 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRescoring Sequence-to-Sequence Models for Text Line Recognition with CTC-Prefixes
Oct 13, 2021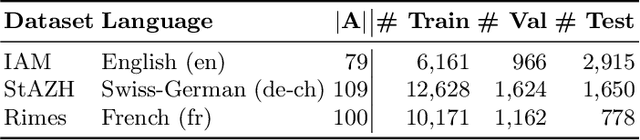

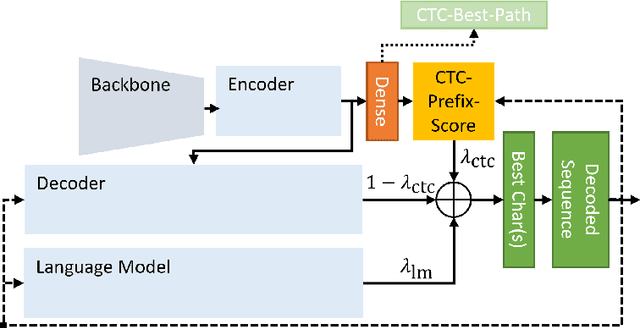

In contrast to Connectionist Temporal Classification (CTC) approaches, Sequence-To-Sequence (S2S) models for Handwritten Text Recognition (HTR) suffer from errors such as skipped or repeated words which often occur at the end of a sequence. In this paper, to combine the best of both approaches, we propose to use the CTC-Prefix-Score during S2S decoding. Hereby, during beam search, paths that are invalid according to the CTC confidence matrix are penalised. Our network architecture is composed of a Convolutional Neural Network (CNN) as visual backbone, bidirectional Long-Short-Term-Memory-Cells (LSTMs) as encoder, and a decoder which is a Transformer with inserted mutual attention layers. The CTC confidences are computed on the encoder while the Transformer is only used for character-wise S2S decoding. We evaluate this setup on three HTR data sets: IAM, Rimes, and StAZH. On IAM, we achieve a competitive Character Error Rate (CER) of 2.95% when pretraining our model on synthetic data and including a character-based language model for contemporary English. Compared to other state-of-the-art approaches, our model requires about 10-20 times less parameters. Access our shared implementations via this link to GitHub: https://github.com/Planet-AI-GmbH/tfaip-hybrid-ctc-s2s.
Mixed Model OCR Training on Historical Latin Script for Out-of-the-Box Recognition and Finetuning
Jun 15, 2021

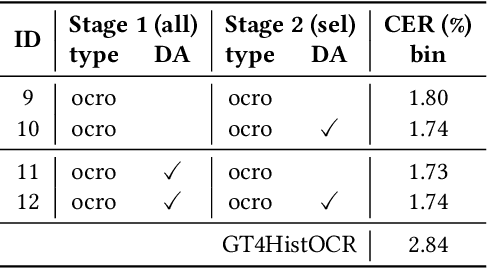
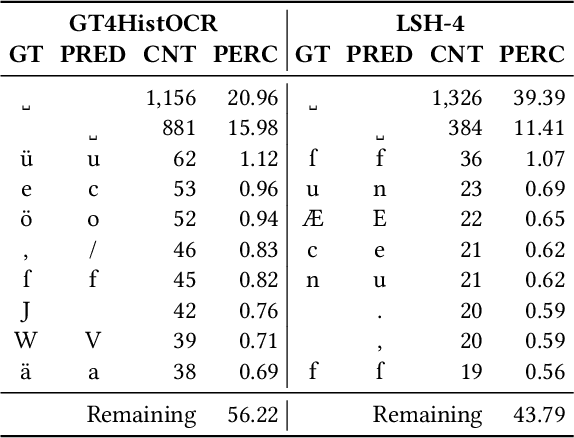
In order to apply Optical Character Recognition (OCR) to historical printings of Latin script fully automatically, we report on our efforts to construct a widely-applicable polyfont recognition model yielding text with a Character Error Rate (CER) around 2% when applied out-of-the-box. Moreover, we show how this model can be further finetuned to specific classes of printings with little manual and computational effort. The mixed or polyfont model is trained on a wide variety of materials, in terms of age (from the 15th to the 19th century), typography (various types of Fraktur and Antiqua), and languages (among others, German, Latin, and French). To optimize the results we combined established techniques of OCR training like pretraining, data augmentation, and voting. In addition, we used various preprocessing methods to enrich the training data and obtain more robust models. We also implemented a two-stage approach which first trains on all available, considerably unbalanced data and then refines the output by training on a selected more balanced subset. Evaluations on 29 previously unseen books resulted in a CER of 1.73%, outperforming a widely used standard model with a CER of 2.84% by almost 40%. Training a more specialized model for some unseen Early Modern Latin books starting from our mixed model led to a CER of 1.47%, an improvement of up to 50% compared to training from scratch and up to 30% compared to training from the aforementioned standard model. Our new mixed model is made openly available to the community.
Optimizing small BERTs trained for German NER
Apr 23, 2021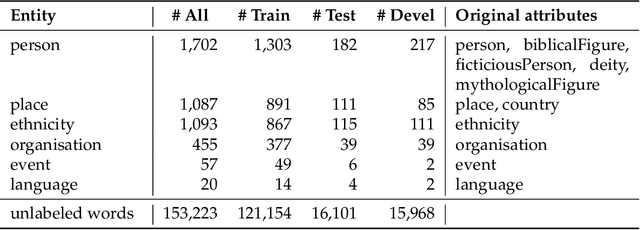
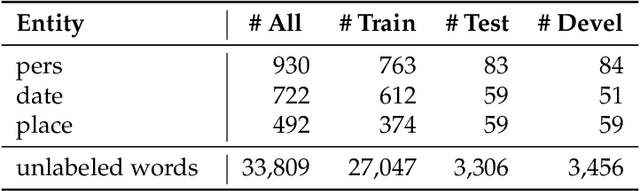

