 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeZero-Shot Paragraph-level Handwriting Imitation with Latent Diffusion Models
Sep 01, 2024



The imitation of cursive handwriting is mainly limited to generating handwritten words or lines. Multiple synthetic outputs must be stitched together to create paragraphs or whole pages, whereby consistency and layout information are lost. To close this gap, we propose a method for imitating handwriting at the paragraph level that also works for unseen writing styles. Therefore, we introduce a modified latent diffusion model that enriches the encoder-decoder mechanism with specialized loss functions that explicitly preserve the style and content. We enhance the attention mechanism of the diffusion model with adaptive 2D positional encoding and the conditioning mechanism to work with two modalities simultaneously: a style image and the target text. This significantly improves the realism of the generated handwriting. Our approach sets a new benchmark in our comprehensive evaluation. It outperforms all existing imitation methods at both line and paragraph levels, considering combined style and content preservation.
Combining OCR Models for Reading Early Modern Printed Books
May 11, 2023In this paper, we investigate the usage of fine-grained font recognition on OCR for books printed from the 15th to the 18th century. We used a newly created dataset for OCR of early printed books for which fonts are labeled with bounding boxes. We know not only the font group used for each character, but the locations of font changes as well. In books of this period, we frequently find font group changes mid-line or even mid-word that indicate changes in language. We consider 8 different font groups present in our corpus and investigate 13 different subsets: the whole dataset and text lines with a single font, multiple fonts, Roman fonts, Gothic fonts, and each of the considered fonts, respectively. We show that OCR performance is strongly impacted by font style and that selecting fine-tuned models with font group recognition has a very positive impact on the results. Moreover, we developed a system using local font group recognition in order to combine the output of multiple font recognition models, and show that while slower, this approach performs better not only on text lines composed of multiple fonts but on the ones containing a single font only as well.
Segmentation of the Carotid Lumen and Vessel Wall using Deep Learning and Location Priors
Jan 17, 2022
In this report we want to present our method and results for the Carotid Artery Vessel Wall Segmentation Challenge. We propose an image-based pipeline utilizing the U-Net architecture and location priors to solve the segmentation problem at hand.
View-Consistent Metal Segmentation in the Projection Domain for Metal Artifact Reduction in CBCT -- An Investigation of Potential Improvement
Dec 03, 2021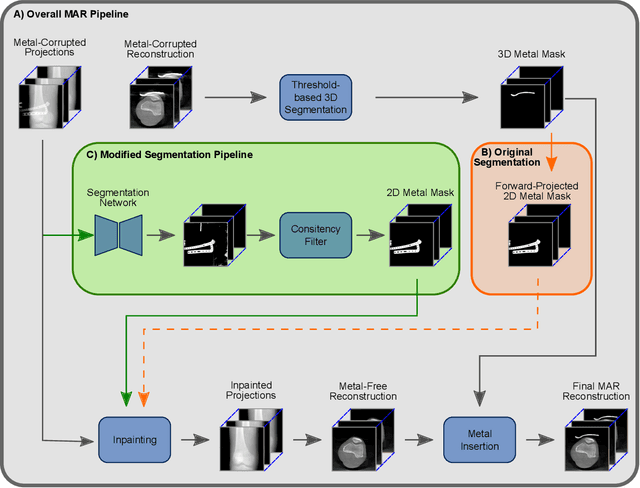
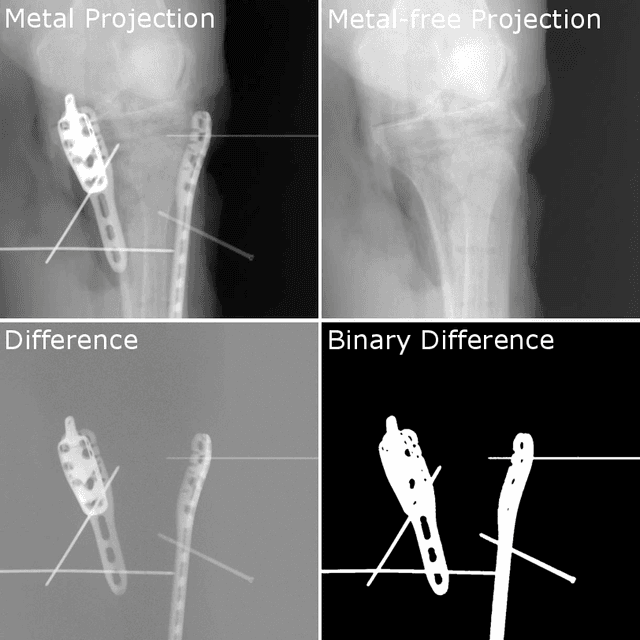
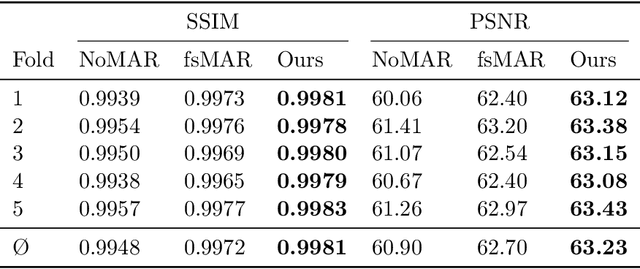
