 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving OCR Accuracy on Early Printed Books by combining Pretraining, Voting, and Active Learning
Paper and Code
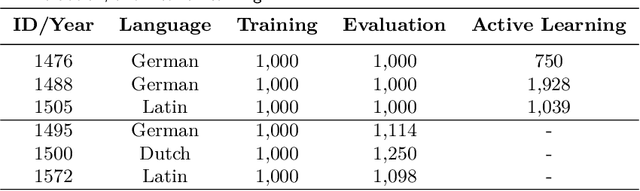

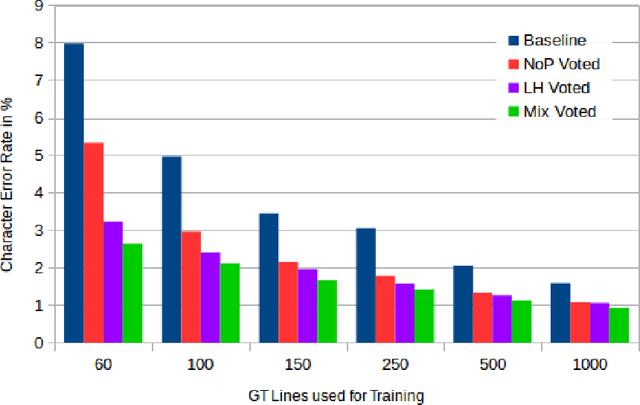
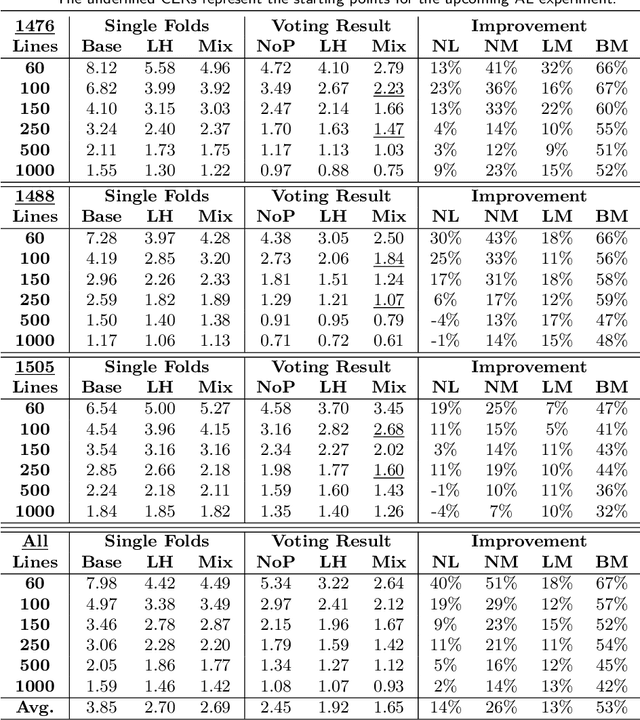
We combine three methods which significantly improve the OCR accuracy of OCR models trained on early printed books: (1) The pretraining method utilizes the information stored in already existing models trained on a variety of typesets (mixed models) instead of starting the training from scratch. (2) Performing cross fold training on a single set of ground truth data (line images and their transcriptions) with a single OCR engine (OCRopus) produces a committee whose members then vote for the best outcome by also taking the top-N alternatives and their intrinsic confidence values into account. (3) Following the principle of maximal disagreement we select additional training lines which the voters disagree most on, expecting them to offer the highest information gain for a subsequent training (active learning). Evaluations on six early printed books yielded the following results: On average the combination of pretraining and voting improved the character accuracy by 46% when training five folds starting from the same mixed model. This number rose to 53% when using different models for pretraining, underlining the importance of diverse voters. Incorporating active learning improved the obtained results by another 16% on average (evaluated on three of the six books). Overall, the proposed methods lead to an average error rate of 2.5% when training on only 60 lines. Using a substantial ground truth pool of 1,000 lines brought the error rate down even further to less than 1% on average.