Currently, the most widespread neural network architecture for training language models is the so called BERT which led to improvements in various NLP tasks. In general, the larger the number of parameters in a BERT model, the better the results obtained in these NLP tasks. Unfortunately, the memory consumption and the training duration drastically increases with the size of these models, though. In this article, we investigate various training techniques of smaller BERT models and evaluate them on five public German NER tasks of which two are introduced by this article. We combine different methods from other BERT variants like ALBERT, RoBERTa, and relative positional encoding. In addition, we propose two new fine-tuning techniques leading to better performance: CSE-tagging and a modified form of LCRF. Furthermore, we introduce a new technique called WWA which reduces BERT memory usage and leads to a small increase in performance.
OCR4all -- An Open-Source Tool Providing a Automatic OCR Workflow for Historical Printings
Sep 09, 2019

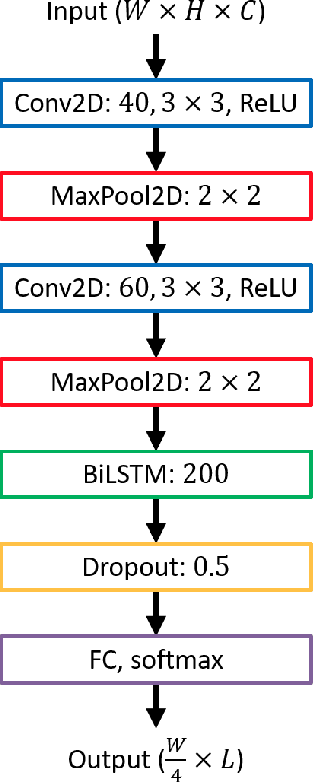
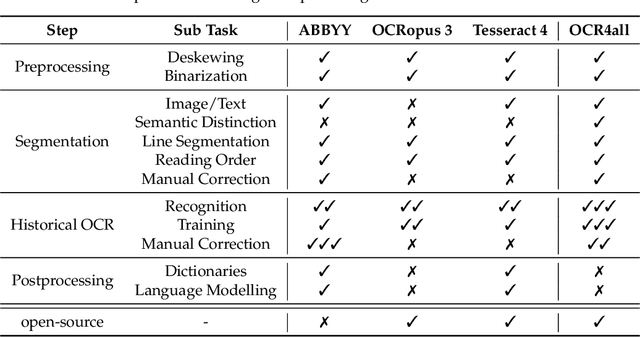
Optical Character Recognition (OCR) on historical printings is a challenging task mainly due to the complexity of the layout and the highly variant typography. Nevertheless, in the last few years great progress has been made in the area of historical OCR, resulting in several powerful open-source tools for preprocessing, layout recognition and segmentation, character recognition and post-processing. The drawback of these tools often is their limited applicability by non-technical users like humanist scholars and in particular the combined use of several tools in a workflow. In this paper we present an open-source OCR software called OCR4all, which combines state-of-the-art OCR components and continuous model training into a comprehensive workflow. A comfortable GUI allows error corrections not only in the final output, but already in early stages to minimize error propagations. Further on, extensive configuration capabilities are provided to set the degree of automation of the workflow and to make adaptations to the carefully selected default parameters for specific printings, if necessary. Experiments showed that users with minimal or no experience were able to capture the text of even the earliest printed books with manageable effort and great quality, achieving excellent character error rates (CERs) below 0.5%. The fully automated application on 19th century novels showed that OCR4all can considerably outperform the commercial state-of-the-art tool ABBYY Finereader on moderate layouts if suitably pretrained mixed OCR models are available. The architecture of OCR4all allows the easy integration (or substitution) of newly developed tools for its main components by standardized interfaces like PageXML, thus aiming at continual higher automation for historical printings.
State of the Art Optical Character Recognition of 19th Century Fraktur Scripts using Open Source Engines
Oct 08, 2018In this paper we evaluate Optical Character Recognition (OCR) of 19th century Fraktur scripts without book-specific training using mixed models, i.e. models trained to recognize a variety of fonts and typesets from previously unseen sources. We describe the training process leading to strong mixed OCR models and compare them to freely available models of the popular open source engines OCRopus and Tesseract as well as the commercial state of the art system ABBYY. For evaluation, we use a varied collection of unseen data from books, journals, and a dictionary from the 19th century. The experiments show that training mixed models with real data is superior to training with synthetic data and that the novel OCR engine Calamari outperforms the other engines considerably, on average reducing ABBYYs character error rate (CER) by over 70%, resulting in an average CER below 1%.
Calamari - A High-Performance Tensorflow-based Deep Learning Package for Optical Character Recognition
Aug 06, 2018
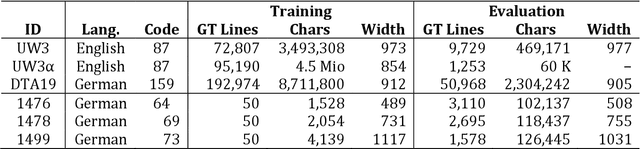