The positive outcome of a trauma intervention depends on an intraoperative evaluation of inserted metallic implants. Due to occurring metal artifacts, the quality of this evaluation heavily depends on the performance of so-called Metal Artifact Reduction methods (MAR). The majority of these MAR methods require prior segmentation of the inserted metal objects. Therefore, typically a rather simple thresholding-based segmentation method in the reconstructed 3D volume is applied, despite some major disadvantages. With this publication, the potential of shifting the segmentation task to a learning-based, view-consistent 2D projection-based method on the downstream MAR's outcome is investigated. For segmenting the present metal, a rather simple learning-based 2D projection-wise segmentation network that is trained using real data acquired during cadaver studies, is examined. To overcome the disadvantages that come along with a 2D projection-wise segmentation, a Consistency Filter is proposed. The influence of the shifted segmentation domain is investigated by comparing the results of the standard fsMAR with a modified fsMAR version using the new segmentation masks. With a quantitative and qualitative evaluation on real cadaver data, the investigated approach showed an increased MAR performance and a high insensitivity against metal artifacts. For cases with metal outside the reconstruction's FoV or cases with vanishing metal, a significant reduction in artifacts could be shown. Thus, increases of up to roughly 3 dB w.r.t. the mean PSNR metric over all slices and up to 9 dB for single slices were achieved. The shown results reveal a beneficial influence of the shift to a 2D-based segmentation method on real data for downstream use with a MAR method, like the fsMAR.
Automatic Plane Adjustment of Orthopedic Intra-operative Flat Panel Detector CT-Volumes
Sep 15, 2021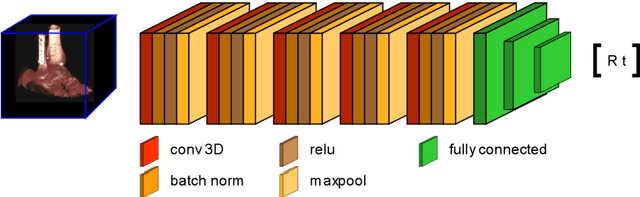


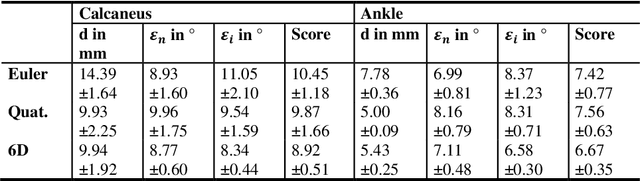
Purpose 3D acquisitions are often acquired to assess the result in orthopedic trauma surgery. With a mobile C-Arm system, these acquisitions can be performed intra-operatively. That reduces the number of required revision surgeries. However, due to the operation room setup, the acquisitions typically cannot be performed such that the acquired volumes are aligned to the anatomical regions. Thus, the multiplanar reconstructed (MPR) planes need to be adjusted manually during the review of the volume. In this paper, we present a detailed study of multi-task learning (MTL) regression networks to estimate the parameters of the MPR planes. Approach First, various mathematical descriptions for rotation, including Euler angle, quaternion, and matrix representation, are revised. Then, three different MTL network architectures based on the PoseNet are compared with a single task learning network. Results Using a matrix description rather than the Euler angle description, the accuracy of the regressed normals improves from $7.7^{\circ}$ to $7.3^{\circ}$ in the mean value for single anatomies. The multi-head approach improves the regression of the plane position from $7.4mm$ to $6.1mm$, while the orientation does not benefit from this approach. Conclusions The results show that a multi-head approach can lead to slightly better results than the individual tasks networks. The most important benefit of the MTL approach is that it is a single network for standard plane regression for all body regions with a reduced number of stored parameters.
