 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOptimizing small BERTs trained for German NER
Apr 23, 2021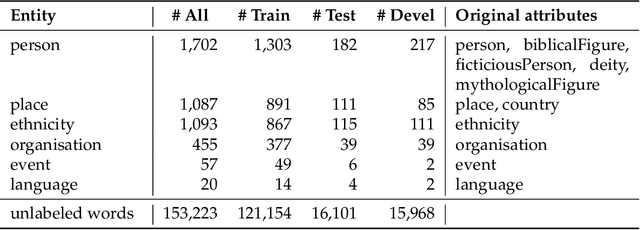
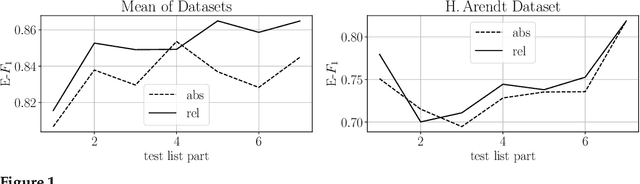
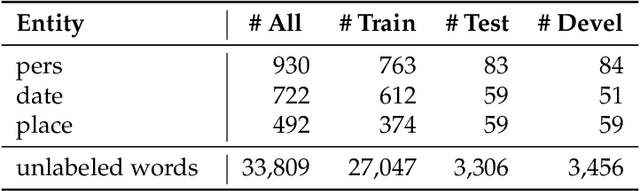

Currently, the most widespread neural network architecture for training language models is the so called BERT which led to improvements in various NLP tasks. In general, the larger the number of parameters in a BERT model, the better the results obtained in these NLP tasks. Unfortunately, the memory consumption and the training duration drastically increases with the size of these models, though. In this article, we investigate various training techniques of smaller BERT models and evaluate them on five public German NER tasks of which two are introduced by this article. We combine different methods from other BERT variants like ALBERT, RoBERTa, and relative positional encoding. In addition, we propose two new fine-tuning techniques leading to better performance: CSE-tagging and a modified form of LCRF. Furthermore, we introduce a new technique called WWA which reduces BERT memory usage and leads to a small increase in performance.