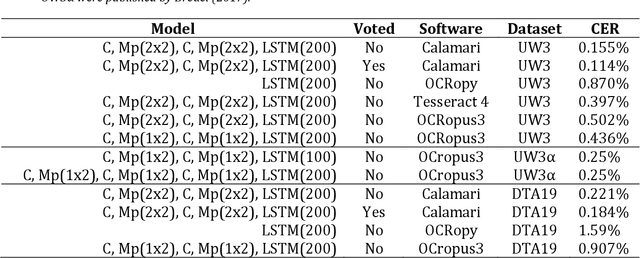
Optical Character Recognition (OCR) on contemporary and historical data is still in the focus of many researchers. Especially historical prints require book specific trained OCR models to achieve applicable results (Springmann and L\"udeling, 2016, Reul et al., 2017a). To reduce the human effort for manually annotating ground truth (GT) various techniques such as voting and pretraining have shown to be very efficient (Reul et al., 2018a, Reul et al., 2018b). Calamari is a new open source OCR line recognition software that both uses state-of-the art Deep Neural Networks (DNNs) implemented in Tensorflow and giving native support for techniques such as pretraining and voting. The customizable network architectures constructed of Convolutional Neural Networks (CNNS) and Long-ShortTerm-Memory (LSTM) layers are trained by the so-called Connectionist Temporal Classification (CTC) algorithm of Graves et al. (2006). Optional usage of a GPU drastically reduces the computation times for both training and prediction. We use two different datasets to compare the performance of Calamari to OCRopy, OCRopus3, and Tesseract 4. Calamari reaches a Character Error Rate (CER) of 0.11% on the UW3 dataset written in modern English and 0.18% on the DTA19 dataset written in German Fraktur, which considerably outperforms the results of the existing softwares.
Improving OCR Accuracy on Early Printed Books by combining Pretraining, Voting, and Active Learning
Feb 28, 2018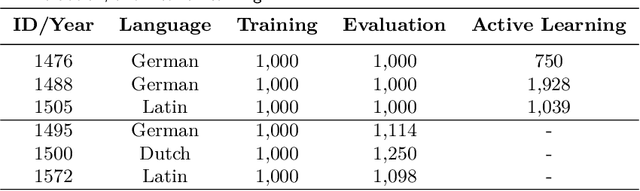