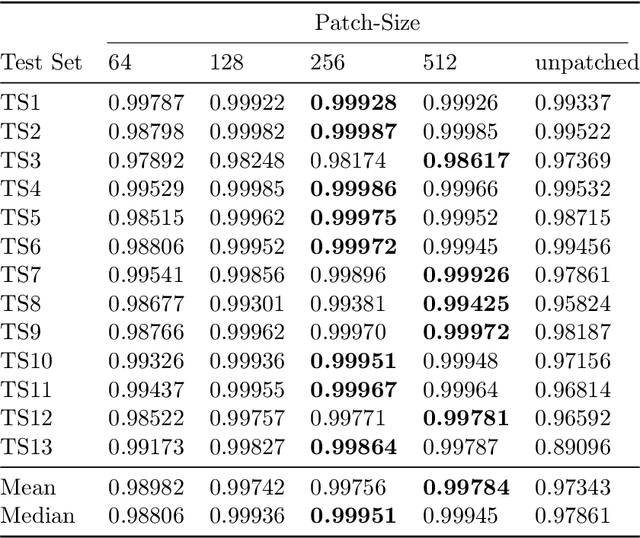
Learning-Based Patch-Wise Metal Segmentation with Consistency Check
Jan 26, 2021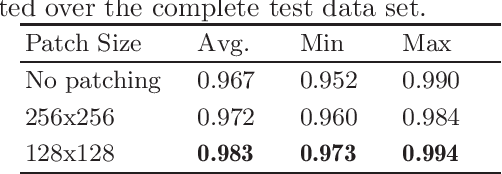

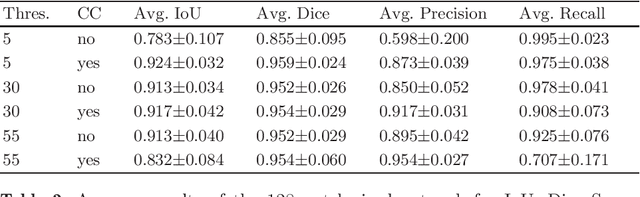
Metal implants that are inserted into the patient's body during trauma interventions cause heavy artifacts in 3D X-ray acquisitions. Metal Artifact Reduction (MAR) methods, whose first step is always a segmentation of the present metal objects, try to remove these artifacts. Thereby, the segmentation is a crucial task which has strong influence on the MAR's outcome. This study proposes and evaluates a learning-based patch-wise segmentation network and a newly proposed Consistency Check as post-processing step. The combination of the learned segmentation and Consistency Check reaches a high segmentation performance with an average IoU score of 0.924 on the test set. Furthermore, the Consistency Check proves the ability to significantly reduce false positive segmentations whilst simultaneously ensuring consistent segmentations.
Multi-task Localization and Segmentation for X-ray Guided Planning in Knee Surgery
Jul 24, 2019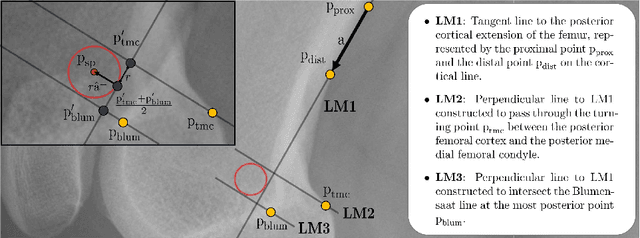


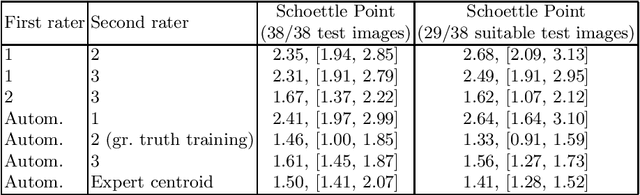
X-ray based measurement and guidance are commonly used tools in orthopaedic surgery to facilitate a minimally invasive workflow. Typically, a surgical planning is first performed using knowledge of bone morphology and anatomical landmarks. Information about bone location then serves as a prior for registration during overlay of the planning on intra-operative X-ray images. Performing these steps manually however is prone to intra-rater/inter-rater variability and increases task complexity for the surgeon. To remedy these issues, we propose an automatic framework for planning and subsequent overlay. We evaluate it on the example of femoral drill site planning for medial patellofemoral ligament reconstruction surgery. A deep multi-task stacked hourglass network is trained on 149 conventional lateral X-ray images to jointly localize two femoral landmarks, to predict a region of interest for the posterior femoral cortex tangent line, and to perform semantic segmentation of the femur, patella, tibia, and fibula with adaptive task complexity weighting. On 38 clinical test images the framework achieves a median localization error of 1.50 mm for the femoral drill site and mean IOU scores of 0.99, 0.97, 0.98, and 0.96 for the femur, patella, tibia, and fibula respectively. The demonstrated approach consistently performs surgical planning at expert-level precision without the need for manual correction.