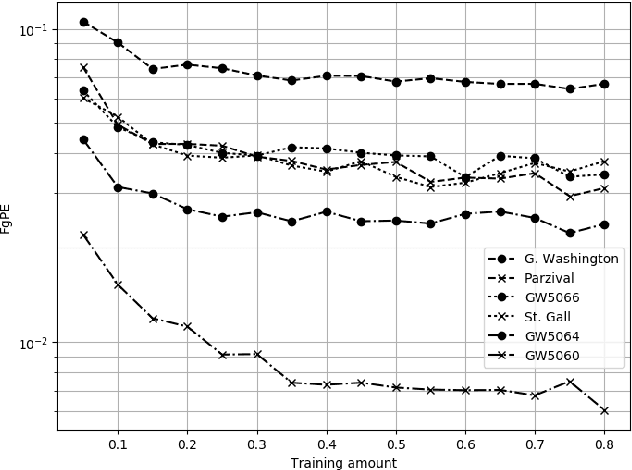
We propose a high-performance fully convolutional neural network (FCN) for historical document segmentation that is designed to process a single page in one step. The advantage of this model beside its speed is its ability to directly learn from raw pixels instead of using preprocessing steps e. g. feature computation or superpixel generation. We show that this network yields better results than existing methods on different public data sets. For evaluation of this model we introduce a novel metric that is independent of ambiguous ground truth called Foreground Pixel Accuracy (FgPA). This pixel based measure only counts foreground pixels in the binarized page, any background pixel is omitted. The major advantage of this metric is, that it enables researchers to compare different segmentation methods on their ability to successfully segment text or pictures and not on their ability to learn and possibly overfit the peculiarities of an ambiguous hand-made ground truth segmentation.
Transfer Learning for OCRopus Model Training on Early Printed Books
Dec 21, 2017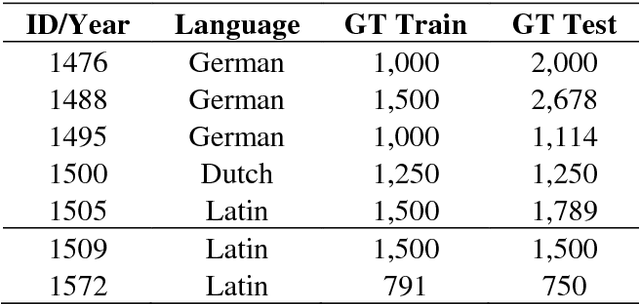

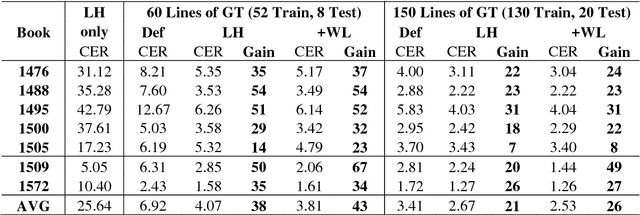
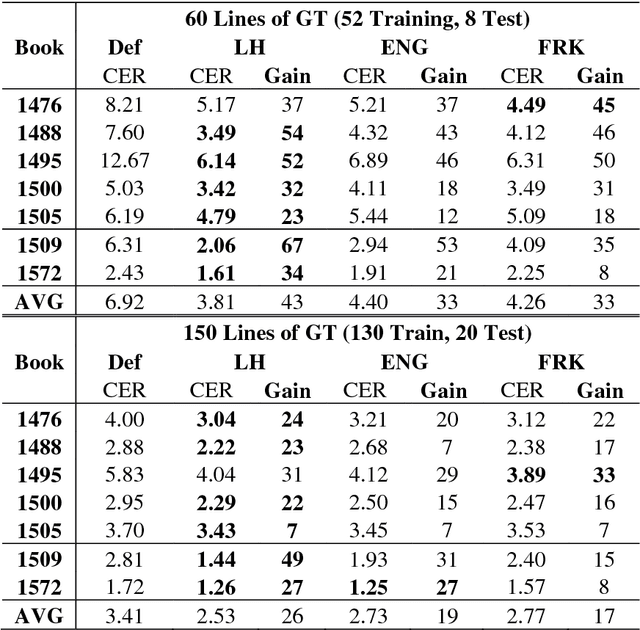
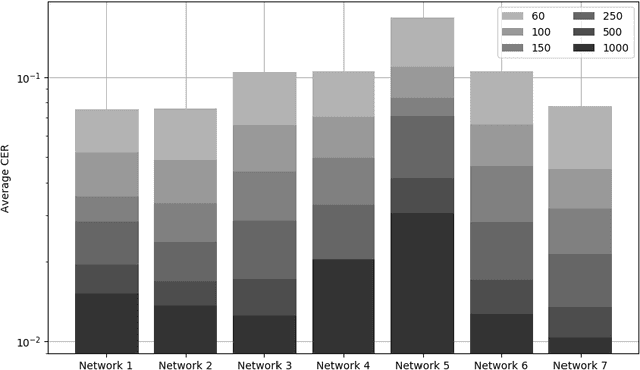
A method is presented that significantly reduces the character error rates for OCR text obtained from OCRopus models trained on early printed books when only small amounts of diplomatic transcriptions are available. This is achieved by building from already existing models during training instead of starting from scratch. To overcome the discrepancies between the set of characters of the pretrained model and the additional ground truth the OCRopus code is adapted to allow for alphabet expansion or reduction. The character set is now capable of flexibly adding and deleting characters from the pretrained alphabet when an existing model is loaded. For our experiments we use a self-trained mixed model on early Latin prints and the two standard OCRopus models on modern English and German Fraktur texts. The evaluation on seven early printed books showed that training from the Latin mixed model reduces the average amount of errors by 43% and 26%, respectively compared to training from scratch with 60 and 150 lines of ground truth, respectively. Furthermore, it is shown that even building from mixed models trained on data unrelated to the newly added training and test data can lead to significantly improved recognition results.
Leaf Identification Using a Deep Convolutional Neural Network
Dec 04, 2017



Convolutional neural networks (CNNs) have become popular especially in computer vision in the last few years because they achieved outstanding performance on different tasks, such as image classifications. We propose a nine-layer CNN for leaf identification using the famous Flavia and Foliage datasets. Usually the supervised learning of deep CNNs requires huge datasets for training. However, the used datasets contain only a few examples per plant species. Therefore, we apply data augmentation and transfer learning to prevent our network from overfitting. The trained CNNs achieve recognition rates above 99% on the Flavia and Foliage datasets, and slightly outperform current methods for leaf classification.