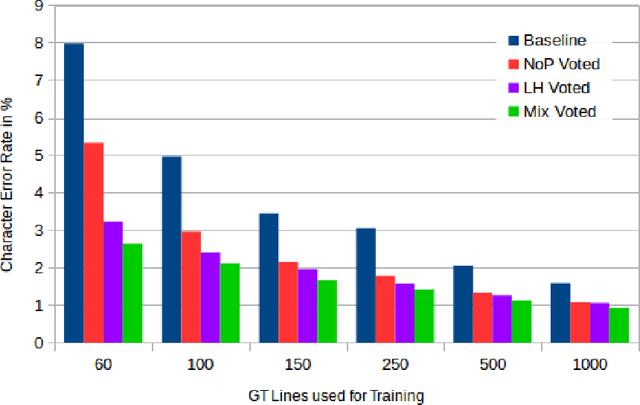
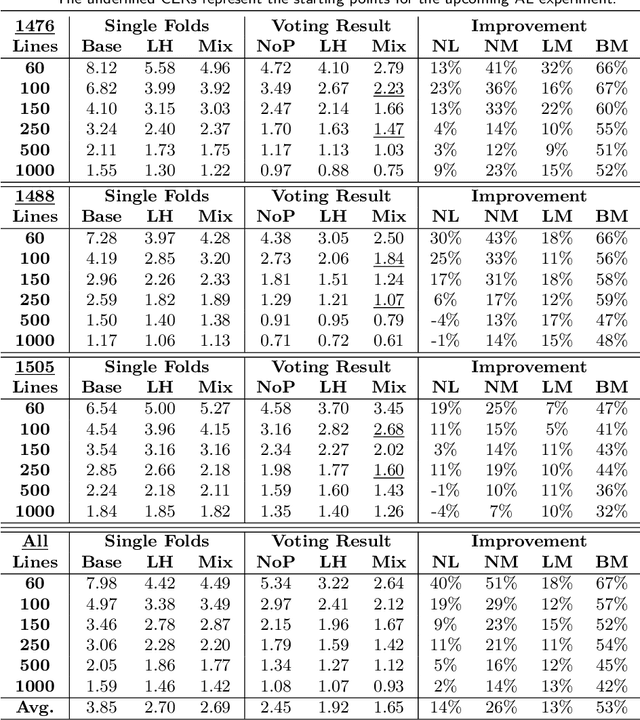
We combine three methods which significantly improve the OCR accuracy of OCR models trained on early printed books: (1) The pretraining method utilizes the information stored in already existing models trained on a variety of typesets (mixed models) instead of starting the training from scratch. (2) Performing cross fold training on a single set of ground truth data (line images and their transcriptions) with a single OCR engine (OCRopus) produces a committee whose members then vote for the best outcome by also taking the top-N alternatives and their intrinsic confidence values into account. (3) Following the principle of maximal disagreement we select additional training lines which the voters disagree most on, expecting them to offer the highest information gain for a subsequent training (active learning). Evaluations on six early printed books yielded the following results: On average the combination of pretraining and voting improved the character accuracy by 46% when training five folds starting from the same mixed model. This number rose to 53% when using different models for pretraining, underlining the importance of diverse voters. Incorporating active learning improved the obtained results by another 16% on average (evaluated on three of the six books). Overall, the proposed methods lead to an average error rate of 2.5% when training on only 60 lines. Using a substantial ground truth pool of 1,000 lines brought the error rate down even further to less than 1% on average.
Improving OCR Accuracy on Early Printed Books using Deep Convolutional Networks
Feb 27, 2018
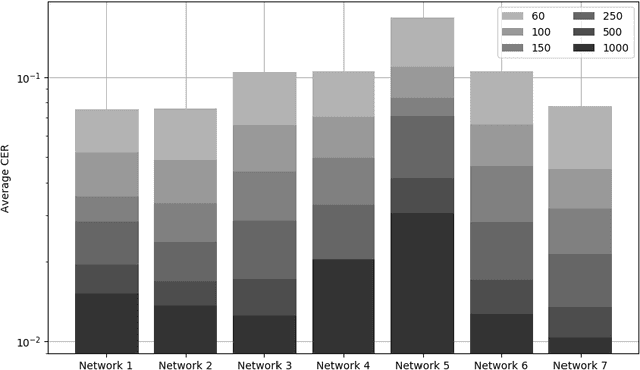


This paper proposes a combination of a convolutional and a LSTM network to improve the accuracy of OCR on early printed books. While the standard model of line based OCR uses a single LSTM layer, we utilize a CNN- and Pooling-Layer combination in advance of an LSTM layer. Due to the higher amount of trainable parameters the performance of the network relies on a high amount of training examples to unleash its power. Hereby, the error is reduced by a factor of up to 44%, yielding a CER of 1% and below. To further improve the results we use a voting mechanism to achieve character error rates (CER) below $0.5%$. The runtime of the deep model for training and prediction of a book behaves very similar to a shallow network.
Fully Convolutional Neural Networks for Page Segmentation of Historical Document Images
Feb 15, 2018


