 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeZero-Shot Paragraph-level Handwriting Imitation with Latent Diffusion Models
Sep 01, 2024



The imitation of cursive handwriting is mainly limited to generating handwritten words or lines. Multiple synthetic outputs must be stitched together to create paragraphs or whole pages, whereby consistency and layout information are lost. To close this gap, we propose a method for imitating handwriting at the paragraph level that also works for unseen writing styles. Therefore, we introduce a modified latent diffusion model that enriches the encoder-decoder mechanism with specialized loss functions that explicitly preserve the style and content. We enhance the attention mechanism of the diffusion model with adaptive 2D positional encoding and the conditioning mechanism to work with two modalities simultaneously: a style image and the target text. This significantly improves the realism of the generated handwriting. Our approach sets a new benchmark in our comprehensive evaluation. It outperforms all existing imitation methods at both line and paragraph levels, considering combined style and content preservation.
Rescoring Sequence-to-Sequence Models for Text Line Recognition with CTC-Prefixes
Oct 13, 2021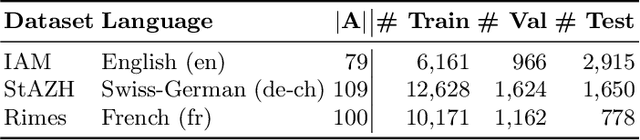

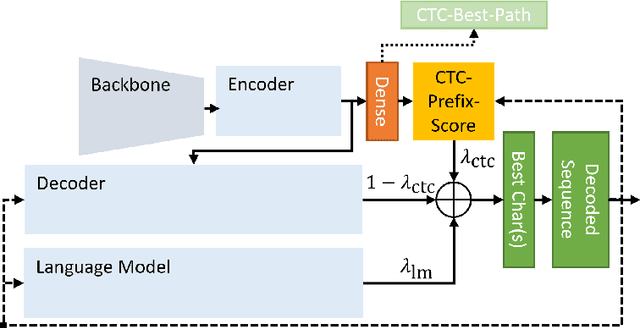

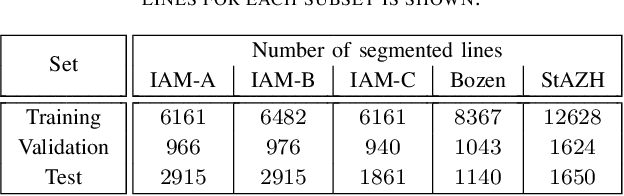
In contrast to Connectionist Temporal Classification (CTC) approaches, Sequence-To-Sequence (S2S) models for Handwritten Text Recognition (HTR) suffer from errors such as skipped or repeated words which often occur at the end of a sequence. In this paper, to combine the best of both approaches, we propose to use the CTC-Prefix-Score during S2S decoding. Hereby, during beam search, paths that are invalid according to the CTC confidence matrix are penalised. Our network architecture is composed of a Convolutional Neural Network (CNN) as visual backbone, bidirectional Long-Short-Term-Memory-Cells (LSTMs) as encoder, and a decoder which is a Transformer with inserted mutual attention layers. The CTC confidences are computed on the encoder while the Transformer is only used for character-wise S2S decoding. We evaluate this setup on three HTR data sets: IAM, Rimes, and StAZH. On IAM, we achieve a competitive Character Error Rate (CER) of 2.95% when pretraining our model on synthetic data and including a character-based language model for contemporary English. Compared to other state-of-the-art approaches, our model requires about 10-20 times less parameters. Access our shared implementations via this link to GitHub: https://github.com/Planet-AI-GmbH/tfaip-hybrid-ctc-s2s.
Optimizing small BERTs trained for German NER
Apr 23, 2021
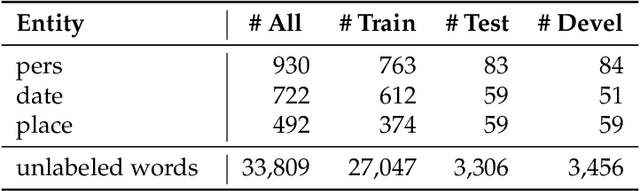

Currently, the most widespread neural network architecture for training language models is the so called BERT which led to improvements in various NLP tasks. In general, the larger the number of parameters in a BERT model, the better the results obtained in these NLP tasks. Unfortunately, the memory consumption and the training duration drastically increases with the size of these models, though. In this article, we investigate various training techniques of smaller BERT models and evaluate them on five public German NER tasks of which two are introduced by this article. We combine different methods from other BERT variants like ALBERT, RoBERTa, and relative positional encoding. In addition, we propose two new fine-tuning techniques leading to better performance: CSE-tagging and a modified form of LCRF. Furthermore, we introduce a new technique called WWA which reduces BERT memory usage and leads to a small increase in performance.
Evaluating Sequence-to-Sequence Models for Handwritten Text Recognition
Mar 18, 2019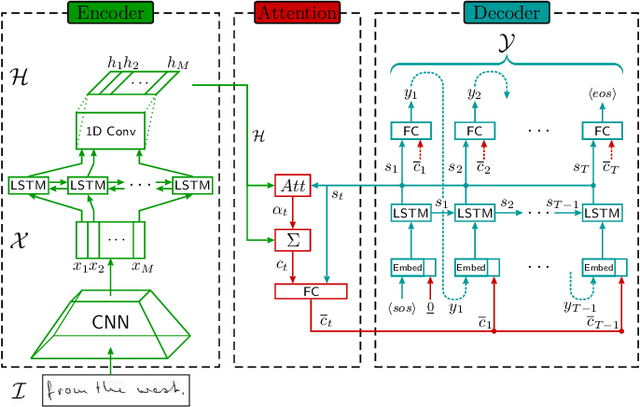

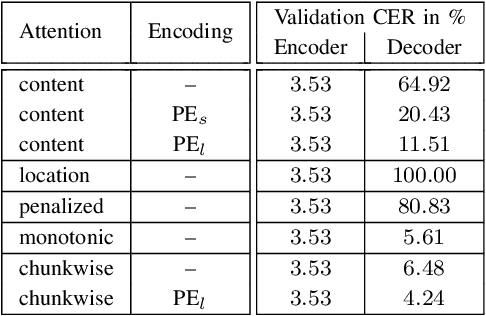
Encoder-decoder models have become an effective approach for sequence learning tasks like machine translation, image captioning and speech recognition, but have yet to show competitive results for handwritten text recognition. To this end, we propose an attention-based sequence-to-sequence model. It combines a convolutional neural network as a generic feature extractor with a recurrent neural network to encode both the visual information, as well as the temporal context between characters in the input image, and uses a separate recurrent neural network to decode the actual character sequence. We make experimental comparisons between various attention mechanisms and positional encodings, in order to find an appropriate alignment between the input and output sequence. The model can be trained end-to-end and the optional integration of a hybrid loss allows the encoder to retain an interpretable and usable output, e.g. for keyword spotting purposes without prior indexing, if desired. We achieve competitive results on the IAM and ICFHR2016 READ data sets compared to the state-of-the-art without the use of a language model, and we significantly improve over any recent sequence-to-sequence approaches.