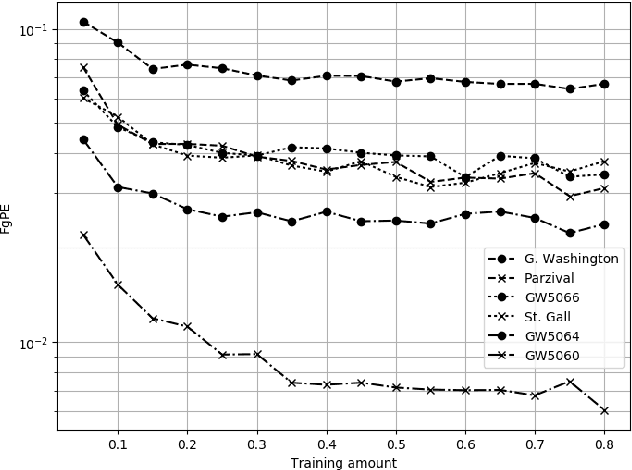
We propose a high-performance fully convolutional neural network (FCN) for historical document segmentation that is designed to process a single page in one step. The advantage of this model beside its speed is its ability to directly learn from raw pixels instead of using preprocessing steps e. g. feature computation or superpixel generation. We show that this network yields better results than existing methods on different public data sets. For evaluation of this model we introduce a novel metric that is independent of ambiguous ground truth called Foreground Pixel Accuracy (FgPA). This pixel based measure only counts foreground pixels in the binarized page, any background pixel is omitted. The major advantage of this metric is, that it enables researchers to compare different segmentation methods on their ability to successfully segment text or pictures and not on their ability to learn and possibly overfit the peculiarities of an ambiguous hand-made ground truth segmentation.
Transfer Learning for OCRopus Model Training on Early Printed Books
Dec 21, 2017

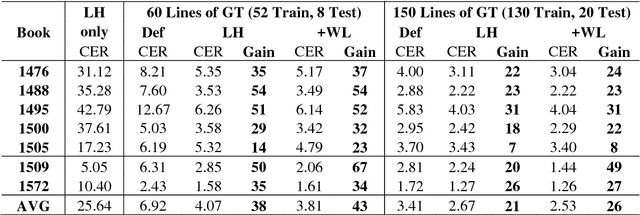
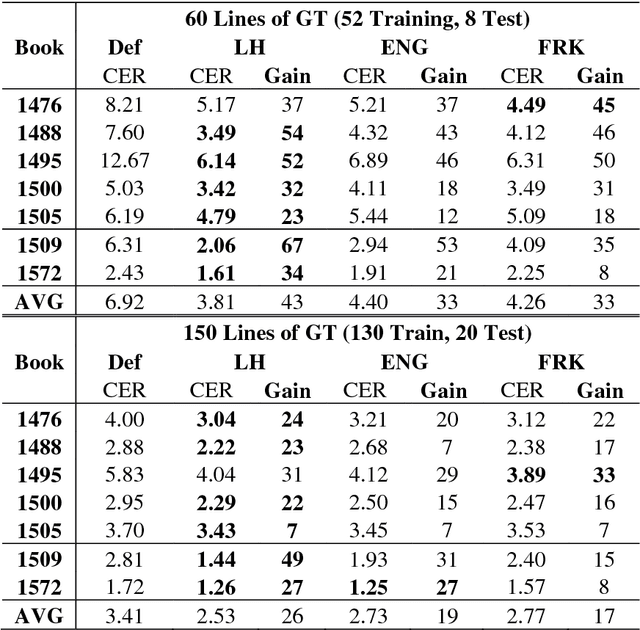
A method is presented that significantly reduces the character error rates for OCR text obtained from OCRopus models trained on early printed books when only small amounts of diplomatic transcriptions are available. This is achieved by building from already existing models during training instead of starting from scratch. To overcome the discrepancies between the set of characters of the pretrained model and the additional ground truth the OCRopus code is adapted to allow for alphabet expansion or reduction. The character set is now capable of flexibly adding and deleting characters from the pretrained alphabet when an existing model is loaded. For our experiments we use a self-trained mixed model on early Latin prints and the two standard OCRopus models on modern English and German Fraktur texts. The evaluation on seven early printed books showed that training from the Latin mixed model reduces the average amount of errors by 43% and 26%, respectively compared to training from scratch with 60 and 150 lines of ground truth, respectively. Furthermore, it is shown that even building from mixed models trained on data unrelated to the newly added training and test data can lead to significantly improved recognition results.